de l´Information et
de la Communication pour
l´Éducation et la Formation
version à télécharger (pdf)
Volume 21, 2014
Article de recherche
Numéro Spécial
Les EPA : entre description et conceptualisation
|
Contact : infos@sticef.org |
Connaissances embarquées pour personnaliser les environnements d’apprentissage : Application à la plate-forme OP4L
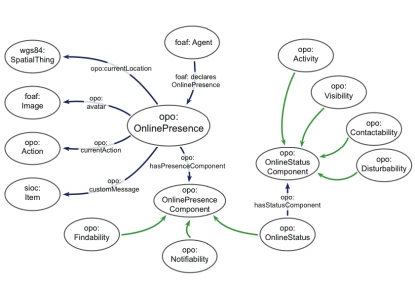
1. IntroductionL’objectif de personnalisation des formations est très présent à la fois du point de vue social et institutionnel. La personnalisation des environnements numériques dans lesquels se déroulent de plus en plus les activités des apprenants est probablement un aspect de sa mise en œuvre. Dans ce contexte, qu’est-ce qu’un environnement personnel d’apprentissage (EPA) et quelles questions de conception et réalisation logicielles pose ce type d’environnement ? La communauté scientifique ne dispose pas encore d’une définition communément admise pour un EPA. En effet, dans un précédent numéro de la revue STICEF (Lavoué et Rinaudo, 2012), Lavoué et Rinaudo considéraient que « individualisation et personnalisation sont des termes ambigus », souvent utilisés l’un pour l’autre car ils renvoient aux notions voisines d’individu et de personne. Par ailleurs, les écrits sur les EPA mettent tantôt l’accent sur une approche techniciste en termes de composants logiciels, tantôt sur l’activité de l’usager dans le choix et l’utilisation de tels composants (Henri, 2014). Le présent article adopte plutôt le point de vue d’un assemblage de composants tel que proposé dans (Attwell, 2007), c’est-à-dire une collection de services et d’outils choisis par l’apprenant et qui aide ce dernier à construire son propre réseau d’apprentissage comprenant différents types de ressources de formation, numériques ou humaines. Mais il servira aussi de base de discussion pour concevoir et implanter des fonctions suggérées à partir d’autres définitions. Nous nous focalisons sur la réalisation de différentes dimensions de la personnalisation au sein de composants logiciels destinés à des EPA, sans pour autant aborder de façon générale la question de leur réunion au sein d’un EPA. Nous montrons (§2 et §3) que du point de vue de la conception et de la réalisation, la personnalisation suppose des connaissances particulières embarquées dans le logiciel et nous faisons un rapide état de l’art de l’existant sur ce point. Nous prenons ensuite (§4) l’exemple d’un environnement particulier, greffé sur une plateforme Moodle, pour montrer quels modèles de connaissances sont utilisés et quelle architecture permet de déployer des services personnalisés. Nous décrivons de façon détaillée la modélisation des données spécifiques à la prise en compte de la présence en ligne d’utilisateurs (apprenants, enseignants, professionnels, etc.). Les premières observations faites avec des étudiants utilisateurs sont présentées ensuite. Enfin (§5), nous nous interrogeons sur des prolongements possibles tant au niveau du prototype décrit que de la personnalisation des environnements de travail des apprenants en général. 2. EPA et personnalisation des ressources pédagogiques en ligneDans son article fondateur (Vassileva, 2008), Vassileva a établi que la mise en œuvre de technologies éducatives impose de s'intéresser au contexte social de l'apprentissage. Elle définit alors trois rôles principaux pour les environnements de formation du futur : (1) accompagner l'apprenant dans sa recherche du contenu adéquat (en accord avec le contexte, en tenant compte de la spécificité de l'apprenant et de ses besoins, le tout pédagogiquement), (2) accompagner l'apprenant dans sa mise en relation avec les personnes appropriées (...) et (3) le motiver et l’inciter dans ses apprentissages. Pour atteindre ces objectifs, les recherches se sont appuyées sur des travaux menés dans différents domaines. L'identification de ressources éducatives est l'un d'eux. Ce problème a largement été étudié en particulier par des approches exploitant l'interopérabilité des métadonnées, menant à l'utilisation d'ontologies et permettant une meilleure adéquation entre les besoins des apprenants et le contexte. En tant qu'applications du web social, les solutions proposées exploitent à la fois les ontologies et les approches par mots-clés. Dans le même temps, la communauté des chercheurs en recommandation de contenus a développé des algorithmes puissants pour le secteur du e-commerce, ce qui a incité les chercheurs à les adapter dans le contexte de la e-formation (Vuokari et al., 2009). La prise en compte de la présence humaine en est un autre. Cela fait plusieurs années que les chercheurs affirment que la présence sociale est un facteur clé de la réussite en e-formation (Cob, 2009), (Lowenthal, 2010). Aux commencements, la présence sociale n'était prise en compte que par la mise en place de forums et de messageries instantanées, ces outils ayant vocation à établir et maintenir le côté social. Le vrai changement a été de pouvoir intégrer les réseaux sociaux en ligne dans les EPA et d’offrir ainsi des ressources humaines. En théorie, ceci doit permettre aux étudiants d'interagir avec leur réseau social dans son ensemble, mais pour un contexte d’apprentissage donné, de nouvelles questions se posent : savoir qui est actif, qui pourrait être disponible, qui est le plus compétent pour répondre à une question ou apporter de l'aide, etc. (Beham, 2010). Les propositions issues des recherches doivent ensuite être implantées dans des composants logiciels et mises à la disposition des apprenants. C’est par exemple ce qui a été fait dans le cadre du projet ROLE (Responsive Open Learning Environment) qui visait à proposer des environnements d’apprentissage garantissant aux étudiants d’être acteurs de leurs apprentissages, facilitant l’accès aux ressources ainsi que la mise en place de démarches réflexives (ROLE, 2013). L’approche adoptée dans ce projet et présentée dans (Bogdanov et al., 2012) vise à intégrer les principales fonctionnalités des EPA dans le LMS des étudiants en y implantant des widgets activables à la demande, permettant d’étendre les fonctionnalités de la plateforme d’enseignement. Nous allons maintenant détailler la mise en œuvre de fonctionnalités associées à ces objectifs à partir de données embarquées dans les systèmes informatiques. 3. Personnaliser à partir de modèles de connaissancesNous considérons ici non pas la personnalisation venant du choix de composants par l’apprenant, mais celle venant des composants logiciels eux-mêmes, avec faculté pour l’apprenant d’utiliser ou non le service. La personnalisation se traduit alors notamment par des services un peu « intelligents » qui se souviennent de qui est l’apprenant, de ce qu’il a fait, de ce qu’il est en train de faire, dans quel univers physique, professionnel et/ou social il vit. Ce type de comportement suppose des données partagées et échangées entre les différents services. De quelles données avons-nous donc besoin et comment les modéliser ? Plusieurs approches ont été proposées pour la réalisation d’applications personnalisées à la formation, nous les décrivons brièvement, puis nous focalisons notre présentation sur les modèles à base de connaissances. Nous développons successivement les connaissances à représenter, la nécessité d’assurer l’interopérabilité au niveau des modèles et nous donnons des exemples de modèles déjà utilisés pour réaliser des environnements personnels d’apprentissage. 3.1 Plusieurs approches pour réaliser la personnalisationHistoriquement, la personnalisation a toujours été un objectif des travaux sur les systèmes informatiques pour l’apprentissage. Les premiers tuteurs intelligents (Sleeman et Brown, 1982) et les hypermédias adaptatifs (Brusilovsky, 1996) offraient des fonctions de personnalisation reposant sur des connaissances embarquées dans ces systèmes. Si les architectures et les fonctionnalités visées aujourd’hui sont bien différentes de ces systèmes pionniers, les bases de modèles apprenant étaient posées dans les systèmes tutoriels raisonnant à partir d’un modèle apprenant nommé « overlay », c’est-à-dire construit « par recouvrement » à partir du modèle des connaissances du domaine. La personnalisation concernait alors les rétroactions du système pendant l’exécution d’une activité ainsi que le séquencement des activités ou l’adaptation des parcours. Ces modèles ont été enrichis notamment avec l’utilisation de modèles bayésiens (Conati, 2010) et par la prise en compte de plusieurs autres facteurs incluant par exemple des aspects émotionnels. De nombreux exemples en sont proposés dans la revue IJAIED (IJAIED, 2009) dont les articles sont accessibles en ligne. Ensuite sont apparues des méthodes numériques issues de la fouille de données (analyse de traces d’usage personnelles ou collectives). Ces méthodes développées plutôt dans le contexte du e-commerce ont été adaptées notamment pour la recommandation de ressources dans les systèmes de formation (Vuokari et al., 2009), (Manouselis et al., 2010), (Santos et Boticario, 2012), puis pour l’analyse des traces des apprenants (STICEF, 2007), (Marty et Mille, 2009). Un courant de recherche spécifique sur la personnalisation s’est développé suite à l’augmentation du nombre et de la qualité des données disponibles via les sessions d’apprentissage en ligne, comme en témoignent la création des conférences Educational Data Mining (EDM, 2009) et Learning Analytics (LAK, 2009) et celle de la revue Journal of Educational Data Mining (EDM, 2009) et d’un numéro spécial de JETS (IFETS, 2009). Chaque ensemble de méthodes ayant ses avantages et ses inconvénients, des chercheurs proposent aussi des méthodes hybrides combinant les deux approches. La thèse soutenue par P.Y. Gicquel (Gicquel, 2013) en est un exemple pour réaliser la personnalisation des dispositifs mobiles d’apprenants en visite dans un musée. Dans la suite de ce document, nous nous limitons aux approches reposant sur des modèles explicites de connaissances (approche systèmes à base de connaissances). Nous nous interrogeons successivement sur les connaissances à modéliser et sur la façon de les modéliser pour assurer la nécessaire interopérabilité des données, essentielle pour permettre ensuite des services communicants entre eux. 3.2 Quelles connaissances modéliser ?Dans les tout premiers systèmes, la personnalisation était uniquement assurée à partir la représentation de connaissances relatives à l’apprenant dans un modèle d’apprenant. Dès que sont apparus les réseaux, l’apprentissage collaboratif, les échanges via Internet et plus récemment la mobilité, il est devenu nécessaire de représenter aussi une part du contexte dans lequel un apprenant évolue. Les modèles d’apprenant ont été parmi les premiers modèles d’utilisateurs créés pour les systèmes informatiques, mais ensuite la modélisation des utilisateurs s’est développée comme une thématique plus large. Un modèle apprenant comprend généralement des données statiques relativement pérennes d’ordre général comme l’identité, les diplômes ou qualifications possédés, les préférences, etc. Un tel modèle comprend également des données dynamiques relatives à l’apprentissage en cours, qui évoluent au fur et à mesure des interactions logiciel/apprenant. De nombreuses caractéristiques relatives à un apprenant peuvent être saisies et implantées dans des prototypes. Cependant, il faut s’interroger sur leur utilité en fonction des objectifs visés. Dès 1988, J. Self (Self, 1990) conseillait de ne recueillir et conserver dans un modèle d’apprenant que les données véritablement utilisables. À ce sujet, (Desmarais et de Baker, 2012) proposent une synthèse des dernières avancées en termes de modélisation de l’apprenant. Les modèles de contextes sont aussi une préoccupation ancienne en informatique, voir par exemple (McCarthy, 1993). Plus récemment (Zimmermann et al., 2007) ont caractérisé la notion de contexte pour les utilisateurs de systèmes informatiques de la façon suivante : « Context is any information that can be used to characterize the situation of an entity. Elements for the description of this context information fall into five categories: individuality, activity, location, time and relations. The activity predominantly determines the relevancy of context elements in specific situations and the location and time primarily drive the creation of relations between entities and enable the exchange of context information among entities ». Dans les systèmes dédiés à la formation, on peut citer les travaux de (Jovanovic et al., 2007) qui proposent l’ontologie LOCO-Cite pour décrire le contexte d’usage d’une ressource d’apprentissage. Toutefois, c’est le développement des dispositifs mobiles qui a donné son essor aux travaux sur la représentation des contextes en général (informatique ubiquitaire) et pour les environnements d’apprentissage en particulier. 3.3 Comment assurer l’interopérabilité des donnéesL’absence de modèles de connaissances largement partagés a longtemps pesé sur le développement et l’échange d’applications (environ jusqu’aux années 2000), et pas seulement dans le champ de la formation. Heureusement, un certain nombre de recherches en ingénierie des connaissances ont fini par converger et la mise en place d’une structure internationale, le World Wide Web Consortium (W3C, 2009), a permis d’en cristalliser et prolonger les résultats. Le W3C réunit des institutions membres, une équipe permanente et toute personne intéressée. Il s’est donné pour mission de développer des standards ouverts pour assurer le développement à long terme du web. Les concepts, langages et outils dont nous disposons pour assurer l’interopérabilité au niveau des modèles sont les ontologies exprimées en OWL, avec des éditeurs et des raisonneurs. Les auteurs d’ontologies sont invités à respecter un ensemble de bonnes pratiques pour les documenter et les publier en ligne. Les ontologies sur lesquelles reposent des services de personnalisation utilisent en général les concepts de personne et de ressources qui sont déjà modélisés dans FOAF (FOAF, 2009) et SIOC (SIOC, 2009). FOAF (acronyme de Friend Of A Friend) propose un vocabulaire rdf pour décrire des personnes et les lier par des propriétés à d’autres entités du web. SIOC (acronyme pour Semantically-Interlinked Online Communities) est utilisé avec FOAF pour décrire des données relatives aux communautés en ligne. Pour illustrer notre propos, nous allons décrire les modélisations de données utilisées dans un système qui intègre un service de personnalisation incluant les réseaux sociaux dans un environnement institutionnel d’apprentissage (EIA) sur Moodle. 4. Les modèles de connaissances du prototype OP4L4.1 Objectifs et contexte du projetOP4L (pour Online Presence For Learning) est un projet du programme européen SEE-ERANET dont la description complète est donnée sur le site web du projet (OP4L, 2009). OP4L a pour objectif d’explorer l’utilisation d’outils et de services web pour favoriser la présence sociale sur les plateformes de formation en ligne et permettre d’utiliser cette présence humaine pour améliorer les apprentissages. Dans la suite du texte, nous utilisons le sigle OP4L aussi bien pour nommer le projet que pour désigner le prototype construit au sein du projet. OP4L met donc l’accent sur la présence en ligne qu’il définit comme une description temporaire de la présence d’un utilisateur dans le monde en ligne. Une telle description peut aussi être vue comme une image qu’une personne projette d’elle-même dans ce monde en ligne. Le prototype OP4L a été construit à partir de DEPTHS (DEsign Patterns Teaching Help System), un logiciel de formation existant et accessible à partir d’une plateforme Moodle (Jovanovic et al., 2007). DEPTHS utilise des ontologies comme base unificatrice permettant la mise à la disposition de l’apprenant de différents outils dans un environnement d’apprentissage collaboratif institutionnel, spécialisé pour l’apprentissage du concept de design pattern en génie logiciel. 4.2 Description fonctionnelleLa description technique du prototype OP4L sort du cadre du présent article. Le lecteur intéressé pourra la trouver dans (Jovanovic et al., 2007) et dans les livrables du projet en ligne sur le site. Nous allons donc simplement en donner une vue générale et décrire les modèles et données qui rendent possibles la fourniture des services proposés. OP4L tient compte du contexte, au sens des « context aware PLE » (Jeremic et al., 2009), en intégrant des données de contexte provenant de différents systèmes, outils et services. Le contexte d’apprentissage y est défini comme le contexte d’une situation d’apprentissage donnée et il comprend les composants suivants (Jeremic et al., 2011) (1) l’activité d’apprentissage qui est exécutée ou l’événement relatif à l’apprentissage qui vient de survenir ; (2) le matériel de formation (ressource, document) utilisé ou produit par l’apprenant durant cette activité ; (3) les personnes impliquées (apprenants, enseignants, experts) ; (4) l’environnement en ligne dans lequel l’activité se déroule ; (5) le moment auquel l’activité se déroule. Ces données contextuelles sont intégrées dans un modèle flexible reposant sur des ontologies, plus précisément un ensemble d’ontologies inter-reliées nommé LOCO framework (Learning Object Context Ontologies) (Jeremic et al., 2011). Ces ontologies représentent la couche fondatrice pour le développement de l’application informatique DEPTHS, dont les principales caractéristiques sont : (1) l’intégration de données et de ressources provenant de différentes applications d’apprentissage avec lesquelles l’apprenant interagit, (2) la recommandation de ressources portant sur les design patterns en tenant compte du contexte constitué d’entrepôts en ligne, des ressources produites et partagées par les apprenants, des fils de discussion et autres données disponibles, (3) les recommandations contextualisées faites par d’autres étudiants, experts ou enseignants pour offrir de l’aide dans une situation donnée. 4.3 Modéliser la présence en ligneBeaucoup d’auteurs ont étudié la présence en ligne et leurs écrits constituent autant de sources potentielles pour dégager les traits qui peuvent la caractériser et faire partie d’un modèle informatique. L’idée de présence a été largement étudiée d’abord dans le cadre de la formation à distance, pas encore en ligne (Garrison et Arbaugh, 2007), (Lowenthal, 2010), (Richardson et Swan, 2003), puis dans le cadre de la formation en ligne (Aragon, 2003), (Cob, 2009), (Jovanovic et al., 2009). Plusieurs formes de présence sont d’ailleurs distinguées (Norman, 2004), (Wilson, 2009), présence cognitive, sociale, présence du formateur, etc., toutes les études en soulignent les bénéfices pour les apprentissages, parlant de la création d’une sorte de « sixième sens en ligne ». Cependant, des études de communication dans les situations de face-à-face montrent l’importance de communications verbales et non-verbales comme la proximité physique, le langage du corps, les expressions faciales, les gestes, la façon de s’habiller, etc. Aucun de ces éléments n’existe à l’identique dans les environnements de formation en ligne. Ils sont « remplacés » jusqu’à un certain point par certains caractères de la présence en ligne comme les messages indiquant le statut (occupé, disponible, absent), des avatars, des témoins de présence, la localisation actuelle, l’activité actuelle, etc. Les premières réalisations ont essentiellement exploré cette présence virtuelle au travers de forums et d’outils de messagerie instantanée. L’apparition des réseaux sociaux et la rapide expansion de leur usage a amené les concepteurs d’environnements de formation en ligne à étudier les bénéfices éventuels de ces réseaux en les intégrant dans l’espace de formation. Le défi est alors d’adapter les interactions système-personne à l’état de présence des apprenants (conseiller quelqu’un qui est disponible) et à proposer des services de façon à ce que les interactions entre participants tiennent compte de ces données sur leur état de présence. Plusieurs approches ont été proposées, notamment dans les systèmes de recommandations de ressources. Certaines tendent à exploiter des données de type appréciations ou tag provenant de certains services ou applications pour compléter une indexation sémantique traditionnelle de ressources pédagogiques, par exemple les propositions de fusion entre web sémantique et web participatif faites par B. Huynh Kim Bang dans (Huynh Kim Bang, 2009). D’autres, comme Gilliot et al. (Gilliot et al., 2012), dans le prototype SMOOPLE, utilisent directement des données issues de diverses applications dont les réseaux sociaux en même temps que des modèles sémantiques relatifs au domaine d’activité et au contexte. Certains travaux ont proposé des approches permettant la recommandation d’acteurs, de ressources et/ou d’activités, comme par exemple (El Helou et al., 2010) qui exploitent le système de recommandation des 3A (Actors, Assets et Group Activities), cependant aucune approche, à notre connaissance, ne propose de recommander des personnes en indiquant comment les joindre (en tenant compte de leurs états en ligne) de la même façon que des ressources numériques dans une plateforme de formation, fusionnant les données distribuées dans les réseaux de mobiles et les réseaux sociaux. L’ontologie proposée (figure 1) vise à décrire la présence en ligne dans le « monde en ligne », c’est-à-dire essentiellement les messageries instantanées et les sites des réseaux sociaux. Elle respecte au mieux les principes d’interopérabilité et d’économie que nous avons posés. En effet, elle utilise au maximum des ontologies existantes et largement référencées pour décrire les entités connues, comme FOAF et SIOC précédemment citées. Elle n’introduit que quelques entités et relations nouvelles pour décrire des concepts non encore modélisés comme le statut d’une présence en ligne qui peut prendre les valeurs activité, visibilité, contactable, dérangeable. Un agent déclare sa présence en ligne, qui peut se manifester de différentes façons, par exemple, en affichant sa photo et/ou ce qu’il est en train de faire, etc. Enfin, elle est entièrement documentée et son code RDF est disponible en ligne (OPO, 2009), le lecteur intéressé y trouvera notamment les définitions précises de chacun des concepts et des relations proposées. Pour le projet OP4L, la notion de contexte d’apprentissage de DEPTHS a été étendue pour y inclure la notion de présence en ligne telle que définie précédemment. En conséquence des liens ont été établis entre les ontologies LOCO et une nouvelle ontologie de présence en ligne nommée OPO (Online Presence Ontology) de façon à obtenir une définition sémantique précise de cette notion de contexte d’apprentissage étendu (Jovanovic et al., 2009), (Stankovic, 2008). Les ontologies LOCO et OPO ainsi intégrées servent donc de nouvelle couche fondatrice pour le développement de services au sein de l’application OP4L. Ces services utilisent les données de présence en ligne pour recommander aux apprenants les personnes qu’ils ont intérêt à contacter afin d’obtenir de l’aide ou de proposer du travail collaboratif. Par exemple, un étudiant qui a le profil et les compétences requises, et qui est en ligne, ne sera pas recommandé si son statut indique qu’il est occupé et ne souhaite pas être dérangé. En revanche, le système peut recommander une rencontre en face-à-face avec un autre étudiant qui vient de rentrer dans le bâtiment et dont le statut indique qu’il peut être contacté.
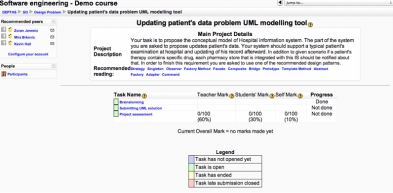
Figure 1 • Le modèle de « présence en ligne » extrait de (Stankovic, 2008) Une démonstration est accessible en ligne sur le site du projet et les plugs-in développés pour l’échange de données de présence en ligne y sont documentés. 4.4 Principaux services implantés dans OP4LLa page d’accueil principale est celle d’une plateforme Moodle standard. L’objectif est d’offrir aux étudiants des services nouveaux dans un environnement qu’ils maîtrisent. Le prototype OP4L affecte principalement le contenu d’un cours intitulé “Updating patient's data problem UML modelling tool”. Une fois ce cours sélectionné, nous avons accès aux fonctionnalités de la plateforme (voir figure 2). On note en haut à gauche une fenêtre indiquant des personnes recommandées, ici Zoran, Mira et Kevin, le type de présence (ici données issues de Facebook) et la façon dont ils peuvent être contactés (ici par courrier électronique). L’ontologie OPO, celles décrivant les acteurs (leur identité, leurs compétences par rapport au problème en cours de résolution) et le domaine de travail, ainsi que les plugs-in permettant de mettre à jour à intervalles réguliers les données de présence issues des réseaux sociaux ont servi au calcul des personnes à recommander. Un tel processus suppose que les personnes concernées aient donné leur accord pour que leurs diverses formes de présence en ligne soient récupérées par le logiciel. D’un point de vue opérationnel, on notera que OP4L va plus loin que l’installation de services à la carte proposée par le projet ROLE puisqu’il traite les données issues de tels services (par exemple, la présence captée sur Facebook), mais ne laisse pas la même flexibilité aux utilisateurs enseignants ou étudiants.
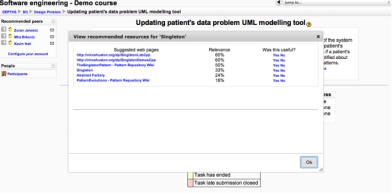
Figure 2 • À l’intérieur du prototype De plus, la plateforme dispose des fonctionnalités plus classiques de recommandation de contenus relativement aux centres d’intérêts (figure 3).
Figure 3 • Recommandation de contenus Une originalité est d’avoir intégré les travaux échangés entre les étudiants aux ressources de la bibliothèque numérique. Le service de recommandation de ressources utilise les descriptions de ces ressources faites à partir notamment des ontologies du domaine de travail (les patrons de conception en génie logiciel). Pour collaborer, les étudiants disposent également d’un outil de brainstorming permettant l’annotation et l’enrichissement des idées échangées. Enfin, les étudiants ont la possibilité de soumettre leurs travaux pour une évaluation par leurs pairs. 4.5 Enquête et démonstrations auprès d’étudiants4.5.1 Objectifs et méthodologieNotre objectif était d’obtenir un rapide retour d’utilisateurs potentiels (étudiants niveau master) à propos des fonctionnalités relatives à la présence en ligne offertes dans OP4L. En effet, comme expliqué dans le paragraphe précédent, la plupart des résultats en sciences sociales n’ont pas été établis sur l’utilisation d’un LMS proposant des services de présence en ligne. Ainsi, nous ne disposons d’aucune donnée précise relative aux attentes des étudiants en matière de présence en ligne. Une analyse en profondeur avant le développement d’un prototype offrant des services basés sur des technologies sociales et sémantiques est une tâche quasi-impossible à cause de la rapidité de l’évolution de ces technologies. En effet, toute analyse de besoins conduite dans le contexte des technologies existantes ne correspondra à aucune des technologies disponibles quelques années plus tard. C’est pourquoi la plupart des équipes de recherche choisit de construire des prototypes d’environnements d’apprentissage offrant de nouveaux services et d’analyser comment les utilisateurs finaux utilisent, aiment ou pas les nouvelles fonctionnalités. C’est par exemple la conclusion de Brooks et al. (Brooks et al., 2009) dans leur communication intitulée : “Lessons Learned using Social and Semantic Web Technologies for E-learning”: “there is no substitute for constantly trying to test techniques in the real world of students’ learning”. Le projet OP4L a adopté une telle approche par prototypage. 4.5.2 Population test et mise en œuvreLes premiers retours à propos de la plate-forme OP4L ont été collectés en février 2012 auprès de 15 étudiants de l’université de Lorraine. Ces 15 étudiants ont été choisis pour être représentatifs de filières où ce genre d’outils n’est pas mis en œuvre afin de disposer de retours avec un œil neuf. Aucun des étudiants, ni de leurs enseignants n’était impliqué directement dans le développement du prototype. De plus, les étudiants n’ont pu tester que les fonctionnalités de la plateforme sans pouvoir effectuer les tâches proposées puisque le cours implanté sur le prototype est un cours spécialisé de génie logiciel et que les étudiants disponibles pour ce premier test appartenaient à d’autres disciplines. Cependant, il était intéressant pour la poursuite du projet de pouvoir recueillir les avis d’étudiants, puisqu’aucune enquête n’avait été effectuée pour établir le cahier des charges, et notamment d’étudiants issus d’autres disciplines que les sciences de l’ingénieur. Les étudiants ont été classés dans les cinq catégories suivantes afin d’observer d’éventuelles variations : (1) 3ème année de licence en communication, (2) 1ère année de master en droit privé européen, (3) 1ère année de master en chimie, (4) 2ème année de master en technologies multimédia, (5) 2ème année de DUT Génie Biologie Santé. L’étude s’est déroulée en trois étapes. Étape 1. Les étudiants ont reçu un texte de présentation des services de présence en ligne et des scénarios proposés par l’environnement DEPTHS. Un premier questionnaire (voir résultats en 4.5.3) a cherché à mettre en évidence leurs usages et leur maîtrise des environnements et outils issus du web et des réseaux sociaux. Afin d’identifier leurs premières attentes en matière d’intégration de ce genre de services, il a également été demandé de proposer un scénario idéal, selon eux, d’utilisation de ces services. Étape 2. Nous avons proposé une démonstration du prototype OP4L-DEPTHS et plus spécifiquement des services de présence en ligne ; ils ont été alors libres de l’utiliser comme ils le voulaient, revoir les services par exemple. Étape 3. Un second questionnaire a permis de recueillir les premiers retours et impressions après présentation et usage de ces services. 4.5.3 Retours des étudiants sur leurs usages et attentes à propos des réseaux sociauxCi-après, nous détaillons les profils d’usages des étudiants sur les réseaux sociaux, tels qu’ils apparaissent au dépouillement du premier questionnaire. Profils utilisateurs des technologies dans leurs apprentissages universitaires La fréquence d’utilisation de la plateforme Moodle est principalement une fois par semaine sauf pour les étudiants en master de droit qui l’utilisent plus de trois fois par semaine. Parallèlement, le moyen privilégié pour contacter les autres étudiants est le téléphone portable – le courriel n’est utilisé que de façon épisodique. Par contre, tous les étudiants mentionnent le fait qu’ils se connectent à leurs réseaux sociaux au moins une fois par jour. Scenarios identifiés par les étudiants Pour tous les étudiants (communication, droit, santé, multimédia), le scénario se place dans le cadre de la réalisation d’un projet (en autonomie ou collaboratif). Une des premières attentes concerne la recherche d’informations. Le constat de ces étudiants est que les recherches standards sur Wikipedia de termes techniques sont rarement satisfaisantes (articles non adaptés, recherches non abouties, etc.). Le service de recommandation de pairs va leur permettre d’entrer en contact avec les étudiants dont les centres d’intérêts sont similaires. L’état des pairs (disponible pour échanger, pour une réunion, pour travailler) leur donnera la possibilité d’obtenir une information adaptée, dans la forme et le fond, à leurs besoins et leurs attentes. Enfin, les activités proposées (plus particulièrement, les activités soutenues par l’outil de brainstorming) permettront de renforcer les échanges et les collaborations en systématisant les conseils et les échanges pair-à-pair. 4.5.4. Retours des étudiants sur les aspects présence en ligneLe tableau ci-dessous rassemble les réponses données par les étudiants au second questionnaire visant à évaluer leur perception et leur intérêt pour les services de présence en ligne envisagés dans OP4L. Seuls les quatre premiers étaient implantés dans le prototype. Le tableau affiche les résultats par catégories d’étudiants comme plus haut dans le texte. Les étudiants avaient pour consigne de classer par ordre d’importance les propositions données (de 1 pour le plus important à 8).
Tableau 1 • Appréciations données par les étudiants sur l’ensemble des dimensions de la présence en ligne. Nous donnons ci-après quelques suggestions et commentaires proposés librement par les étudiants. Suggestions - Permettre la création de profils utilisateurs détaillés incluant les formations suivies, les centres d’intérêt et quelles sont les personnes qui ont été aidées et dans quels domaines. Ceci permettra d’avoir une meilleure connaissance des personnes connectées afin de mieux cibler les personnes à interroger. - Donner la possibilité d’avoir une liste des pairs recommandés au delà de la liste des contacts existants sur les réseaux sociaux utilisés afin d’élargir le champ des personnes susceptibles de collaborer ou d’apporter une aide. Commentaires - Cet outil peut ainsi être utile pour identifier les contenus additionnels appropriés, pour collaborer sur des sujets spécifiques et pour recevoir des conseils sur des travaux déjà réalisés. La propriété « social » semble être vraiment un plus pour les étudiants. - L’ergonomie générale de l’outil étudié est plutôt bonne et bien adaptée. La possibilité d’interroger et collaborer constitue le point fort et le fait de disposer de l’information quant à l’état des connectés permet d’optimiser les contacts et les échanges. Les fonctionnalités les plus appréciées sont, savoir qui est disponible pour communiquer, savoir qui est occupé et ne veut pas être dérangé, savoir qui est présent sur la plate-forme de formation. Les principales conséquences identifiées suite à l’usage des services proposés sont le gain de temps et des réponses plus pertinentes aux demandes. On note que, quelle que soit la discipline de provenance, tous placent en bonne position le fait de savoir qui est présent sur la plateforme et qui est disponible pour communiquer. Il faudrait creuser l’importance qu’ils attachent ou non à l’idée de savoir parmi les disponibles quelle est la personne la plus apte à les aider, ce qui ne pourra se faire qu’avec des étudiants de génie logiciel utilisant l’environnement pour leur projet de design pattern. Il n’y a pas pour l’instant de différence significative relative à la discipline de l’étudiant. 4.5.5 Analyse des résultats obtenusCette étude portait sur une première démonstration du prototype OP4L auprès d’étudiants qui n’étaient pas la population cible initiale et qui appartiennent à une université différente de celle dans laquelle OP4L a été conçu et implanté. L’hypothèse était que la fourniture de services de présence en ligne dans une plate-forme de formation pouvait apporter une aide significative pour certaines de leurs activités pédagogiques. Si l’hypothèse est vérifiée, de tels services pourront être proposés pour constituer des EPA. L’analyse préalable de l’usage que les étudiants font quotidiennement des techniques de communication et environnements numériques de travail a montré qu’ils n’étaient pas des utilisateurs réguliers de Moodle. Les réseaux sociaux et le téléphone apparaissent comme leur moyen de communication préféré. Dans ce contexte, l’appréciation qu’ils portent sur le prototype est plutôt encourageante, puisque, sans être des familiers du travail dans Moodle, ils perçoivent immédiatement l’intérêt qu’un tel outil pourrait leur apporter pour un des travaux importants dans le cadre de la préparation de leur master, à savoir le projet par groupes qu’ils proposent tous dans le scénario demandé. De plus, nous avons recueilli leur classement des différentes dimensions caractérisant la présence en ligne que nous avons proposées. Les résultats montrent à nouveau leur intérêt, mais mériteraient des études complémentaires et des croisements avec les appréciations d’autres étudiants. Enfin, parmi les points positifs, ils mentionnent un gain potentiel de temps pour effectuer leur travail, ce qui est certainement un critère important aussi bien pour les étudiants que pour les enseignants qui les encadrent. Du point de vue des enseignants, ce type d’outil favorise l’activité de l’étudiant, sa prise d’initiative et la collaboration avec les pairs, et donc la transition depuis des activités à l’initiative des enseignants vers des activités centrées sur des groupes d’apprenants. Nous notons de plus l’absence de remarques négatives relatives à l’utilisation de données issues des réseaux sociaux. D’autres évaluations plus précises de l’environnement de formation OP4L ont été effectuées chez d’autres partenaires du projet (OP4L evaluation, 2012). L’une, orientée logiciel, repose sur la méthode SUMI (Software Usability Measurement Inventory) proposée en génie logiciel. Une autre, conduite à l’université de Skopje, a concerné des étudiants en informatique qui ont utilisé les services OP4L pour résoudre des exercices de design patterns. De façon assez inattendue, et alors qu’ils n’hésitent pas à contacter leurs enseignants via Facebook, ils ont peu utilisé cette fonction et ont déclaré réserver les réseaux sociaux pour des « activités privées ». Nous expliquons partiellement ces réactions par le caractère singulier et artificiel d’un système utilisé à la veille d’examens traditionnels où aucune collaboration n’était permise. 5. Conclusions et perspectives5.1 Sur les EPA en généralLes paragraphes précédents ont montré que l’on savait modéliser beaucoup de connaissances permettant la personnalisation et assurant une bonne interopérabilité entre services les utilisant. D’un point de vue opérationnel, des limites existent. Elles tiennent notamment au coût de développement de certains modèles, à la difficulté d’acquisition de certaines données, au temps d’exécution de certains traitements. Par exemple, nous n’avons pas inclus de données relatives au volet socio-affectif des apprenants, comment ils perçoivent ce que ressentent les autres. Parmi ces possibles, il faut donc parvenir à déterminer ce qui est utile, pour qui, dans quel contexte de formation. Mais les plus grandes difficultés résident sans doute dans l’identification des services souhaités et l’étude d’un rapport qualité/prix pour chacun d’eux, puis dans la mise à disposition de services à la fois largement paramétrables au gré des besoins (évolutifs) des utilisateurs et pourtant simples et conviviaux. Quelles architectures flexibles proposer ? La plupart des fonctions de personnalisation implantées jusqu’ici le sont dans des environnements relativement fermés, et rarement à la demande de l’utilisateur, alors que le vrai défi est celui d’une offre relativement ouverte de services recombinables au sein d’EPA. À quels apprenants faut-il laisser ces initiatives ? Comment les préparer à en faire bon usage ? Ces travaux contribuent à définir les cahiers des charges de modules logiciels permettant aux apprenants de configurer leur EPA. 5.2 Vers une autre définition de l'identité par le numériqueDans les perspectives en marge de ces travaux, émerge une nouvelle vision de l'identité par le numérique. Des modèles spécifiques vont permettre d’écrire l’être au sein des EPA selon deux dimensions complémentaires à celle étudiée ci-dessus, à savoir en « grammes » et en « interactions », (Nowakowski, 2013). En effet, le « gramme » en tant que combinaisons de la trace et du graphe devient l’entité visible, combinable et/ou traitable de l’individu qui « s’individue » par la technologie. Ainsi, dans cette logique, et comme l’affirme Merzeau dans (Merzeau, 2009), nous ne pouvons pas ne pas laisser de trace. Ces traces comme signifiants, résultats des interactions avec de multiples dispositifs techniques, sont contextuelles et les réseaux (sociaux, pédagogiques, professionnels et autres) deviennent l’espace de manifestation d’une différance, (Derrida, 1967). Ainsi, pour continuer dans cette direction, le modèle de cette identité représente alors l’ensemble de cette chaîne d’éléments associée aux séquences d’événements qui se matérialisent en traces. Le modèle va ainsi donner à voir une part du signifié que nous construisons autour des usages. De cette vision, nous pouvons dériver des trajectoires individuelles au sein d’un dispositif numérique en ligne (site web ou EPA). Cette trajectoire permet alors une approche géométrique pour l’étude des usages du numérique qui nous permet de mettre en place de nouvelles stratégies de recommandation de contenus au sein des EPA, mais également nous amène à repenser la notion d’identité par le numérique et, au-delà ouvre le champ de recherche sur les EPA vers celui de l’être en numérique. RemerciementsLe projet OP4L a été partiellement financé par le programme européen SEE-ERANET, projet n° 115. Nous remercions tous les partenaires pour leur coopération ainsi que les étudiants de master qui ont accepté de participer à cette étude. Nous remercions également les lecteurs de la première version soumise pour leurs suggestions constructives. BIBLIOGRAPHIEARAGON S. R. (2003), Creating social presence in online environments, in New Directions for Adult and Continuing Education, n°100, p. 57-68. ATTWELL G. (2007), The Personal Learning Environments - the future of eLearning?, eLearning Papers, 2(1) Disponible sur internet (consulté le 25 avril 2014) BEHAM G., KUMP B., LEY T., LINSTAED S. N., (2010), « Recommending knowledgeable people in a work-integrated learning system », 1st RecSysTEL workshop, Procedia Computer Science 1, Elsevier, p. 2783-2792 BOGDANOV E., ULLRICH C., ISAKSSON E., PALMER M., GILLET D., (2012), From LMS to PLE: A Step Forward through OpenSocial Apps in Moodle. Conference ICWL, Sinaia, Romania,, LNCS 7558, Springer Verlag, p. 69-78 BROOKS C., BATEMAN S., GREER J., McCALLA G., (2009), Lessons Learned using Social and Semantic Web Technologies for E-Learning in Semantic Web Technologies for e-Learning, Dicheva D., Mizoguchi R., Greer J., eds., IOS Press BRUSILOVSKY P., Methods and techniques of Adaptive Hypermedia, (1996), User Modeling and User-Adapted Interaction, Vol. 6 (2-3), p. 87-129 COB S.C., (2009). Social Presence and Online Learning: A current view from a Research Perspective, Journal of Interactive Online Learning, Vol. 10 (3), p. 241-254 CONATI C., (2010). Bayesian Student Modeling in Advances in Intelligent Tutoring Systems, Nkambou R., Bourdeau J. & Mizoguchi R. eds., Studies in Computational Intelligence, Springer Verlag, DERRIDA J, (1967). De la grammatologie, Les éditions de Minuit, Paris DESMARAIS M.C., de BAKER R.S.J., (2012). A review of recent advances in learner and skill modeling in intelligent learning environments, User Model User-Adapted Interaction, Vol. 22, p. 9-38 Site de EDM : Disponible sur internet EL HELOU S., SALZMANN C., GILLET D., (2010). The 3A Personalized Contextual and Relation-based Recommender System, Journal of Universal Computer Science, Vol.16, p. 2179-2195 Ontologie FOAF : Disponible sur internet GARRISON D.R., ARBAUGH J.B., (2007). Researching the community of Inquiry Framework: Review, Issues, and Future Directions. The Internet and Higher Education, Vol. 10(3), p. 157-172 GICQUEL P.Y., (2013), Proximités sémantiques et contextuelles pour l’apprentissage en mobilité : Application à la visite de musée, Thèse de doctorat, UTC, mai 2013 GILLIOT J.-M., GARLATTI S., REBAI I., PHAM NGUYEN C., (2012), A Mobile Learning Scenario improvement for HST Inquiry Based Learning, in EWFE workshop proceedings, WWW 2012, Lyon GRANDBASTIEN M., NOWAKOWSKI S., (2012), Recommander des ressources humaines dans un LMS. Exemple du projet OP4L. Actes du colloque TICE 2012, Lyon. HENRI F., (2014), Étude sur les environnements personnels d’apprentissage comme domaine de recherche, STICEF vol. 21, numéro thématique sur les EPA, (à paraître). HUYNH KIM BANG B., (2009), Indexation de documents pédagogiques: Fusionner les approches du Web Sémantique et du Web participatif, thèse de doctorat, UHP, Nancy Site de Education Forum for Educational Technology and Society: Disponible sur internet Site de la revue IJAIED : Disponible sur internet JEREMIC Z., JOVANOVIC J., GASEVIC D., (2009), Semantic Web Technologies for the Integration of Learning Tools and Context-aware Educational Services, In Proceedings of the 8th International Semantic Web Conference, Washington, DC, USA, LNCS Vol. 5823, p. 860-875 JEREMIC Z., MILIKIC N., JOVANOVIC J., RADULOVIC F., BRKOVIC M. (2011), Using Online Presence to Support Collaborative Learning in Personal Learning Environments: the OP4L Approach, Proceedings of the Second International Conference on eLearning, p.130-136 JOVANOVIC J., KNIGHT C., GASEVIC D., RICHARDS G., (2007), Ontologies for Effective Use of Context in e-Learning Settings, Educational Technology &Society, Vol. 10(3), p. 47-59 JOVANOVIC J., GASEVIC D., STANKOVIC M., JEREMIC Z., SIADIATY M., (2009), Online Presence in Adaptive Learning on the Social Semantic Web, In Proceedings of the 1st IEEE International Conference on Social Computing - Workshops (Workshop on Social Computing in Education), Vancouver, BC, Canada, p. 891-896 Site des conférences Learning Analytics : Disponible sur internet (consulté le 21 avril 2013) LAVOUE E., RINAUDO J.-L., (2012). Editorial du numéro spécial Individualisation, personnalisation et adaptation des Environnements Informatiques pour l’Apprentissage Humain, revue STICEF, Vol. 19, 2012, mis en ligne le 21/02/2013, http://sticef.org LOWENTHAL P. R., (2010), Social Presence, in S. Dasgupta (Ed.), Social computing: Concepts, methodologies, tools, and applications, Hershey, PA: IGI Global, p. 129-136 McCARTHY J., (1993) Notes on formalizing context, IJCAI'93, Proceedings of the 13th international joint conference on artifical intelligence – Vol.1, p. 555-560 MANOUSELIS N., DRACHSLER H., VUORIKARI R., HUMMEL H., KOPER R., (2010), Recommender Systems in Technology Enhanced Learning. In Handbook of Recommender Systems, Ricci, F., Rokach, L., Shapira, B., Kantor, P.B. (eds), p. 387-415 MARTY JC., MILLE A. Eds, (2009), Analyse de traces et personnalisation des environnements informatiques pour l’apprentissage humain, Traité IC2. Lavoisier. Paris MERZEAU L. (2009). Du signe à la trace. Dans Empreintes de Roland Barthes. Hermès. NORMAN D., 2004, Emotional Design, New York Basic Books Disponible sur internet (consulté le 25 avril 2014) Site du projet OP4L : Disponible sur internet OP4L Livrable D6.1 : Disponible sur internet Site de téléchargement de l’ontologie : Disponible sur internet RICHARDSON J. C., SWAN K., (2003), Examining social presence in online courses in relation to students’ perceived learning and satisfaction, Journal of Asynchronous Learning Networks, Vol. 7(1), p. 68-88 Site du projet ROLE : Disponible sur internet (consulté le 20 avril 2014) SANTOS O.C., BOTICARIO J.G., (2012), Educational Recommender Systems and Technologies. Practices and Challenges. IGI Global. SELF J.A. (1990). Bypassing the intractable problem of student modelling, in C. Frasson and G. Gauthier (eds.), Intelligent Tutoring Systems: at the Crossroads of Artificial Intelligence and Education, p.107-23, Norwood, N.J.: Ablex Ontologie SIOC : Disponible sur internet SLEEMAN D.H., BROWN J.S. (eds), (1982), Intelligent Tutoring Systems, Academic Press, New York, 345p., STANKOVIC M., (2008), Modeling Online Presence, In: Proceedings of the First Social Data on the Web Workshop, Karlsruhe, Germany. Revue en ligne STICEF, (2007). Numéro spécial : Analyses de traces d’interaction dans les EIAH, Disponible sur internet (consulté le 25 avril 2014) VASSILEVA J., (2008), “Towards Social Learning Environments“, IEEE TLT, Vol. 1 (4), p. 199-214 VUOKARI R., MANOUSELIS N., DUVAL E. eds., (2009), Special Issue on Social Information Retrieval for Technology Enhanced Learning, Journal of Digital Information, Vol. 10 (2) Site du W3C : Disponible sur internet WILSON S., (2009), Presence in Social Networks, in Handbook of Research on Social Software and Developing Community Ontologies, S. Hatzipanagos and S. Warburton eds., IGI Global, p. 493-511 ZIMMERMANN A., LORENZ A., OPPERMANN R., (2007), An operational definition of context, in Proceedings of the 6th international and interdisciplinary conference on modeling and using context, CONTEXT’07, Berlin, Heidelberg, Springer Verlag, p. 558-571
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Référence de l'article :Monique GRANDBASTIEN, Samuel NOWAKOWSKI, Connaissances embarquées pour personnaliser les environnements d’apprentissage : Application à la plate-forme OP4L, Revue STICEF, Volume 21, 2014, ISSN : 1764-7223, mis en ligne le 18/12/2014, http://sticef.org |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

© Revue Sciences et Techniques de l'Information et de la Communication pour l'Éducation et la Formation, 2014