de l´Information et
de la Communication pour
l´Éducation et la Formation
version à télécharger (pdf)
Volume 24, 2017
Article de recherche
Numéro Spécial
Sélection de la conférence
EIAH 2015
|
Contact : infos@sticef.org |
Analyse de connaissances perceptivo-gestuelles dans un Système Tutoriel Intelligent
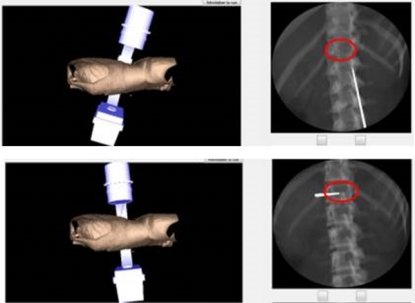
1. IntroductionLes connaissances perceptivo-gestuelles sont une combinaison de connaissances théoriques, de connaissances perceptuelles et de connaissances motrices liées aux gestes. Dans les systèmes tutoriels intelligents, ces connaissances s’expriment à travers les interactions de l’apprenant avec le système. Ces interactions se composent de perceptions accompagnant les actions et/ou les gestes exécutés. Les perceptions servent de contrôles pour la validation ou les décisions d’exécution de ces actions/gestes. Nous faisons l’hypothèse, dans notre travail, qu’elles fournissent des indications pertinentes sur les informations prises en compte dans les décisions de l’apprenant et de ce fait, ne sont pas négligeables du point de vue de l’analyse du processus d’apprentissage. Ces connaissances sont cependant empiriques et souvent tacites (Vadcard et al., 2009). Par conséquent, elles sont difficiles à capturer et à modéliser. En fait, la capture des connaissances perceptivo-gestuelles dans les environnements d’apprentissage simulés requiert l’exploitation de différents capteurs capables d’enregistrer les différentes modalités des interactions mises en jeu par l’apprenant. Ces capteurs sont des périphériques indépendants qui produisent des traces d’activités hétérogènes. Dans ce travail, nous nous intéressons à la définition d’une méthodologie pour la formalisation de ce type de traces dans l’objectif d’analyser les interactions multimodales de l’apprenant et les connaissances qu’elles sous-tendent. Notre cas d‘étude est TELEOS, un Système Tutoriel Intelligent orienté simulation, dédié à la chirurgie orthopédique percutanée (Luengo et al., 2011a). Les connaissances du domaine de la chirurgie percutanée sont perceptivo-gestuelles (Ceaux et al., 2009), (Mathews et al., 2012) : ce type d’opérations chirurgicales nécessite une coordination mentale entre les connaissances théoriques en anatomie, l’analyse de radiographies en 2D et la manipulation en 3D d’objets réels tels que le trocart et l’outil de radioscopie (fluoroscope), pour pouvoir assurer la trajectoire correcte des outils chirurgicaux vers la zone anatomique ciblée. Nous cherchons à mettre en lumière comment la prise en compte de ces différents aspects de l’activité chirurgicale est pertinente pour l’analyse de l’activité de l’apprenant. La suite de l’article est organisée comme suit : la section 2 présente un état de l’art sur les travaux adressant des domaines faisant intervenir des connaissances multimodales et des travaux exploitant les perceptions à des fins d’analyses de l’apprentissage ; dans la section 3 nous décrivons le domaine, le déroulement d’un type d’opération chirurgicale percutanée, la vertébroplastie, et le caractère perceptivo-gestuel de l’activité du chirurgien au cours de la réalisation de ce type d’opération ; dans la section 4, nous présentons la méthodologie utilisée pour capter les interactions de modalités différentes au cours des simulations de vertébroplastie sur TELEOS ; dans la section 5, nous faisons une présentation détaillée de notre approche pour l’identification d’interactions de différentes modalités liées à une même activité ; dans la section 6, nous soulignons l’importance de prendre en compte les réponses du système aux actions de l’apprenant ; dans la section 7, nous détaillons notre proposition de formalisation d’interactions multi-sources et hétérogènes en séquences perceptivo-gestuelles reflétant les différentes modalités de ces interactions ; nous présentons, dans la section 8, les expérimentations conduites dans le but d’évaluer cette proposition et nous concluons l’article dans la section 9. 2. Etat de l’artLa littérature rapporte beaucoup de travaux de recherche sur la conception de systèmes d’apprentissage dédiés à des domaines faisant intervenir des connaissances perceptivo-gestuelles. Nous pouvons citer les travaux réalisés par (Mulgund et al., 1995) sur le pilotage d’hélicoptères, par (Remolina et al., 2004) sur l’aviation et par (Weevers et al., 2003) et (de Winter et al., 2008) sur la conduite automobile. Plus récemment, le Système Tutoriel Intelligent CanadarmTutor a été proposé pour l’entrainement des astronautes de la Station Spatiale Internationale à la manipulation d’un bras articulé robotisé (Fournier-Viger et al., 2011). Cependant, l’emphase est portée, dans ces travaux, sur les actions et les gestes, et non sur les perceptions accompagnant ces derniers. Par exemple, dans CanadarmTutor, la manipulation du bras robotisé d’une configuration à une autre est guidée par des caméras dans différentes scènes d’opération. Les perceptions visuelles intervenant au cours de la manipulation du bras robotisé jouent probablement un rôle important dans le processus et, de ce fait, leur prise en compte dans l’analyse de l’activité de l’apprenant serait pertinente. D’autres travaux ont été conduits sur l’analyse des perceptions en contexte d’apprentissage. Par exemple, les perceptions visuelles sont capturées et analysées pour inférer les performances cognitives de l’apprenant (Steichen et al., 2013) ou pour inférer leurs capacités métacognitives en apprentissage exploratoire (Conati et Merten, 2007). D’autres chercheurs exploitent de préférence les informations perceptuelles collectées pour mesurer la charge mentale de l’apprenant ou leur effort cognitif en situation d’apprentissage (Lach, 2013) ou encore pour inférer leur comportement au cours du processus d’apprentissage (D’Mello et al., 2012), (Mathews et al., 2012). D’autres études font intervenir des capteurs permettant d’enregistrer les postures physiques, les expressions faciales et corporelles dans le but d’analyser des signaux émotionnels de l’apprenant (Ríos et al., 2000). Dans notre travail, nous faisons l’hypothèse que les prises d’informations perceptuelles peuvent dénoter, à l’instar des actions/gestes qu’elles accompagnent, l’état des connaissances de l’apprenant. De ce fait, nous pensons qu’elles doivent être analysées d’un point de vue épistémique. Spécifiquement, pour notre cas d’étude, les experts ont indiqué l’importance des vérifications de points anatomiques précis sur les radios pour accompagner la décision d’exécuter et de valider les gestes chirurgicaux (Ceaux et al., 2009). En d’autres termes, l’objectif de ce travail est de démontrer la pertinence d’analyser les connaissances perceptivo-gestuelles en considérant chacune de leurs caractéristiques multimodales. Nous décrivons dans la section suivante le déroulement d’un type d’opération orthopédique percutanée, la vertébroplastie, et soulignons les différentes modalités de l’activité du chirurgien au cours de cette opération. 3. La vertébroplastie : une opération chirurgicale percutanée3.1. Déroulement d’une opération de vertébroplastieLa vertébroplastie est une opération chirurgicale mini-invasive réalisée pour traiter les fractures des vertèbres par l’injection d’un ciment osseux dans les vertèbres affectées, grâce à un outil d’insertion (le trocart). Cette opération est dite mini-invasive, car effectuée à travers la peau du patient, contrairement aux opérations classiques nécessitant une ouverture. De ce fait, le chirurgien ne dispose pas d’une visibilité directe de la progression de ses outils à travers le corps du patient. Le guidage s’effectue dans ce type d’opération par le biais d’imageries médicales (scanner ou radiographies) qui renvoient au chirurgien les informations sur la trajectoire de ses outils. En vertébroplastie, les images médicales utilisées sont des radiographies générées tout au long de l’opération grâce à un fluoroscope. Une opération de vertébroplastie se réalise en trois grandes phases : - la phase de réglages du fluoroscope, - la phase de repérage cutané, - la phase d’insertion du trocart. La phase de réglages sert à chercher le positionnement du fluoroscope optimisant la qualité des radiographies (de face et de profil) qui vont guider le chirurgien tout au long de l’opération. La phase de repérage cutané consiste à dessiner, sur la peau du patient, les lignes définissant le repère d’insertion adéquat du trocart. Enfin la phase d’insertion est celle où le trocart est manipulé de manière à atteindre la zone anatomique affectée pour y injecter le ciment osseux. 3.2. Le caractère multimodal d’une opération de vertébroplastieL’interprétation des radiographies à des fins de guidage est une habileté cognitive qui requiert la coordination de la représentation en 2D renvoyée par les radiographies, avec la représentation en 3D dans le monde réel. De manière plus précise, la position d’un instrument chirurgical, relativement à l’environnement anatomique sur sa trajectoire, se conçoit sur trois dimensions. Par exemple, le positionnement complet du trocart est fourni par la combinaison de son positionnement sur l’axe antérieur (la profondeur d’insertion du trocart dans le corps du patient), son positionnement sur l’axe transversal (la position de la pointe de l’outil relativement aux limites droite et gauche du corps du patient) et son positionnement sur l’axe longitudinal (la position de la pointe de l’outil relativement à l’axe défini par la tête et les membres inférieurs du patient). Cependant, les radiographies de guidage ne peuvent fournir qu’une représentation sur deux dimensions du positionnement de l’outil : les radiographies de face indiquent le positionnement sur l’axe transversal et l’axe longitudinal, et les radiographies de profil, sur les axes antéro-postérieur et longitudinal. Le positionnement réel de l’outil tout au long de sa trajectoire percutanée ne peut donc se faire que par le couplage d’au moins deux radiographies, soit au moins une radiographie fournissant une vue du point d’entrée du trocart (radiographie de face) et une radiographie fournissant une vue du point de progression du trocart (radiographie de profil) (cf. Figure 1).
Figure 1 • Vue « point d’entrée » (radiographie de face) et vue « progression » (radiographie de profil) du trocart Ainsi, le chirurgien valide ses gestes et ses actions sur la base des contrôles visuels de ces radiographies. Ce travail de validation s’effectue par l’analyse du positionnement de l’outil vis-à-vis de certains points anatomiques précis du patient. De ce fait, les perceptions visuelles constituent une facette de l’ensemble des connaissances à maîtriser par le chirurgien. Les connaissances mises en jeu pour la réalisation du geste chirurgical percutané comprennent une autre facette perceptuelle : les perceptions haptiques ressenties sur la trajectoire de l’outil chirurgical dans le corps du patient. Ces perceptions sont les résistances perçues par le chirurgien au contact de son outil avec les différentes parties de la zone anatomique traversée sur sa trajectoire d’insertion. Ces perceptions renvoient des informations sur la progression de l’outil sur la base desquelles le chirurgien adapte aussi son geste, en complément des informations visuelles recueillies à travers les radiographies. Dans la section suivante, nous présentons la méthodologie utilisée pour capturer chacune des modalités des interactions de l’apprenant au cours des simulations de vertébroplastie dans l’environnement d’apprentissage TELEOS. 4. Capture de traces multimodales dans TELEOSPour pouvoir capter les différentes facettes des interactions mises en jeu au cours d’une simulation de vertébroplastie, deux périphériques sont utilisés en complément de l’interface de simulation qui enregistre les actions ponctuelles de l’apprenant. Il s’agit d’un oculomètre pour tracer le comportement visuel de l’apprenant et d’un bras à retour d’effort pour capter les gestes effectués et les retours haptiques reçus par l’apprenant. 4.1. Les actions ponctuellesLe simulateur enregistre des traces de manière ponctuelle à l’exécution d’une action. Il s’agit des actions liées aux réglages du fluoroscope, au tracé des repères cutanés et à la manipulation du trocart. Le tableau 1 présente un résumé des actions ponctuelles pouvant être exécutées à partir de l’interface du simulateur. Chaque action est traitée comme une photographie de l’environnement de simulation au moment de son exécution. En effet, à chaque occurrence d’une action du simulateur, les coordonnées des positions des différents outils de l’environnement sont enregistrées. De ce fait, une action est caractérisée non seulement par son nom, mais aussi par les positions des outils de l’environnement de simulation au même moment. Tableau 1 • Actions ponctuelles enregistrées à partir de l’interface de simulation
Par exemple, tel qu’illustré dans la Figure 2, deux prises de radio de face seront différentes si le positionnement du fluoroscope a changé entre les deux exécutions.
Figure 2 • Radiographies de face d’après deux inclinaisons différentes du fluoroscope Chaque action est représentée par une séquence contenant les paramètres suivants : - un code temporel, - le nom de l’action, - les coordonnées (x, y, z) du modèle 3D du patient, - les coordonnées (x, y, z) de la position du fluoroscope en mode face, - les coordonnées (x, y, z) de la position du fluoroscope en mode profil, - les coordonnées (x, y) de l’affichage de la dernière radiographie prise, - les coordonnées (x, y) de l’affichage de la radiographie précédente, - les coordonnées (x, y, z) de la position du fluoroscope, - les coordonnées (x, y, z) de la position de la pointe du trocart, - les coordonnées (x, y, z) de la position de la poignée du trocart, - les coordonnées (x, y, z) (x’, y’, z’) de l’orientation du trocart, - les coordonnées (x, y), (x’, y’), (x”, y”) des 3 repères cutanés. 4.2. Les gestes et perceptions haptiquesLe geste chirurgical inclut les types de préhension des outils chirurgicaux, les niveaux de forces appliquées selon l’étape de progression et les inclinaisons, l’orientation et la direction d’insertion des outils (Luengo et al., 2011b). Le recueil des données nécessaires à la modélisation des gestes chirurgicaux pour la vertébroplastie a été réalisé sur des maquettes de patients. L’instrumentation nécessaire (cf. Figure 4) inclut notamment des dynamomètres positionnés dans les maquettes pour pouvoir recueillir les données relatives aux niveaux de force appliqués sur le trocart et à la vitesse de progression de celui-ci à des points de progression importants. Les principaux points de progression considérés pour une vertébroplastie sont le contact cutané, le contact osseux, l’entrée pédiculaire, la traversée du corps vertébral jusqu’au point de validation de la trajectoire du trocart. La configuration du bras haptique a été réalisée sur la base de ces données. Le matériel utilisé dans l’environnement TELEOS est un Sensable Phantom Omni qui fournit six degrés de liberté avec un retour d’effort sur les trois axes de translation – cf. Figure 3 (iii). Les résistances configurables sur cet appareil sont relativement faibles, mais suffisantes pour simuler des variations de densité du corps humain et des vertèbres sur la trajectoire des outils chirurgicaux (Luengo et al., 2011a). Les traces provenant de cet appareil sont enregistrées en continu toutes les 100 millisecondes. Chaque trace contient les paramètres suivants : - un code temporel, - les coordonnées (x, y, z) de la position de la pointe du trocart, - les coordonnées (x, y, z) de la position du manche du trocart, - les coordonnées (x, y, z) (x’, y’, z’) de l’orientation du trocart, - la vitesse de manipulation du trocart, - la force appliquée sur le trocart. Les paramètres d’orientation, de vitesse et de force sont les résultats d’un traitement préliminaire des traces haptiques (Luengo et al., 2011a).
Figure 3 • (i), (ii) Instrumentations pour le recueil des données gestuelles et haptiques relatives à la manipulation du trocart. (iii) Bras haptique et dispositif matériel dans l’environnement de simulation 4.3. Les perceptions visuellesL’interface de simulation est divisée en plusieurs zones d’intérêt (cf. Figure 4) : la zone d’affichage du modèle 3D du patient ; les zones d’affichage des radiographies précédentes et courantes ; le tableau de réglages principal. Ce dernier comprend trois sous-sections : le tableau de réglages de l’appareil de radioscopie ou fluoroscope, le tableau de manipulation de la réglette pour le marquage de repères cutanés destinés à cibler l’os affecté, le tableau de manipulation de l’outil de guidage des instruments chirurgicaux ou trocart.
Figure 4 • L’interface du simulateur TELEOS
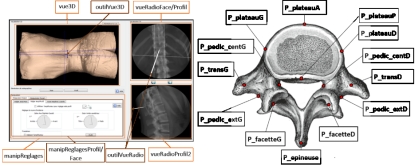
Figure 5 • Identification et annotation des points d’intérêt des vertèbres
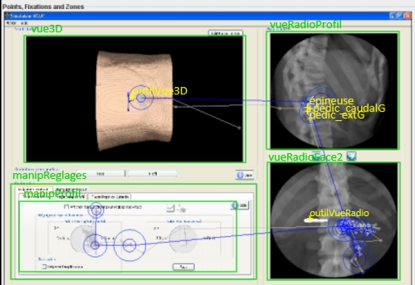
Figure 6 • Codes des zones et points d’intérêt enregistrés au cours des simulations de vertébroplastie La zone d’intérêt associée à l’affichage de la radiographie courante comporte plusieurs points d’intérêt devant être pris en compte sur la vertèbre pour la validation de la trajectoire d’insertion du trocart. Les points d’intérêt de la vertèbre cible ont été désignés par un chirurgien expert pour chaque cas clinique modélisé et intégré dans la base d’exercices du simulateur. Tel qu’illustré dans la Figure 5, leur identification est effectuée à partir des coupes en deux dimensions du scanner de la colonne vertébrale du patient. Les coordonnées de ces points sont enregistrées dans les métadonnées du cas clinique. Lorsque celui-ci est sélectionné comme exercice, les points enregistrés sont projetés sur les radiographies produites par l’apprenant. Les zones et points d’intérêt de l’interface et de la vertèbre sont illustrés dans la Figure 6. Un outil d’analyse des perceptions visuelles intégré au simulateur permet d’analyser le parcours visuel de l’apprenant (Jambon et Luengo, 2012). Il enregistre les coordonnées des perceptions, les zones et points d’intérêt visualisés ainsi que la durée des visualisations. La Figure 7 illustre un parcours visuel (traces en bleu) à travers certaines zones d’intérêt de l’interface et certains points d’intérêt à l’intérieur de ces zones. Dans cet exemple, le chirurgien débute son exploration de l’interface en visualisant la position du trocart dans la zone 3D (en haut à gauche), puis parcourt certains repères anatomiques sur la dernière radiographie de profil effectuée (en haut à droite). Il s’intéresse ensuite aux repères anatomiques affichés sur la précédente radiographie de face (en bas à droite). Enfin, il termine son parcours visuel par la zone de réglage du fluoroscope (en bas à gauche) avant d’y exécuter la prochaine action.
Figure 7 • Zones (en vert) et points (en jaune) d’intérêt de l’interface et parcours visuel de l’apprenant sous forme de données brutes (en gris) et perceptions (en bleu) Pour chaque trace de l’oculomètre, les enregistrements rapportent les paramètres suivants : - un code temporel, - le nom de la zone et/ou des points d’intérêt fixés, - les coordonnées (x, y) de la perception, - le rayon de la perception, 4.4. Hétérogénéité des tracesChaque source enregistrant les interactions de l’apprenant séparément et indépendamment des autres périphériques, l’ensemble des traces obtenues est hétérogène. Cette hétérogénéité se retrouve à plusieurs niveaux. Tout d’abord, les traces sont hétérogènes au niveau du type de leur contenu : les traces envoyées par l’interface du simulateur et les traces de l’oculomètre sont alphanumériques alors que celles envoyées par le bras haptique sont numériques. Elles sont aussi hétérogènes au niveau du format de leur contenu. En effet, chaque trace du logiciel de simulation compte 54 paramètres, celles provenant du bras haptique comptent 15 paramètres et celles provenant de l’oculomètre, 7 paramètres distincts. Enfin, les traces des différentes sources se distinguent au niveau de leur granularité temporelle. Les traces oculométriques sont envoyées et enregistrées en continu toutes les 30 millisecondes ; celles du bras haptique sont aussi envoyées et enregistrées en continu, mais à un intervalle de 100 millisecondes, tandis que celles du simulateur sont discrètes : elles sont produites et enregistrées de manière ponctuelle à l’exécution d’une action. Le principal verrou technique à soulever à ce niveau est de fusionner ces traces de manière à les représenter sous forme de séquences cohérentes. Il s’agit de lier chaque action ou geste aux perceptions qui ont accompagné son exécution. Le verrou scientifique connexe consistera à valider la cohérence de cette représentation relativement à la connaissance multimodale qu’elle est censée traduire. 5. Jonction entre actions, gestes et perceptionsLe premier défi de la représentation des traces consiste à identifier les traces de chaque source représentant un aspect de la même interaction. En d’autres termes, il faut parvenir à relier actions, perceptions et gestes exécutés dans le but d’atteindre un même objectif. Pour illustrer par un exemple simple en chirurgie orthopédique percutanée, une prise de radiographie de profil, jointe à la perception de la position de l’épineuse de la vertèbre affectée et à une inclinaison puis un déplacement du trocart sur l’axe postéro-antérieur, permet d’inférer un élément de connaissance relatif au démarrage de la trajectoire d’insertion du trocart. Nous faisons l’hypothèse que les perceptions visuelles sont exploitées comme support pour valider ou vérifier l’exécution d’une action ou la réalisation d’un geste, et que les perceptions haptiques sont exploitées comme support d’adaptation du geste. Il existe, de ce point de vue, plusieurs combinaisons possibles entre les différentes modalités de l’interaction. Nous distinguons ainsi des interactions perceptivo-gestuelles de type « contrôle a priori », « contrôle a posteriori » ou « mixte ». 5.1. Interaction perceptivo-gestuelle de type « contrôle a priori »Une interaction perceptivo-gestuelle de type contrôle a priori fait référence à une interaction multimodale plaçant les contrôles perceptuels avant les actions ou les gestes. Pour illustrer par un exemple simple en chirurgie, le chirurgien vérifie le positionnement du trocart sur les radiographies de face et de profil avant d’amener l’outil au contact de la vertèbre ciblée. Dans ce cas de figure, l’interaction perceptivo-gestuelle est représentée par des items de modalités perceptuelles suivis des items d’action ou de geste. Ce type de perception peut être relatif à une validation avant une action. 5.2. Interaction perceptivo-gestuelle de type « contrôle a posteriori »Une interaction perceptivo-gestuelle est de type « contrôle a posteriori » lorsque les items de modalités perceptuelles se placent après les actions et les gestes. En d’autres termes, les prises d’informations perceptuelles sont réalisées systématiquement après l’exécution des actions et gestes qu’elles accompagnent. Par exemple, une interaction perceptivo-gestuelle de type « contrôle a posteriori » est observée si le chirurgien insère le trocart puis vérifie son positionnement par rapport à la trajectoire prévue sur les radiographies. 5.3. Interaction perceptivo-gestuelle de type « mixte »Une interaction perceptivo-gestuelle de type mixte désigne une interaction où les occurrences des items de différentes modalités sont simultanées. Il s’agit d’une interaction au cours de laquelle les prises d’informations perceptuelles s’effectuent dans le continuum d’un même geste ou en même temps qu’une action. Pour reprendre notre exemple, il s’agirait pour le chirurgien de procéder à une manipulation continue du trocart tout en vérifiant sa progression sur les radiographies prises. 5.4. Différenciation des perceptionsToutes les perceptions ne sous-tendent pas les mêmes objectifs et ne mobilisent pas les mêmes ressources cognitives de l’apprenant. En chirurgie orthopédique percutanée, les perceptions visuelles requièrent du chirurgien la capacité mentale à coordonner les images radio en deux dimensions pour pouvoir se représenter de manière précise la position de ses outils par rapport aux zones anatomiques traversées. Pour leur part, les perceptions haptiques donnent une information moins précise sur la position des outils, mais moins difficile à interpréter quant à la texture de la région anatomique traversée par les outils. Certaines perceptions visent une analyse précise de l’environnement alors que d’autres visent simplement une prise d’informations sur l’état de l’environnement. Par exemple, la visualisation de certains points précis d’une vertèbre sur une radio peut révéler une analyse de la validité du point d’insertion du trocart alors qu’une pression sur l’outil peut constituer une simple sollicitation d’un retour haptique dont le but est d’informer le chirurgien sur la rigidité de la zone anatomique traversée. Dans le cadre de ce travail, nous nous intéressons spécifiquement à la distinction des perceptions visuelles, sous l’hypothèse qu’elles permettent d’inférer avec plus de précision les intentions de l’apprenant ou, d’une manière générale, sa stratégie. Nous proposons de concevoir cette distinction sous deux grandes catégories : les perceptions visuelles de contrôle et les perceptions d’exploration. 5.4.1. Les perceptions visuelles de contrôleLes perceptions visuelles de contrôle sous-tendent une activité cognitive dont le but est d’analyser l’environnement en mobilisant des connaissances précises. Cela rejoint le concept de contrôle du modèle cK¢ (Balacheff, 2013) en l’adaptant aux connaissances perceptivo-gestuelles. Au-delà d’une simple prise d’information visuelle, leur rôle est d’évaluer les actions exécutées. Par exemple, en vertébroplastie, la vérification du positionnement de l’épineuse pour décider du centrage de la vertèbre ciblée repose sur des perceptions de contrôle. En aviation, la lecture des indicateurs d’altitude, de variation d’altitude et de puissance du moteur au cours de la préparation à l’atterrissage repose aussi sur des perceptions de contrôle. Ces perceptions ciblent les points précis de l’environnement qui rendent compte des conséquences des actions ou gestes exécutés et donc des connaissances relatives à ces actions ou gestes. 5.4.2. Les perceptions visuelles d’explorationLes perceptions visuelles dites d’exploration se limitent à une prise d’information sur l’état de l’environnement sans rapport aux connaissances (ici, perceptivo-gestuelles), mais plutôt relatives à la compréhension de l’environnement dans lequel les actions et gestes seront réalisés. Elles sont traduites par des visualisations moins précises que les perceptions de contrôle. Elles ciblent les éléments de l’environnement permettant d’agir sur celui-ci, c’est-à-dire les éléments de l’interface liés à l’exécution des actions telle que la manette de manipulation de l’outil de radioscopie en chirurgie percutanée. Par exemple, dans l’interface de TELEOS (cf. Figure 7), la visualisation dans la zone de réglage du fluoroscope (en bas à gauche) permet d’explorer le rapport entre ces outils de l’interface et le positionnement du fluoroscope. 6. Les « interactions » du systèmeNous désignons par interactions du système les interactions ne venant pas directement de l’activité de l’apprenant sur l’interface, mais ayant un rapport direct avec celle-ci. En d’autres termes, il s’agit des réactions du système aux actions de l’apprenant. Pour illustrer, prenons l’exemple d’un STI où l’apprenant peut solliciter l’aide du système au cours de la résolution d’un problème. Il peut être pertinent de considérer le contenu et la forme de l’aide envoyée, dans la mesure où la façon dont ces réactions sont prises en compte et exploitées dans l’apprentissage peut avoir une forte corrélation avec les performances de l’apprenant (Paquette et al., 2012). Dans notre cas d’étude, les interactions système considérées sont l’état de la simulation et les résultats du diagnostic de l’apprenant. 6.1. L’état de la simulationL’état de la simulation désigne spécifiquement les positionnements de tous les artefacts de l’environnement de simulation à l’exécution d’une action (Guéraud et al., 1999). Il rend compte de la manière dont l’exécution d’une action affecte l’environnement. Avant l’exécution d’une action, l’état de la simulation est une information exploitée par l’apprenant pour prendre sa décision ; après l’exécution de l’action, l’état de la simulation traduit les conséquences de celle-ci sur l’environnement. L’objectif est non seulement de tracer les conséquences des actions de l’apprenant sur l’environnement d’apprentissage, mais aussi la manière dont cette action a été exécutée. Cette information peut être discrète (par ex. : « Le trocart a une inclinaison caudale »), ou continue (par ex. : « Le trocart est incliné rapidement dans l’axe céphalo-caudal »). L’état de la simulation n’est pas directement tracé par le système, mais résulte d’un traitement dont l’objectif est d’effectuer une « photographie » de l’environnement d’apprentissage à la suite d’interactions directes de l’apprenant. La prise en compte de l’état de la simulation dans les séquences vise à rendre compte de l’ensemble des informations qui sous-tendent les décisions de l’apprenant. Partant du principe que ces décisions ne sont pas restreintes par une marche à suivre prédéfinie, par exemple avec des règles de production, nous faisons l’hypothèse que l’état de la simulation apporte des précisions supplémentaires non négligeables dans l’analyse de l’activité de l’apprenant. 6.2. Evaluation de l’activité de l’apprenantNous voulons procéder à des traitements automatiques sur les séquences d’interactions des apprenants en prenant en compte des évaluations de leur activité produites à partir de règles expertes (Amershi et Conati, 2007), (Beck, 2007). Les évaluations à partir de règles expertes considérées dans ce travail sont appelées des « variables de situation » calculées par le module « modèle de l’apprenant » (Chieu et al., 2010). Nous considérons les variables de situation comme des interactions du système, car elles constituent des réactions du simulateur directement liées à l’activité de l’apprenant. À titre d’illustration, les évaluations d’une radiographie prise par l’apprenant peuvent être les suivantes : « Le centrage de la vertèbre sur la radiographie de face est correcte. La visibilité des disques vertébraux sur la radiographie de face est incorrecte ». Ces évaluations sont directement liées au positionnement du fluoroscope choisi par l’apprenant pour générer les radiographies qui vont le guider au cours de l’opération. 7. Formalisation des séquences perceptivo-gestuellesNous décrivons ci-dessous la représentation conceptuelle proposée pour les séquences perceptivo-gestuelles sur la base des caractéristiques décrites dans les sections 5 et 6. Nous faisons une distinction entre séquences perceptivo-gestuelles et séquences perceptivo-gestuelles enrichies. Les séquences perceptivo-gestuelles représentent les interactions impliquant des actions et/ou des gestes et les perceptions accompagnant ceux-ci. Les séquences perceptivo-gestuelles enrichies comportent, en complément des actions/gestes et perceptions, des informations sur l’état de la simulation et des informations sur les évaluations de l’activité de l’apprenant (voir section 6 « Les interactions du système »). 7.1. Séquences perceptivo-gestuellesDéfinition 1 (séquence perceptivo-gestuelle). Une séquence perceptivo-gestuelle est une liste d’itemsets S, telle que : S : < A Avec : - A : les actions enregistrées dans la séquence ; - G : les gestes enregistrés dans la séquence ; - - - - P : les perceptions accompagnant les actions et gestes ; - Un itemset est un ensemble d’items cooccurrents (Agrawal et Srikant, 1994). Dans notre représentation d’une séquence perceptivo-gestuelle, les points-virgules délimitent les itemsets sur la base de leurs occurrences. « A | G » (A ou G) indique qu’une séquence perceptivo-gestuelle inclut des items d’actions ponctuelles ou de gestes. La Figure 8 illustre par un exemple la représentation d’une
séquence perceptivo-gestuelle. Cette séquence rapporte
l’exécution de l’action « Impacter_trocart ». Celle-ci traduit l’action
du chirurgien d’amener le trocart au contact de la vertèbre au
niveau du point d’entrée ciblé. Dans cet exemple, seule
l’action ponctuelle (A) est prise en compte, et non ses paramètres
( Le geste rapporté dans la séquence informe que le trocart a été enfoncé (trocart_translation_antérieure), avec un déplacement vers le côté droit du patient (trocart_translation_droite), dans la direction de ses membres inférieurs (trocart_translation_caudale). Les parenthèses indiquent que ces trois items sont co-occurrents. Dans notre cas d’étude, les gestes sont déduits de la variation des coordonnées du bras haptique traduite selon le système de référence en anatomie (Toussaint et al., 2015b). Les paramètres des perceptions visuelles rapportent les zones d’intérêt de l’interface qui ont été analysées. Par exemple, O_outil_vue3D fait référence à une vérification du positionnement du trocart sur le modèle en 3 dimensions du patient et O_manipReglage_1, à une visualisation du panel de réglage du fluoroscope. Le suffixe « _1 » précise que la visualisation de cette zone a duré moins de 1 000 millisecondes.
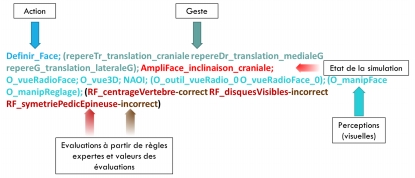
Figure 8 • Représentation d’une séquence perceptivo-gestuelle 7.2. Séquences perceptivo-gestuelles enrichiesDéfinition 2 (séquence perceptivo-gestuelle enrichie). Une séquence perceptivo-gestuelle enrichie est une liste Se de séquences, telle que : Se: < (Si ; Ʈi) ; (Ѵq(υr))> Avec : - Si : les séquences perceptivo-gestuelles composant la séquence enrichie ; - Ʈj : les états de la simulation enregistrés dans Si ; - Ѵq : des variables d’évaluation à partir de règles expertes ou « variables de situation » évaluant les séquences Si ; - υr: les valeurs des variables d’évaluation. La Figure 9 illustre la représentation formelle décrite dans la Définition 2, par un exemple de notre cas d’étude.
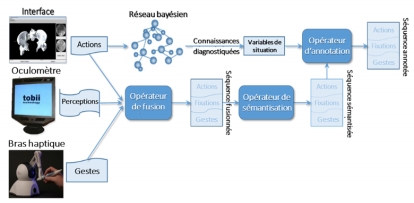
Figure 9 • Représentation d’une séquence perceptivo-gestuelle enrichie La séquence illustrée ci-dessus représente une action de prise de radio de face suivie par le traçage des repères cutanés. Pour rappel, les repères cutanés servent à marquer le point d’entrée du trocart sur la peau du patient. L’item sur l’état de la simulation, AmpliFace_inclinaison_craniale, précise que l’appareil de radioscopie est incliné vers la tête du patient. Les états de la simulation sont déduits de la sémantisation des paramètres des actions ponctuelles. En effet, lorsqu’une action ponctuelle, telle que « Definir_Face » est exécutée, le simulateur prend une « photographie » de l’interface de simulation. En d’autres mots, le simulateur capte les coordonnées de tous les outils de l’interface au moment de l’exécution de l’action et les enregistre, dans les traces brutes, comme les paramètres de cette action. Ensuite, ces traces sont analysées pour donner du sens vis-à-vis du problème. Enfin, les évaluations contenues dans chaque séquence perceptivo-gestuelle enrichie indiquent la conformité de cette action au regard d’un ensemble de règles expertes. Dans notre exemple, l’affichage de la radio prise lors de l’exécution de l’action « Définir_Face » est évaluée par trois variables. RF_centrageVertebre-correct rapporte que le centrage de la vertèbre ciblée sur la radio de face est correct, alors que RF_disquesVisibles-incorrect indique que la visibilité des disques des vertèbres affichées sur la radio est incorrecte ; et RF_symetriePedicEpineuse-incorrect, que la symétrie de l’épineuse par rapport aux pédicules de la vertèbre ciblée est incorrecte. 8. Réification du modèle de représentation des séquences perceptivo-gestuellesPour réifier le modèle décrit dans la section précédente, nous avons développé le framework PeTRA (PErceptual-gestural TRAces treatment framework) (Toussaint et al., 2015b). PeTRA offre un ensemble d’outils permettant, d’une part, de représenter des traces multi-sources hétérogènes en séquences perceptivo-gestuelles et, d’autre part, de procéder à des analyses de l’apprentissage et à l’extraction de motifs de connaissances fréquents sur la base de ces séquences. Le framework est développé sous la forme d’un processus exploitant une chaîne de logiciels ; ces logiciels sont des outils à fonction unique que nous appelons des « opérateurs » (Mandran et al., 2015). Cette structure, schématisée dans la Figure 10, a été choisie dans un souci de rendre le processus flexible et évolutif. En effet, cette structure facilite les manipulations qui consistent à écarter au besoin les opérateurs jugés non pertinents pour les objectifs de traitement visés, à agencer les opérateurs que l’on veut exploiter et à en intégrer de nouveaux si nécessaire. Dans cet article, nous nous concentrons sur les opérateurs de fusion, de sémantisation et d’annotation. Ces opérateurs font partie de la phase « Transformation de traces » du processus de traitement. Ce sont les principaux opérateurs permettant de transformer les traces brutes multi-sources de notre cas d’étude en séquences perceptivo-gestuelles et séquences perceptivo-gestuelles enrichies. L’ensemble du framework et les opérateurs qui le composent sont décrits in extenso dans (Toussaint, chap. 7, 2015).
Figure 10 • Schéma du framework PeTRA 8.1. L’opérateur de fusionL’opérateur de fusion ou « fusionneur » a pour rôle de synchroniser les traces multi-sources se référant à une interaction multimodale, sur la base de leur correspondance séquentielle. L’objectif est de lier les actions et gestes aux perceptions qui les accompagnent sans perdre la séquentialité des occurrences des différentes modalités. L’opération de fusion est réalisée en deux phases. Dans un premier temps, les traces des différentes sources sont jointes dans un même ensemble et ordonnées séquentiellement. Dans un deuxième temps, l’opérateur fusionne les actions, les gestes et les perceptions sur la base de la configuration de fusion choisie. En fonction du domaine, ou de l’analyse didactique ou pédagogique ciblée, la configuration de fusion entre les traces perceptuelles et une action ou un geste peut être établie sur la base d’un lien de type « contrôle a priori », de type contrôle « a posteriori » ou bien « mixte » (voir section 5 « Jonction entre actions, gestes et perceptions »). En d’autres termes, les perceptions seront considérées comme liées à une action (ou à un geste) si elles précèdent, suivent ou bien sont simultanées à cette action (ou ce geste). Dans notre cas d’étude, chaque action exécutée à partir de l’interface du simulateur TELEOS est associée à plusieurs traces de l’oculomètre et du bras haptique. Les interactions sont considérées de type « contrôle a posteriori » (voir section 5). Par exemple, si l’interne cherche à positionner le trocart, l’action Placer_Trocart va être envoyée par le simulateur. Les différentes manipulations (déplacements, force, vitesse) destinées à placer l’outil dans la position et l’inclinaison idoines sont enregistrées par le bras haptique. Les points visualisés sur la radiographie prise et sur le modèle 3D sont enregistrés par l’oculomètre. Plusieurs points de fixation et plusieurs gestes correspondent donc à une occurrence de l’action Placer_Trocart. 8.2. L’opérateur de sémantisationL’opérateur de sémantisation ou « sémantisateur » a été implémenté dans l’optique de traduire les coordonnées brutes des objets de l’environnement de simulation en dénominations sémantiques. Dans notre cas d’étude, les traces ne rapportent que les nouvelles coordonnées des positions des outils quand ceux-ci sont manipulés. Pour caractériser les changements résultant de ces manipulations, l’opérateur de sémantisation prend en entrée les traces fusionnées dans l’étape précédente et la liste des dénominations sémantiques correspondant aux différents changements de coordonnées possibles pour chaque objet de l’environnement. Les dénominations sémantiques utilisées sont tirées du système de référence en anatomie illustré dans la Figure 11.
Figure 11 • Qualificatifs d’orientation et de mouvement dans le système de référence en anatomie L’opérateur utilise les coordonnées de la séquence courante rapportant les nouvelles positions des outils, et les coordonnées de la séquence précédente par rapport auxquelles le changement effectué sera caractérisé. Les séquences produites à cette étape traduisent, non seulement les conséquences de la manipulation des outils sur leur positionnement, mais aussi la manière dont cette manipulation a été effectuée. Cette information peut être discrète (par ex. « Le trocart a une inclinaison caudale ») ou continue (par ex. « Le trocart est incliné rapidement dans l’axe cranio->caudal »). Le Tableau 2 présente un exemple de séquences de traces avec des coordonnées brutes et le résultat de la sémantisation. Par souci de simplification, seules les coordonnées du trocart sont présentées dans cet exemple. Tableau 2 • Sémantisation des coordonnées des outils
On peut remarquer que le dernier état connu de tous les outils est rapporté d’une séquence à l’autre. En effet, dans l’exemple du tableau, le dernier état connu du fluoroscope ainsi que le dernier état connu du trocart sont mentionnés dans la séquence sémantique S2-S1, même si la séquence ne rapporte aucune manipulation de ce dernier entre S1 et S2. De plus, si cela est jugé nécessaire dans les traitements visés, l’opérateur permet aussi de caractériser les perceptions visuelles sur la base de leur durée en visualisations brèves, normales ou prolongées. Dans ce travail, le seuil pour une visualisation brève est de moins de 200 millisecondes ; pour une visualisation normale, entre 200 millisecondes et 2 secondes ; et pour une visualisation longue, au-delà de 2 secondes. Ces seuils sont dépendants du domaine. Ils ont été déterminés à partir de l’observation de la conduite d’une opération par un chirurgien expert en situation réelle et l’interview de cet expert, après l’opération, sur son comportement lié aux perceptions visuelles. 8.1. L’opérateur d’annotationL’opérateur d’annotation ou « annotateur » permet d’intégrer automatiquement des évaluations calculées à partir de règles expertes dans les séquences perceptivo-gestuelles et de produire des séquences perceptivo-gestuelles enrichies. Dans le cas de TELEOS, des évaluations, appelées variables de situation, sont calculées à partir de règles expertes tout au long d’une session de simulation (Chieu et al., 2010). Chaque variable de situation évalue une action ou un groupe d’actions ; plusieurs variables de situation peuvent évaluer une même action ou un même groupe d’actions.
Figure 12 • Schéma de l’opération d’annotation des séquences dans TELEOS Tel que schématisé dans la Figure 12, l’annotateur reçoit en entrée les séquences sémantisées et les variables de situation calculées au cours d’une session de simulation. L’annotateur identifie ensuite les séquences pour lesquelles elles ont été calculées et les intègre dans ces séquences sous forme d’itemsets. 9. ExpérimentationsNotre proposition de formalisation des séquences perceptivo-gestuelles a été de représenter celles-ci sous forme d’itemsets. Chaque itemset regroupe des items de différentes modalités ayant été identifiés comme cooccurrents. Les séquences sont étendues avec les interactions du STI en réponse à l’activité de l’apprenant. Il s’agit concrètement d’intégrer dans ces séquences les états de la simulation et les évaluations des actions de l’apprenant générées par le STI. Nous avons émis l’hypothèse (H1) : « l’intégration des interactions multimodales de l’apprenant dans des séquences perceptivo-gestuelles améliore la précision de l’analyse de ses activités dans un contexte d’apprentissage ». Nous évaluons cette hypothèse dans cette première partie de nos expérimentations. Les questions de recherche conduisant notre démarche expérimentale pour cette première partie sont les suivantes : QR1 : La représentation multimodale des interactions de l’apprenant est-elle pertinente d’un point de vue didactique ? QR2 : Quelle est la cohérence entre les actions/gestes de l’apprenant et ses perceptions ? Les réponses recherchées visent à estimer l’intérêt de cette proposition et, par là même, l’utilité générale du framework PeTRA proposé pour l’implémenter. En effet, les questions précédentes nous conduisent à celles de l’implémentation du modèle et à la possibilité de l’analyser et de l’exploiter. Elles nous mènent, plus spécifiquement, à celles de l’efficacité des outils proposés pour prendre en charge ces traitements. QR3 : Les outils proposés permettent-ils d’implémenter le modèle proposé ? QR4 : Les outils proposés permettent-ils de modéliser l’activité de l’apprenant en intégrant les différentes facettes de ses interactions ? Ces questions sous-tendent l’hypothèse (H2) stipulant que « l’implémentation du modèle de représentation avec les outils informatiques proposés permet de structurer le traitement et l’analyse de l’activité de l’apprenant en adéquation avec la nature perceptivo-gestuelle de ses connaissances ». 9.1. MéthodologiePour l’évaluation des hypothèses formulées (H1 et H2), nous mettons à l’épreuve, dans notre cas d’étude, la possibilité d’analyser le rapprochement entre les erreurs des internes et leurs perceptions visuelles, représentées dans les séquences perceptivo-gestuelles selon le modèle proposé. Tout le processus de traitement des traces a été réalisé avec le framework PeTRA. Une présentation détaillée du framework PeTRA peut être retrouvée dans les articles suivants : (Toussaint et al., 2015a), (Toussaint et al., 2015b). Pour pouvoir analyser le rapprochement entre les différentes parties de l’activité multimodale des internes, nous avons utilisé l’opérateur d’analyse du parcours de résolution du framework PeTRA. Le parcours de résolution ciblé intègre trois types de comportements qui constituent les points de décisions définissant le parcours de l’apprenant au cours d’une simulation. Pour rappel, la vertébroplastie se réalise en trois phases et le STI TELEOS permet à l’apprenant de circuler librement entre les phases. En effet, l’apprenant peut choisir de commencer par n’importe quelle phase et peut revenir sur des phases déjà considérées comme validées s’il le souhaite. Dans le parcours qu’il définit ainsi tout au long d’une session de simulation, nous identifions (1) les validations de phase, (2) les retours sur phase et (3) les actions correctives. Les validations de phase sont définies par la décision de passer à la phase suivante ; les retours sur phase sont définis par les passages à une phase antérieure motivés par une erreur de validation identifiée par l’apprenant ; enfin, les actions correctives constituent toutes les actions effectuées lors d’un retour sur phase dans le but de corriger l’erreur de validation identifiée. 9.2. Protocole et donnéesLes traces utilisées pour cette étude proviennent de 9 sessions de simulation de vertébroplastie réalisées par 5 internes et 1 chirurgien expert du département d’Orthopédie Traumatologie du CHU de Grenoble. Hormis l’expert aucun des sujets n’avait utilisé le simulateur auparavant. Les exercices de simulation consistaient à traiter une fracture de la 11e et/ou 12e vertèbre thoracique. Avant de commencer, chaque sujet a visionné une vidéo de présentation du simulateur puis effectué une session de prise en main. Le Tableau 3 détaille les données recueillies et traitées. Tableau 3 • Traces collectées et traitées
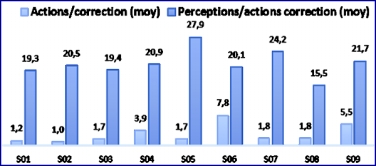
Le symbole « # » fait référence à « nombre », l’abréviation « p-g » désigne l’adjectif perceptivo-gestuelle et « VS », les mots variables de situation. Les métadonnées présentées dans le tableau sous les rubriques « profil », « N° Session » et « Vertèbre opérée » ont été notées manuellement au cours de la collecte de données. Les autres caractéristiques ont été obtenues automatiquement avec l’opérateur d’analyse statistique appliqué dans un premier temps sur l’ensemble des traces brutes. Cette opération a permis le décompte du nombre de traces par session, toutes sources confondues. Autrement dit, la rubrique « Traces brutes » présente le nombre total d’interactions enregistrées par les trois sources : l’interface de simulation, l’oculomètre et le bras haptique. Dans un second temps l’opérateur d’analyse statistique a été appliqué aux séquences perceptivo-gestuelles enrichies. Ces séquences sont celles obtenues après le passage, sur les traces brutes, des opérateurs de nettoyage, de filtrage, de fusion, de sémantisation et d’annotation. Le nombre de traces brutes ne présume pas du nombre de séquences enrichies qui vont être générées. En effet, les volumes de traces générées au cours d’une session sont grandement influencés par l’utilisation du bras haptique et le comportement lié aux perceptions visuelles. Par exemple, une utilisation intensive du bras haptique, de nombreuses visualisations et peu d’actions ponctuelles vont générer beaucoup de traces brutes. Par contre, peu de séquences perceptivo-gestuelles vont être générées à partir de ces traces. En effet, les interactions perceptuelles et gestuelles sont fusionnées avec les actions ponctuelles auxquelles elles se rapportent. Cela explique par exemple, l’écart entre les volumes de traces brutes des sessions S01 et S08 (soit, respectivement, 2702 et 5068) et la proximité de leurs volumes de séquences enrichies (soit 113 et 117). Dans un deuxième temps, l’opérateur de parcours de résolution est appliqué aux séquences perceptivo-gestuelles enrichies. Il identifie les variables de situation notées incorrectes, les erreurs de validation et les séquences de correction. Pour rappel, les variables de situation sont les évaluations à base de règles expertes effectuées par le module de diagnostic du STI ; les erreurs de validation sont assimilées aux retours sur phase motivés par des validations de phase erronées ; et les séquences de correction se réfèrent aux interactions enregistrées au cours des retours sur phase. L’opérateur d’analyse statistique appliqué ensuite décompte ces éléments pour chaque session, ainsi que le nombre de visualisations totales enregistrées. 9.3. RésultatsLe nombre de séquences variant beaucoup d’une session à l’autre, nous utilisons le nombre moyen de visualisations par séquence qui traduit mieux la tendance des analyses visuelles que le simple nombre des visualisations. Il en va de même pour les variables de situation incorrectes. Nous nous intéressons au nombre d’erreurs de validation commises dans une session, le nombre d’actions consacrées à la correction de ces erreurs ainsi que les perceptions liées à ces actions de correction. Le graphique de la Figure 13 résume la distribution des visualisations (perceptions), des variables de situation incorrectes et des erreurs de validation. La session avec la plus grande moyenne de visualisations (24,6) rapporte 19% de variables de situation incorrectes en moins que les autres. On peut constater la même relation entre les analyses visuelles et les erreurs de validation pour l’ensemble des sessions étudiées, excepté pour la session S08. En effet, cette session rapporte une forte moyenne d’analyses visuelles (21,5) et néanmoins beaucoup d’erreurs de validation (20). Cela s’explique par le fait que le sujet exécute à la fois peu d’actions de correction et très peu d’analyses visuelles pour supporter ces actions. En effet, dans le graphique de la Figure 14, on constate que cette session a une faible moyenne de séquences liées à des corrections (1,8) lors d’un retour sur phase, couplée à la plus faible moyenne de visualisations de la série (15,5) pour ces corrections. En comparaison, la session S02 (cf. Figure 14) rapporte la plus faible moyenne d’actions de corrections (1,0), mais suffisamment d’analyses visuelles (20,5) pour consolider les décisions de validation et limiter les erreurs (4, cf. Figure 13). De plus, on peut constater sur la Figure 15 qu’une faible part des visualisations de la session S08 est dédiée à des analyses visuelles de contrôle (7,7 contre 13,8 pour les visualisations liées à l’exploration). La session S09 a été réalisée par le même sujet, mais on observe moins d’erreurs de validation et moins de variables de situation incorrectes, car tout en ayant sensiblement le même taux de visualisations, son comportement lié aux analyses visuelles s’est inversé et il consacre plus d’actions à la correction des erreurs.
Figure 13 • Histogramme des variables de situation incorrectes, visualisations et erreurs de validation
Figure 14 • Histogramme des séquences liées à une correction et des visualisations accompagnant ces séquences
Figure 15 • Histogramme des visualisations de contrôle et d’exploration 9.4. AnalysesLe modèle de représentation proposé, implémenté à l’aide des opérateurs du framework PeTRA, a permis de représenter de manière cohérente des séquences d’interactions où des connaissances perceptivo-gestuelles sont mises en jeu. Les résultats obtenus ont révélé une influence forte du comportement relatif aux analyses visuelles sur les erreurs commises au cours d’une session de simulation. Ces résultats vont dans le sens de l’hypothèse (H1) selon laquelle les différentes facettes des interactions apportent des précisions intéressantes à l’activité de l’apprenant. En effet, ils répondent aux questions de recherche QR1 (« La représentation multimodale des interactions de l’apprenant est-elle pertinente d’un point de vue didactique ? ») et QR2, (« Quelle est la cohérence entre les actions/gestes de l’apprenant et ses perceptions ? »). De plus, ces résultats ont permis de démontrer que les comportements de l’apprenant liés aux perceptions visuelles pouvaient être analysés de manière pertinente à partir des séquences représentées selon le modèle proposé. Ils ont permis d’estimer l’intérêt du modèle mais aussi la capacité du framework PeTRA proposé pour sa réification. Les expérimentations avaient en effet pour but, également, d’évaluer l’hypothèse H2 sur la capacité des outils proposés à réifier notre modèle et faciliter l’analyse des connaissances perceptivo-gestuelles de l’apprenant. Les résultats obtenus adressent les questions de recherche sous-jacentes, QR3 (« Les outils proposés permettent-ils d’implémenter le modèle proposé ? ») et QR4 (« Les outils proposés, permettent-ils de modéliser l’activité de l’apprenant en intégrant les différentes facettes de ses interactions ? »). En l’occurrence, les outils proposés ont permis d’obtenir, à partir des traces brutes multi-sources et hétérogènes, les séquences perceptivo-gestuelles nécessaires à l’analyse des interactions multimodales de l’apprenant. 10. ConclusionLes connaissances perceptuelles et gestuelles sont difficiles à capter dans les EIAH, notamment parce que cela implique l’utilisation de plusieurs périphériques produisant des traces hétérogènes difficiles à traiter dans un objectif d’analyse de l’activité d’apprentissage. Nous avons présenté dans cet article notre méthodologie pour la capture et le traitement de traces perceptuelles et gestuelles produites sur TELEOS, un Système Tutoriel Intelligent dédié à la chirurgie orthopédique percutanée. Le modèle de représentation proposé, implémenté avec l’aide des opérateurs du framework PeTRA, a permis de représenter de manière cohérente des séquences d’interactions où des connaissances perceptivo-gestuelles sont mises en jeu. En effet, l’expérimentation décrite a démontré que les comportements de l’apprenant liés aux perceptions visuelles pouvaient être analysés de manière pertinente à partir des séquences ainsi représentées. Les résultats obtenus ont révélé une influence forte du comportement relatif aux analyses visuelles sur les erreurs commises au cours d’une session de simulation. Ces résultats vont donc dans le sens de l’hypothèse selon laquelle les différentes facettes des interactions apportent des précisions intéressantes à l’activité de l’apprenant. Néanmoins, l’analyse de l’activité de l’apprenant à partir de son parcours de résolution demande un travail préalable de description des éléments du parcours à identifier. Il s’agit de la description des validations de phase, des retours sur phase et des actions correctives, ou de tout autre comportement significatif que l’on voudrait identifier dans le parcours de résolution d’un exercice par l’apprenant. Ceci constitue une limite pour laquelle nous avons proposé une piste de solution dans le cadre d’une étude exploratoire sur la possibilité de détecter de manière automatique les interactions significatives de l’apprenant (Toussaint et al., 2014). Par ailleurs, les séquences représentées selon le modèle décrit dans cet article ont été exploitées à des fins d’extraction d’éléments de connaissances perceptivo-gestuelles par des algorithmes de fouille de données (Toussaint et Luengo, 2015). Les solutions proposées, adressant la problématique de la représentation et de l’analyse des interactions perceptivo-gestuelles de l’apprenant, se focalisent sur le diagnostic comportemental de celui-ci. Le diagnostic épistémique, à partir des nouveaux résultats obtenus sur la modélisation des connaissances perceptivo-gestuelles, n’a pas été exploré. La perspective en ce sens consiste à mettre en place une évaluation des résultats obtenus du point de vue du diagnostic épistémique des connaissances de l’apprenant.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Référence de l'article :Ben-Manson TOUSSAINT, Vanda LUENGO, Francis JAMBON, Analyse de connaissances perceptivo-gestuelles dans un Système Tutoriel Intelligent, Revue STICEF, Volume 24, numéro 1, 2017, DOI:10.23709/sticef.24.1.9, ISSN : 1764-7223, mis en ligne le 05/06/2017, http://sticef.org |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||










© Revue Sciences et Techniques de l'Information et de la Communication pour l'Éducation et la Formation