de l´Information et
de la Communication pour
l´Éducation et la Formation
version à télécharger (pdf)
Volume 20, 2013
Article de recherche
|
Contact : infos@sticef.org |
Analyse chronologique des traces journalisées d’un guide d’étude pour apprentissage autonome
1. IntroductionLa quantité et la qualité du matériel didactique accessible sur Internet sont en croissance rapide. Il est de plus en plus facile pour un étudiant de consulter des documents et des applications Web pour parfaire ses connaissances sur un sujet. Ainsi, les opportunités d’apprentissage autonome se multiplient. Par contre, l’évaluation des connaissances acquises par auto-apprentissage et leur comparaison avec des barèmes et des objectifs d’apprentissage ne sont pas autant accessibles sur le Web. Pourtant, l’auto-évaluation joue un rôle déterminant dans l’apprentissage (Tan, 2012). L’auto-évaluation favorise la motivation intrinsèque et encourage l’apprenant à adopter une démarche d’apprentissage plus efficace (McMillan et Hearn, 2008). L’apprenant a besoin de connaître ses forces et ses faiblesses. Il a besoin d’orienter ses efforts. En mathématiques, l’exerciseur est un outil d’auto-évaluation qui peut combler ce besoin. Il présente des tâches à l’utilisateur, lui donne une évaluation des réponses et lui procure une vue d’ensemble de sa progression. Ce type d’application procure un soutien à l’apprentissage autonome (self-regulating learning) (Azevedo, 2009) ; (Winne et al., 2006) L’application fournit un retour d’information sur les acquis d’apprentissage et aiguille l’étudiant vers un contenu pertinent visant à répondre à des objectifs pédagogiques (Azevedo, 2009) ; (Hadwin et al., 2007) ; (Schraw, 2007). Il existe des exerciseurs commerciaux dont certains ont un nombre d’utilisateurs important. Il y a la famille des tutoriels cognitifs (Koedinger et al., 1995) et la plateforme ASSISTment (Feng et al., 2008). Il y a aussi le système Assessment and LEarning in Knowledge Spaces (ALEKS) qui revendique plusieurs millions d’utilisateurs (ALEKS Corporation, 2013) ; (Falmagne et al., 2006) ; (Hardy, 2004). On compte de nombreux prototypes de recherche parmi lesquels certains ont des modules assez sophistiqués pour guider l’apprenant et adapter le contenu (Conejo et al., 2004) ; (Ginon et Jean-Daubias, 2012) ; (Jean-Daubias et al., 2011). Le guide d’étude dont il est ici question comporte un exerciseur de 1 030 exercices assorti de notes en ligne qui expliquent la théorie et qui équivalent à 150 pages imprimées. Dix thèmes de mathématiques de niveau pré universitaire sont couverts, par exemple : exposants et radicaux, trigonométrie ou systèmes d’équation linéaires. Les exercices sont regroupés dans 144 sujets avec une moyenne d’un peu moins de huit exercices par sujet. Il est possible d’accéder à la section pertinente des notes à partir des exercices correspondants. Le mode d’utilisation est entièrement laissé à la discrétion de l’étudiant qui peut décider de le parcourir, de consulter les notes ou de résoudre des exercices.. Contrairement à la grande majorité des exerciseurs, il n’y a pas une évaluation formelle de la réponse de l’utilisateur : la réponse à une question est affichée sur demande et c’est l’utilisateur qui indique au système s’il a réussi ou non l’exercice. L’exerciseur garde la trace des questions pour lesquelles l’étudiant déclare avoir réussi, ce qui permet de jauger la progression dans la matière. L’utilisation de l’exerciseur pendant quatre mois à l’été 2012 sera ici étudiée. Pendant cette période, 107 étudiants ont utilisé l’application parmi lesquels 49 ont exécuté des exercices. Les autres ont navigué à travers les notes et parmi les exercices sans y répondre. Les actions de ces utilisateurs ont été journalisées. Les données recueillies à partir de traces de cette journalisation seront ici décrites ainsi que des techniques d’analyse de séquences. Une des questions à laquelle nous tenterons de répondre est comment caractériser les différents types d’utilisation à partir de ces données. La durée d’utilisation et les activités auxquels se consacre l’utilisateur serviront à catégoriser ces types d’utilisation. L’analyse des traces qui permettra d’identifier ces catégories est un champ de recherche actif dans le domaine des interfaces adaptatives. C’est un des principaux sujets de cette étude. Les prochaines sections portent sur les travaux pertinents à l’analyse des traces dans les environnements informatiques pour l'apprentissage humain (EIAH) et sur ceux qui traitent de la détection de la continuité d’utilisation et de l’engagement à partir de telles traces. Une analyse descriptive des traces du guide d’étude est ensuite présentée ainsi qu’une perspective chronologique et visuelle de séquences d’actions. Une comparaison entre les durées d’exécution des exercices d’un expert et celles des utilisateurs sera faite. Enfin, on déterminera si les résultats à un pré-test ont un impact sur la continuité d’utilisation de l’application. 2. Analyse de journalisation et traces utilisateursL’analyse de la journalisation est une vieille technique de recherche en informatique (Tolle, 1983). Lorsqu’elle porte sur l’utilisation des systèmes par des utilisateurs, elle consiste à étudier les échanges électroniques entre les systèmes et les personnes (Agosti et al., 2011) ; (Agosti et Di Nunzio, 2007) ; (Jansen, 2009). Le forage de données en EIAH est l’analyse de cette journalisation de grands volumes de d’échanges entre l’étudiant et le système. Il constitue un domaine d’étude en pleine expansion (Merceron et Yacef, 2005) ; (Baker et Yacef, 2009). Outre les arguments déjà bien établis que la nature et la quantité de données issues des EIAH prennent de l’ampleur, Stamper et al. (Stamper et al., 2012) affirment qu’une expérience peut être réalisée en quelques jours et dans des conditions expérimentales idéales de ceteris paribus dans des environnements EIAH Web comportant un trafic d’utilisateurs soutenu. En marketing Web, cette méthode est connue sous le vocable « d’expérience A et B », où une moitié des internautes est redirigée vers une condition A et l’autre vers la condition B. Cette méthode permet de valider rapidement, à partir de l’analyse des traces, si un facteur a une influence sur l’apprentissage ou sur l’utilisation de l’application. 2.1. Traces et apprentissage autonomeEn EIAH, la notion de traces peut ne pas être limitée à la journalisation. Ainsi, Choquet & Iksal (Choquet et Iksal, 2007) proposent un modèle d’analyse des traces qui ajoute à l’analyse de la journalisation d’autres sources d’information comme des entrevues, des questionnaires ou des enregistrements vidéos. Dans un contexte d’apprentissage en réalité virtuelle, ces mêmes types de traces permettent d’alimenter l’élaboration d’un méta-modèle d’apprentissage inspiré du Unified Modeling Language (UML) (Baudoin et al., 2007). UML est aussi utilisé pour l’analyse de la journalisation pour des EIAH hétérogènes (Broisin et Vidal, 2007). Les traces peuvent être utilisées pour procurer une « assistance métacognitive » en permettant à l’étudiant de visualiser ces traces durant une activité d’apprentissage (Cram et al., 2007) ou à l’enseignant de superviser l’évolution des activités d’apprentissage de leurs élèves (Delestre et Malandain, 2007). Azevedo (Azevedo, 2009) a fait un survol d’études portant sur l’apprentissage autonome et l’analyse des traces. Perry et Winne (Perry et Winne, 2006) rapportent une étude de traces avec l’environnement gStudy (Winne et al., 2006). Cet environnement est une coquille qui permet d’intégrer du matériel didactique. L’étudiant peut alors l’explorer et l’annoter de différentes façons. L’étude porte sur des élèves du niveau primaire et propose un modèle théorique de stratégies d’étude. Le même environnement a été utilisé par Hadwin et al. (Hadwin et al., 2007) avec un groupe de huit étudiants du premier cycle universitaire. Ils rapportent des analyses détaillées des activités d’études. Ils classifient les étudiants selon leur niveau d’annotation par une technique de regroupement de données (clustering). Des techniques d’analyse de graphes de transition d’état sont appliquées pour identifier des constances dans les activités d’études. Une des conclusions importantes de leur recherche est que les activités d’études rapportées par les étudiants eux-mêmes ne concordent pas fidèlement à celles qui ressortent des traces. Les comptes-rendus des étudiants constituent donc une source insuffisante pour expliquer comment ils étudient. 2.2. Temps et apprentissageLes traces des utilisateurs des EIAH peuvent se composer d’événements, comme la consultation de documents ou le furetage qui correspond à des déplacements d’une page à l’autre ou à l’intérieur d’une même page auxquels on associe le temps d’occurrence. Le temps joue un rôle important en apprentissage. Des travaux en psychométrie ont démontré son utilité comme indicateur de la facilité avec laquelle l’apprenant accomplit une tâche (Taraban et al., 2001) ; (Thompson et al., 2009) ; (Wang et Hanson, 2005) et comme indicateur de la difficulté d’une tâche (Jarušek et Pelánek, 2012) ; (Linden van der et al., 1999) ; (Wise et Kong, 2005). La courbe d’apprentissage de Ebbinghaus (Ebbinghaus, 1885) a été adaptée par Snoddy (Snoddy, 1926) à la psychologie clinique et par Wright (Wright, 1936) à la production industrielle. Ces modèles d’apprentissage démontrent qu’avec la répétition d’une tâche, le temps d’exécution de la tâche diminue régulièrement selon une échelle logarithmique en vertu d’une loi de la puissance de la pratique (Ritter et Schooler, 2001). Le temps des événements dans les EIAH est aussi un indicateur de l’engagement qui peut être lui-même un indicateur parmi d’autres, de la motivation (Baker, 2007) ; (Cocea, 2011) ; (Cocea et Weibelzahl, 2009). Le désengagement est la manifestation du comportement hors tâche. Ainsi, consacrer un temps très long à la lecture d’une page ou cliquer rapidement dans plusieurs pages avec de courts temps d’arrêt sont des exemples de désengagement. À l’inverse, consacrer un temps raisonnable à la lecture d’une page est un exemple d’engagement (Cocea et Weibelzahl, 2006). Beck (Beck, 2005) propose même un modèle mathématique dans le contexte de l’utilisation d’un tutoriel de lecture. Cependant, une déconnexion automatique du système est un désengagement sans être un indicateur de motivation : l’utilisateur est allé diner, par exemple, avant de reprendre son utilisation du système. Il faut par ailleurs croiser les données temporelles avec d’autres types de données pour estimer l’engagement. En résolution de problèmes, le temps consacré à la résolution peut être très différent d’un problème à l’autre, selon la difficulté, la connaissance préalable de l’apprenant, la fatigue, le flot (Csikszentmihalyi, 2008), etc. D’autre part, l’apprenant peut consulter d’autres ressources que l’application et ainsi sembler se désengager de l’application tout en continuant d’être engagé dans sa tâche d’apprentissage. Parmi les autres facteurs qui peuvent être croisés avec le temps pour évaluer l’engagement, sont, entre autres, la probabilité que l’étudiant réussisse la tâche, l’historique des erreurs précédentes, la consultation de capsules d’aide et la complexité de la tâche. 2.3. Analyse de séquences temporellesL’analyse des séquences temporelles des actions de l’utilisateur est un type d’analyse qui a été peu utilisé dans les EIAH. Les techniques d’analyse des séquences ont pris beaucoup d’ampleur dans le domaine de la bio-informatique (Durbin et al., 1998), mais ces techniques existent en sciences sociales depuis déjà plusieurs années (Abbott, 1995) ; (Abbott et Tsay, 2000). Leur application dans le cadre d’analyse de traces d’utilisateurs s’apparente au problème de l’analyse des actions de l’utilisateur. Elles contribuent à la reconnaissance des buts derrière les actions, approche connue sous le nom de la reconnaissance de plan (Carberry, 2001) ; (Desmarais et al., 1989). Plusieurs techniques statistiques, notamment les modèles de Markov, permettent d’identifier des régularités à travers les séquences d’actions. Les travaux de Armentano et Amandi (Armentano et Amandi, 2012) constituent un exemple récent de l’application de telles techniques au problème de la reconnaissance de plan. Plusieurs études utilisent ces mêmes techniques pour la navigation à travers des pages Web (Deshpande et Karypis, 2004) ; (Kosala et Blockeel, 2000) ; ((Qiqi et al., 2012); ((Srivastava et al., 2000) Köck et Paramythis (Köck et Paramythis, 2011) appliquent des modèles de Markov et des analyses par regroupement de données (cluster analysis) pour l’analyse de séquences d’actions dans un EIAH. Cette approche permet de classifier différents types d’apprenants selon leur style de résolution de problèmes et selon leur propension à recourir à de l’aide en ligne. Dans le même domaine de recherche, Li et Yoo (Li et Yoo, 2006) utilisent une technique de segmentation basée sur des chaînes de Markov et des modèles bayésiens pour classifier les apprenants selon leur style d’apprentissage et leurs interactions avec un EIAH. Jeong et al. (Jeong et al., 2008) utilisent une approche similaire pour évaluer l’effet de styles d’interventions dans un EIAH. Les élèves interagissent avec un agent pour lui « enseigner ». C’est une approche où l’élève prend le rôle d’enseignant et ces interactions sont modélisées par un modèle de Markov latent (HMM — Hidden Markov Model). Différents styles d’apprentissage peuvent être ainsi identifiés. Beal et al. (Beal et al., 2007) utilisent un HMM pour tenir compte du niveau d’engagement lors de la prédiction du taux de succès à des exercices dans un EIAH. À partir de données d’interaction avec un EIAH portant sur les mathématiques du niveau secondaire, les auteurs effectuent une première classification des réponses à des exercices sur la base d’un algorithme de segmentation qui s’inspire de travaux antérieurs (Beal et al., 2006). Cinq catégories sont utilisées : essais-erreurs systématiques ou abuser de l’aide, résoudre un problème correctement sans aide, résoudre incorrectement un problème sans aide, apprendre avec aide et sauter un problème (Guessing/Help Abuse; Independent-Accurate problem solving; Independent-Inaccurate problem solving; Learning with Help, Skipping). Les catégories « résoudre un problème correctement sans aide » et « résoudre incorrectement un problème sans aide » donnent des réponses sans utilisation de l’aide en ligne. Par la suite, les séquences de catégories sont analysées avec un HMM qui détermine un niveau d’engagement : bas, moyen, élevé (low, medium et high). Notre approche diffère de ces approches en mettant l’emphase sur l’analyse visuelle de séquences afin d’identifier certaines régularités d’utilisation et de distinguer des catégories d’utilisateurs. 2.4. Objectifs de l’étudeÀ l’exception des études de Hadwin et al. (Hadwin et al., 2007) et de Perry et Winne (Perry et Winne, 2006), peu de travaux portent sur les comportements d’apprentissage autonome identifiés à partir de données de journalisation d’utilisation d’EIAH. La première étude de Hadwin et al. correspond à un contexte expérimental d’une courte durée de deux heures et la deuxième, celle de Perry et Wine, porte sur un environnement précis et est utilisé auprès de jeunes enfants. Notre étude repose plutôt sur une démarche de plusieurs semaines où il n’y a pas d’encadrement académique. Le niveau d’utilisation et les stratégies d’études adoptées par l’étudiant relèvent donc d’une initiative personnelle. Un des objectifs de la présente étude est d’identifier des modes d’utilisation définis selon le temps consacré à différentes activités d’utilisation du guide. Deux facteurs caractérisent cette étude. Le premier facteur est que les traces journalisées contiennent le détail de l’interaction avec l’exerciseur. Des événements captent les activités de consultation des notes et des exercices. Une analyse chronologique détaillée de ces événements est effectuée afin d’identifier des patrons d’utilisation. Le second facteur est la nature de l’évaluation des réponses aux exercices. Plutôt que de laisser le système évaluer l’exactitude de la réponse, l’interface offre d’afficher la réponse de chaque problème et laisse l’utilisateur indiquer lui-même s’il a réussi ou non l’exercice. Cette approche a un impact à la fois sur la fiabilité des réponses et le temps d’exécution des exercices. L’utilisation des traces journalisées de cette étude doit donc être analysée et interprétée dans le contexte particulier défini par ces facteurs. Nous décrivons dans ce qui suit l’application du guide d’étude et les traces qui sont recueillies puis analysées. La méthodologie d’analyse et les résultats sont ensuite détaillés. 3. Guide d’étude de mathématiques de niveau préuniversitaireL'École polytechnique de Montréal offre à tous ses étudiants admis aux programmes de premier cycle une épreuve de mathématique en ligne d’une heure. Ce test vise à identifier les forces et faiblesses en mathématiques dans les compétences préalables aux cours communs de la majorité des programmes de l’École. Pour ceux qui ont des faiblesses à combler ou qui veulent améliorer leur performance, l’École offrait jusqu’à l’an dernier un cours de révision intensive des notions mathématiques, au rythme de six heures par jours, cinq jours par semaine pendant quatre semaines. Ce mode intensif n’étant vraisemblablement pas adéquat pour une grande partie des étudiants visés, l’École a abandonné cette formule. Le guide vise à combler ce retrait du cours avec une formule autonome et plus flexible. Une fois l’épreuve de prétest mathématique complétée, l’étudiant reçoit par courriel une évaluation diagnostique du niveau de maîtrise de six sujets fondamentaux : algèbre, trigonométrie, géométrie, calcul différentiel et intégral, algèbre linéaire. Il est invité à utiliser le guide. Mais la décision de l’utiliser et les modalités d’utilisation sont laissées à sa discrétion. Aucune pénalité, ni aucune récompense ne sont associées à l’utilisation du guide. Le guide est un exerciseur comportant 1030 exercices répartis en dix thèmes assortis d’une section de documentation théorique. La section documentation est constituée des notes du cours que le guide remplace. Ces notes reprennent les mêmes dix thèmes que les exercices. Les notes correspondant à chaque exercice sont accessibles par hyperlien. Il est donc facile pour l’étudiant de consulter la théorie sous-jacente à chaque exercice. Elle correspond à 150 pages en format papier. La figure 1 représente une page d’exercices qui compte quatre items regroupés dans un sujet. La figure 2 illustre la fenêtre de dialogue qui apparaît lorsque l’utilisateur clique sur « Valider la réponse 2... ». C’est à l’utilisateur lui-même d’indiquer s’il a réussi ou non l’exercice. Cette approche suscite la responsabilité de l’étudiant dans son apprentissage et évacue les tentatives de soutirer la réponse par différents autres moyens que l’on associe à des désengagements. Si l’étudiant répond « Oui », la réponse est alors affichée en permanence dans la page d’exercices correspondante et un indicateur en marge de la section affichée dans la navigation lui indique le nombre d’exercices terminés : par exemple, les exercices 1 et 2 de la figure 1 affichent la réponse et la fraction « 2/4 » dans la navigation de gauche indique la proportion d’exercices effectués.
Figure 1 • Page d’exercices
Figure 2 • Boite de dialogue de réponse à un exercice La figure 3 représente une page de notes correspondant aux exercices de la page d’exercices illustrée à la figure 1. L’application est implémentée en langage PHP et elle est accessible à distance avec un fureteur Web. Son utilisation nécessite un identificateur unique pour chaque étudiant et l’identificateur est associé à chaque événement dans les fichiers journaux. Le guide d’étude a été mis en ligne en juin 2012 et les traces retenues ont été recueillies durant cinq mois d’utilisation. Il a été offert à ceux qui avaient accepté de compléter l’épreuve de mathématique et aux étudiants de première année qui suivaient un cours de mathématiques. On dénombre 107 étudiants qui ont utilisé l’application à différents niveaux de durée complète d’utilisation.
Figure 3 • Page de notes 4. Analyse de la journalisationLe guide d’étude enregistre les événements dans un fichier texte. Le format des événements enregistrés est décrit dans la prochaine section et le type d’analyse effectué est ensuite détaillé. 4.1. Format des tracesLes traces soumises à l’analyse sont enregistrées dans deux journaux dont les noms de fichier correspondent à un identifiant unique pour chaque utilisateur. Le premier journal recueille les événements de navigation dans l’application et de manipulation des menus. Un exemple du contenu de ce fichier est présenté dans le tableau 1. La première ligne correspond à l’ouverture de l’application. La deuxième ligne correspond à un défilement de la page des exercices de 102 pixels. À la cinquième ligne, l’utilisateur a caché un élément de menu de la page des exercices. À la septième ligne, l’utilisateur demande l’affichage des exercices du sujet 2, du sous-sous-module 1, du sous-module 1 du module 2. À la huitième ligne, l’utilisateur est à la page des exercices, mais demande de consulter la sous-sous-section 1 de la sous-section1 de la section 2 du module 2 des notes et ainsi de suite.
Tableau 1 • Exemple de traces dans le journal des événements L’autre journal contient les réponses de l’utilisateur à la boîte de dialogue de validation de chacun des exercices. Par exemple, une ligne de ce fichier se lirait ainsi : ligne 2012-06-04 14:25,2,1,1,1,1,1,4. Le tableau 2 donne les correspondances de ces valeurs. Le résultat peut avoir pour valeur « 1 » si l’étudiant juge avoir résolu le problème et « 2 » s’il ne l’a pas résolu.
Tableau 2 • Exemple de trace dans le journal des exercices 4.2. Méthode d’analyseUne étape de prétraitement est effectuée pour l’ajout d’information implicite pour distinguer les enregistrements en trois types d’événements : - navigation : consultation de notes ou navigation dans la page des exercices ; - exercice exécuté ; - pause : ajout défini par une durée déterminée qui indique que l’utilisateur n’est pas actif. 4.2.1. Traitement de la durée et des pausesLa durée de l’événement est calculée en premier lieu en soustrayant le temps de l’événement à celui du précédent. Ceci amène à des événements pouvant avoir des durées très grandes lorsqu’il y a de longues interruptions, par exemple lorsque l’étudiant reprend les exercices après une pause pour l’heure du dîner. Des sessions sont créées et des événements de pause sont insérés pour éviter ces durées excessives associées à différents événements Les événements de type navigation et exercices durant lequel l'utilisateur est présumé se consacrer entièrement à l'application sont regroupés pour faire une session. Ainsi, les durées de plus de 1 800 secondes (30 min) sont repérées et une nouvelle session est démarrée : les événements qui suivent sont associés à une nouvelle session. Cette durée s’aligne sur le temps maximal qu’on peut s’attendre à devoir consacrer aux exercices les plus longs et il est corroboré par les durées mesurées des exercices qui sont suivis d’autres événements. C’est le temps de désengagement pour déconnexion de système fixé par Cocea et Weibelzahl (Cocea et Weibelzahl, 2006). Puis, pour les événements de navigation dont la durée est supérieure à 300 secondes (5 min), un événement pause est alors inséré après 300 secondes (5 min) de l’occurrence de cet événement et les temps sont réajustés en conséquence. En d’autres termes, on considère que la consultation d’un écran sans défilement ne peut excéder 300 secondes (5 min). C’est un compromis si on considère les données de Cocea (Cocea, 2011) qui fixait entre 100 secondes et 400 secondes (6,6 min) la durée normale de lecture d’une page. À noter que ces pauses ne sont pas ajoutées aux événements de type exercice car il est possible que des exercices nécessitent une plus grande durée. Leur durée sera alors limitée par le seuil de 1 800 secondes (30 min) d’inactivité pour le démarrage d’une nouvelle session. 4.2.2. Analyse de séquencesUne des originalités de l’étude consiste à analyser des séquences d’événements. Ces séquences permettent d’obtenir une vue globale de l’activité de l’apprenant et caractérisent les sessions d’interaction avec l’application. La méthode d’analyse consiste à échantillonner, à intervalle régulier, l’événement qui correspond à la dernière action effectuée afin de faciliter l’affichage des séquences d’actions. Pour nos analyses, les intervalles varient de deux à 10 secondes. Il est évidemment possible que durant un intervalle, deux types d’activités s’intercalent. L’activité dont la durée est entièrement à l’intérieur de l’intervalle de temps sera alors passée inaperçue, d’où l’importance de prendre des intervalles relativement courts, tout en permettant d’afficher des activités sur une période comme la durée des sessions d’interactions. Les analyses ont été réalisées dans l’environnement d’analyse statistique R (Venables et al., 2012). Le logiciel TraMineR a été utilisé pour l’analyse des séquences d’actions (Gabadinho et al., 2011). Le code des analyses de même que les données sont mis à la disposition de la communauté au lien : http://datapublication.tge-adonis.fr/author/a-001-089/p-001-018. 5. Analyse de l’utilisationNous décrivons dans un premier temps des statistiques descriptives de l’utilisation de l’application avant l’analyse des séquences afin d’identifier des modes d’utilisation assez tôt dans le cycle d’interaction. 5.1. Statistiques descriptivesLe tableau 2 rapporte quelques statistiques générales de
l’utilisation de l’exerciseur. Des 107 étudiants qui ont
utilisé l’application (Ν), 49 d’entre eux ont
effectué des exercices (n1). Les autres n’ont
effectué que du furetage à travers les exercices et les notes,
sans jamais tenter de répondre à un exercice
(n2). Ce groupe est en fait plus nombreux que les utilisateurs
qui ont effectué des exercices : 49 contre 58. Les valeurs
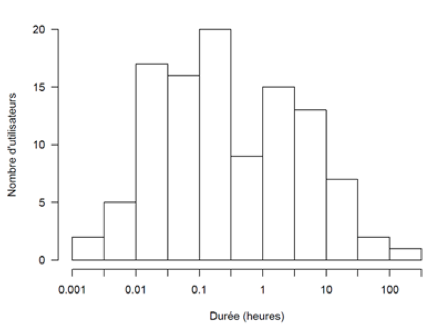
Tableau 2 • Statistiques générales d'utilisation de l'application Le niveau d’utilisation a varié considérablement entre les utilisateurs. Le graphique de la figure 4 donne la distribution du nombre d’exercices exécutés selon le nombre d’utilisateurs. On peut voir que 22 (10 + 12) d’entre eux ont fait moins de 10 exercices. À l’autre extrême, un étudiant a effectué plus de 1 000 exercices, c’est-à-dire qu’il a couvert l’ensemble de tous les exercices. Un autre groupe de 11 étudiants a effectué entre 100 et 1 000 exercices. La répartition du temps d’utilisation par utilisateur est illustrée sur la figure 5. Les 107 utilisateurs se retrouvent inclus dans l’histogramme et leur utilisation est donnée en heures. La grande majorité a consacré moins d’une heure à l’application (x < 0), alors qu’une dizaine y a consacré plus de 10 heures, dont un individu qui y a consacré plus de 100 heures.
Figure 4 • Nombre d’exercices exécutés par utilisateur
Figure 5 • Distribution du temps d’utilisation La répartition des exercices effectués selon les modules présentée à la figure 6 indique que la très grande majorité des exercices effectués est concentrée sur le module 2, tandis que la grande majorité des utilisateurs n’ont consulté qu’un seul module. Le module 2 est celui qui comporte le plus grand nombre d’exercices et le premier dans l’ordre présenté aux utilisateurs.
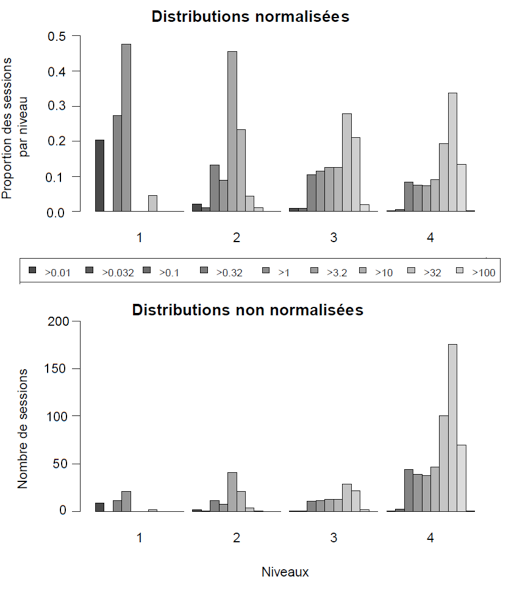
Figure 6 • Exercices exécutés par module Les différentes mesures présentent donc un portrait global où une majorité d’étudiants a fait un usage limité de l’exerciseur. On peut présumer qu’il s’agit d’utilisateurs curieux, mais qui n’avaient pas l’intention de poursuivre une mise à niveau mathématique. Peut-on conclure qu’il s’agit d’étudiants qui maîtrisent déjà la matière? Il en sera question dans la section 8. La prochaine étape de l’étude porte sur l’analyse des séquences d’activités des utilisateurs telles que reconstruites à partir des traces. Une question qui se pose est de savoir si ces séquences peuvent nous instruire sur les catégories d’utilisation, notamment sur les utilisateurs qui ont fait un usage substantiel de l’exerciseur par rapport aux autres. 6. Analyse de séquences d’activitésLes séquences d’activités sont une manière de visualiser le déroulement des activités de l’étudiant à travers le temps comme présenté à la section 4.2.2. L’analyse est effectuée dans le but d’identifier les caractéristiques du comportement des utilisateurs qui ont fait un usage de l’application. Nous définissons donc dans un premier temps des niveaux d’utilisation afin de visualiser les activités des utilisateurs dans le temps sous la forme de séquences. 6.1. Niveaux d’utilisationPour les besoins de cette étude, des niveaux d’utilisation par étudiant sont définis selon le temps total consacré à l’application. Une mesure simple de cette utilisation est la durée d’activité en excluant les pauses. Ainsi, les niveaux d’utilisation sont définis sur une échelle croissante, mais non linéaire, de quatre niveaux d’utilisation : - Évaluation rapide de l’application : moins de 1 minute, - Évaluation de l’application : de 1 à 10 minutes, - Utilisation ponctuelle : de 10 minutes à 2 heures et - Utilisation intensive : plus de 2 heures. Les étudiants sont regroupés selon ces quatre niveaux. La figure 7 présente le nombre d’utilisateurs dans chaque groupe. À noter que même si le groupe du niveau 4 semble moins nombreux, la très grande partie du temps d’utilisation global des utilisateurs se retrouve dans cette catégorie. Les niveaux 1 et 2 ne comptent en fait que pour une mince proportion de l’utilisation étant donné la très faible quantité d’activité de ces utilisateurs.
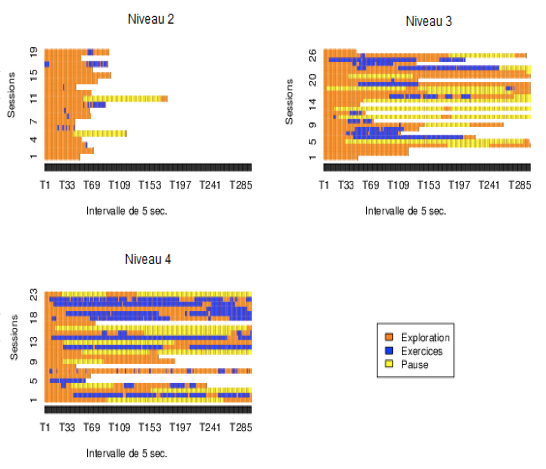
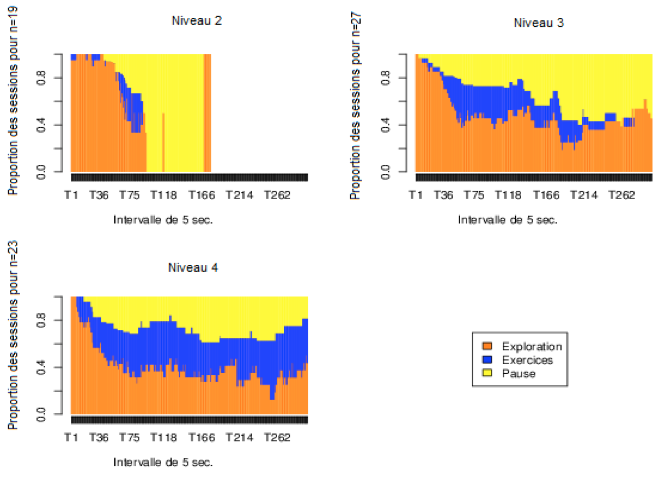
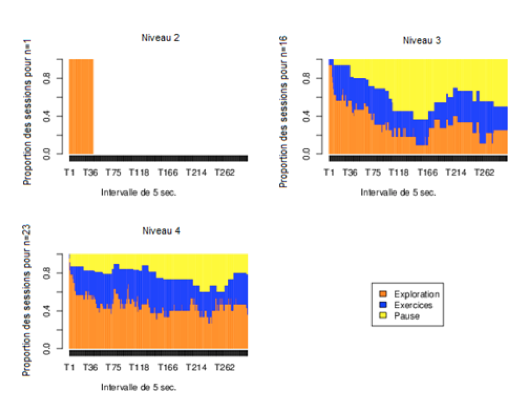
Figure 7 Niveaux d’utilisation de l’application selon 4 niveaux d’utilisation La figure 8 illustre la répartition de toutes les sessions de tous les utilisateurs regroupées par niveaux d’utilisation. Les durées des sessions correspondent à une teinte de gris exprimée en minutes dans chacune de neuf colonnes. Figure 8 • Distributions des durées de session en minutes Ainsi, les colonnes les plus pâles indiquent les durées de session plus longues. Le graphique du haut donne des durées normalisées et représente une densité proportionnelle de distribution de temps où la somme des colonnes est 1. Il permet de comparer la proportion des durées de session entre elles par niveau. Le graphique non normalisé représente des durées absolues. Il permet de comparer la durée des sessions d’un niveau à l’autre. Ainsi, on y constate que la durée des sessions augmente avec le niveau d’utilisation. Le graphique normalisé permet de constater que la durée des sessions augmente avec le niveau d’utilisation. En d’autres termes, plus l’utilisateur consacre de temps à l’application, plus la durée des sessions augmente. 6.2. Séquences d’activitésFigure 9 • Séquences d'actions par niveau d'utilisation Les analyses des séquences permettent d’afficher le déroulement d’activités en fonction du temps. Les trois graphiques de la figure 9 illustrent les séquences d’activités par session pour les trois niveaux d’utilisation 2, 3 et 4. Le niveau 1 ne comporte que des activités en mode exploration. Chaque ligne horizontale représente une session et une couleur est utilisée pour illustrer la durée de chaque type d’activité. Le temps se déroule de gauche à droite et il est divisé en au plus 300 segments de 5 secondes, soit 25 minutes chacun selon la durée des sessions. Les sessions de plus de 1 500 secondes sont tronquées dans ces graphiques. Chaque graphique comporte un échantillon aléatoire de 50 sessions pour chaque niveau d’utilisation. Le niveau 1 n’est pas affiché car les sessions sont majoritairement très courtes. Les sessions sont triées par ordre de durée. Les couleurs utilisées sont les même pour ces trois figures. Trois types d’activités sont définis : - Exploration : navigation dans les exercices ou dans les notes. - Exercices : l’utilisateur est dans le module exercice et a répondu à une question en activant bouton « Valider la réponse n.. ». - Pause : l’utilisateur était en mode Exploration mais a été inactif pendant plus de 300 secondes (5 min). L’activité « pause » est insérée 10 secondes après l’événement pour lequel la période d’inactivité a commencé. 6.3. Analyse des premières sessions et densité des activitésFigure 10 • Première session des utilisateurs Une analyse peut être faite selon la densité des activités. Dans un premier temps, pour cette analyse, la première session de chaque utilisateur est sélectionnée en ne retenant que celles dont la durée dépasse 180 s (3 minutes) et en excluant la durée pour les pauses, afin d’avoir une quantité significative d’activités. Figure 11 • Densité de la première session des utilisateurs Les 19 sessions du niveau 2 comportent une plus grande proportion d’exploration que celles des niveaux 3 et 4. À l’exception d’une d’entre elles, elles sont toutes l’unique session des utilisateurs. Environ, la moitié ont exécuté quelques exercices, mais en consacrant toujours plus de temps d’exploration que d’exercices. Le niveau 3 se compose de 27 sessions dont 11 sont les seules sessions effectuées par les étudiants de ce niveau. La figure 11 regroupe les graphiques représentant la densité d’activité, c’est-à-dire la proportion relative de chaque activité à tout moment lors de la première session. La densité s’exprime donc sur une échelle [0,1] et chaque tranche verticale représente la proportion d’activités pour un intervalle donnée. Le graphique de densité affiche une exploration au début. Par la suite, environ la moitié des utilisateurs se consacrent aux exercices, puis d’un retour vers l’exploration pour la majorité après 25 minutes (5 *× 300 s). Les étudiants du niveau 4 se consacrent plus rapidement aux exercices en moyenne et continuent d’en effectuer dans la même proportion après 25 minutes. Il faut toutefois signaler de fortes différences individuelles : certains étudiants consacrent une majorité des 25 minutes à des exercices, tandis que d’autres n’en effectuent aucun aux niveaux 3 et 4. La figure 12 et la figure 13 regroupent les mêmes graphiques pour la deuxième session des utilisateurs. On y constate qu’un seul étudiant a effectué une brève session au niveau 2, tandis que les niveaux 3 et 4 affichent des comportements relativement similaires en termes de densité d’activités, mais toujours caractérisés par de fortes différences individuelles. Certains consacrent presque la totalité des 25 minutes à l’exploration et d’autres aux exercices. On remarque aussi que certains alternent fréquemment entre les exercices et l’exploration aux niveaux 3 et 4. Figure 12 • Deuxième session des utilisateurs
Figure 13 • Densité de la deuxième session des utilisateurs La figure 14 et la figure 15 regroupent les mêmes graphiques pour la troisième session des utilisateurs. À la troisième session, seuls les niveaux 3 et 4 comportent des données. Les 27 étudiants du niveau 3 ne sont plus que 8 et ce sont les dernières sessions pour 6 d’entre eux. On constate donc un phénomène semblable à celui observé pour ceux qui arrêtent d’utiliser l’application à la première session : plusieurs terminent par de l’exploration.
Figure 14 • Troisième session des utilisateurs
Figure 15 • Densité de la troiisème session des utilisateurs
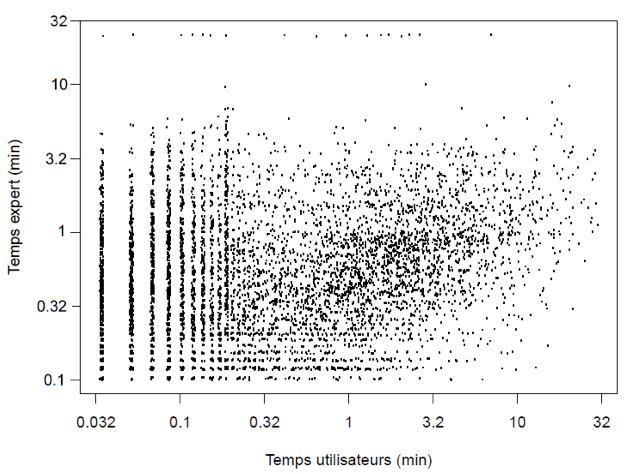
De manière générale, on constate que tous les niveaux commencent par une activité d’exploration durant quelques minutes. L’analyse des séquences démontre la pertinence de cette méthode pour visualiser rapidement et en détail les sessions des utilisateurs d’un exerciseur. Elle permet d’identifier visuellement des constances. On pourrait les mettre à profit pour définir des règles d’intervention ou simplement pour obtenir un portrait global de l’utilisation d’un exerciseur ou de toute autre application où l’on peut identifier des catégories d’activités. 7. Comparaison avec le temps d’exécution de l’expertUne des façons d’identifier des désengagements de l’utilisateur consiste à comparer le temps d’exécution des exercices avec des temps de référence (Cocea, 2011). L’écart entre les deux temps peut indiquer un désengagement (Baker, 2007) ; (Walonoski et Heffernan, 2006). Ainsi, une comparaison du temps d’exécution des exercices des utilisateurs a été faite avec celui d’un expert. Un expert a effectué l’ensemble des exercices et son temps a été enregistré. Les corrélations entre le temps de chaque étudiant et celui de l’expert sont affichées sur le graphique de la figure 16. Chaque point représente un exercice réalisé par un étudiant. Le temps de l’utilisateur est en abscisses et celui correspondant à l’expert en ordonnées. Ils sont présentés selon une échelle logarithmique. Un léger bruit gaussien a été ajouté afin de mieux distinguer les points qui se superposent. Certaines durées de l’expert sont supérieures à 1 000 s (16,6 min). À l’inverse, plusieurs temps sont inférieurs à celui de l’expert. Cette variabilité dans les durées d’exécution des exercices ne permet pas de tirer des conclusions sur la difficulté relative des exercices et encore moins sur la motivation de l’utilisateur compte tenu du volume de données disponibles.
Figure 16 • Durée d’exécution des exercices des utilisateurs et de l’expert La corrélation des temps est de 0,37 après élimination des temps 0 des utilisateurs provenant des pauses artificielles. Elle est de 0,38 en éliminant les valeurs extrêmes de plus de 1000 s et de moins de 3 s qui pourraient comporter des biais : pause ou réponse sans résolution du problème. Cette corrélation est significative (p < 0, 001) mais relativement faible pour fins de prédiction du temps d’un étudiant à partir du temps de l’expert. Même en utilisant le temps moyen par exercice et en éliminant les valeurs extrêmes, la corrélation n’atteint que 0,45 (p < 0, 0001). Ces données sont intéressantes puisqu’elles nous fournissent l’information sur le temps nécessaire pour faire les exercices et la variabilité de ce temps pour les étudiants. Il serait possible, à partir de plusieurs observations, de tenter de prédire les durées de désengagement à partir de l’écart avec le temps moyen ou le temps de l’expert car ils sont souvent un indice du désengagement (Cocea, 2011). Cependant, il n’y a pas suffisamment d’étudiants qui ont effectué des exercices pour en tirer une mesure fiable. 8. Performance au prétest et continuité d’utilisationLa continuité d’utilisation correspond à la persistance à vouloir utiliser l’application. Dans ce cas-ci, de faibles résultats au prétest devraient inciter l’étudiant à utiliser le guide d’étude. Pour valider cette hypothèse, les résultats au pré-test de mathématique parmi les étudiants qui l’ont effectué avant d’utiliser le guide peuvent être utilisés. Ces résultats sont rapportés à la figure 17 qui présente les histogrammes des notes pour chacun des niveaux d’activités. La moyenne est indiquée sous chaque histogramme. La moyenne de ceux qui ont été invités à utiliser le guide et qui ne l’ont pas fait est de 0,62. Les moyennes des niveaux 3 et 4 (0,54 et 0,47) sont donc en dessous de ceux qui n’ont pas utilisé le guide et des niveaux 1 et 2. La différence entre les niveaux est tout juste significative (F = 4, 0, dl=1, p < 0, 049).
Figure 17 Note du prétest par niveau d’utilisation On peut donc conclure qu’il y a un faible soutien pour l’hypothèse que la continuité d’utilisation est motivée par la perception qu’une mise à niveau mathématique est utile. Il y a une faible tendance en ce sens. Néanmoins, les résultats démontrent clairement que des étudiants de tous les niveaux se retrouvent dans chaque catégorie et confirment ici aussi une grande variabilité individuelle. 9. ConclusionCette étude rapporte une analyse des traces d’utilisation d’un guide d’étude comprenant un exerciseur conçu pour l’auto-apprentissage. Il a la particularité de laisser l’étudiant déterminer lui-même le résultat de résolution des problèmes choisis ainsi que de lui laisser une totale liberté d’explorer les sections théoriques et d’effectuer les exercices pratiques. Ce niveau exceptionnel d’autonomie a différentes conséquences sur l’utilisation. D’une part, il respecte la démarche d’apprentissage de l’étudiant et lui donne une très grande flexibilité d’utilisation. Cette flexibilité et cette autonomie sans contrainte a aussi des effets collatéraux et c’est possiblement ce que nous observons dans les traces. Ainsi, près de la moitié des étudiants se limitent à moins de dix minutes d’utilisation après une brève exploration. Ces étudiants prennent parfois le temps de résoudre quelques exercices, mais l’analyse des traces démontre qu’ils ne s’engagent pas à compléter les exercices des sections systématiquement. Le quart des étudiants ont suivi une démarche d’apprentissage qui dépasse deux heures. Néanmoins, un petit nombre d’étudiants complètent systématiquement l’ensemble des exercices. Une conclusion ressort cependant des résultats de la figure 17, ce n’est pas le besoin d’une mise à niveau qui est déterminant pour l’utilisation de l’exerciseur, même s’il a une certaine influence. Des améliorations pourraient être apportées au guide d’étude afin d’améliorer la continuité d’utilisation des étudiants. De nombreux facteurs interviennent dans de telles applications : la perception de l’efficacité et de l’utilité du système, le degré d’encadrement pour faciliter l’interaction avec les pairs et avec les enseignants ou l’utilisabilité de l’application (Chiu et al., 2005) ; (Kefi, 2010) ; (Lee, 2010) ; (Liaw, 2008) ; (Liaw et Huang, 2013). Les graphiques des séquences d’activités permettent de percevoir d’un coup d’œil le comportement d’un ensemble d’utilisateurs. Nous avons utilisé ce type de graphiques dans le but de détecter ce qui nous permettrait de caractériser les comportements des utilisateurs. Les graphiques révèlent la grande diversité des comportements individuels à l’intérieur des niveaux d’activités. Cela limite les possibilités de développer une mesure de classification et de prédiction du niveau d’utilisation qui permettrait de détecter ceux qui persisteront à utiliser l’application de ceux qui ne le feront pas. Des modèles plus sophistiqués, comme les modèles de Markov latents utilisés pour classifier le comportement des apprenants (Beal et al., 2007; Jeong et al., 2008) sont des pistes de recherches intéressantes. Les graphiques de visualisation de séquences d’activités s’avèrent ici des outils complémentaires au développement de ces modèles statistiques. BIBLIOGRAPHIEABBOTT, A. (1995). Sequence analysis: new methods for old ideas. Annual review of sociology, p. 93-113. ABBOTT, A. et TSAY, A. (2000). Sequence Analysis and Optimal Matching Methods in Sociology Review and Prospect. Sociological Methods & Research, 29(1), p. 3-33. AGOSTI, M., CRIVELLARI, F. et DI NUNZIO, G. (2011). Web log analysis: a review of a decade of studies about information acquisition, inspection and interpretation of user interaction. Data Mining and Knowledge Discovery, p. 1-34. AGOSTI, M. et DI NUNZIO, G. (2007). Gathering and Mining Information from Web Log Files In C. Thanos, F. Borri & L. Candela (dir.), Digital Libraries: Research and Development. (Vol. 4877, pp. 104-113): Springer Berlin / Heidelberg. ALEKS CORPORATION. (2013, 2013-04-24). About Us. About Us. Tiré de http://www.aleks.com/about_us ARMENTANO, M. et AMANDI, A. (2012). Modeling sequences of user actions for statistical goal recognition. User Modeling and User-Adapted Interaction, 22(3), p. 281-311. AZEVEDO, R. (2009). Theoretical, conceptual, methodological, and instructional issues in research on metacognition and self-regulated learning: A discussion. Metacognition and Learning, 4(1), p. 87-95. BAKER, R. (2007). Modeling and understanding students' off-task behavior in intelligent tutoring systems. Proceedings of the SIGCHI conference on Human factors in computing systems, San Jose, California, USA. BAKER, R. et YACEF, K. (2009). The State of Educational Data Mining in 2009: A Review and Future Visions. 1(1), p. 3-17. BAUDOUIN, C., BENEY, M., CHEVAILLIER, P. et LE PALLEC, A. (2007). Recueil de traces pour le suivi de l'activité d'apprenants en travaux pratiques dans un environnement de réalité virtuelle. Sciences et Technologies de l'Information et de la Communication pour l'Éducation et la Formation (STICEF), 14, 1-16. http://sticef.univ-lemans.fr/num/vol2007/07-baudouin/sticef_2008_baudouin_07.htm BEAL, C., MITRA, S. et COHEN, P. R. (2007). Modeling learning patterns of students with a tutoring system using Hidden Markov Models. Proceedings of the 2007 conference on Artificial Intelligence in Education: Building Technology Rich Learning Contexts That Work, BEAL, C., QU, L. et LEE, H. (2006). Classifying learner engagement through integration of multiple data sources. PROCEEDINGS OF THE NATIONAL CONFERENCE ON ARTIFICIAL INTELLIGENCE.(Vol. 21, pp. 151): Menlo Park, CA; Cambridge, MA; London; AAAI Press; MIT Press; 1999. BECK, J. E. (2005). Engagement tracing: using response times to model student disengagement. In C. K. Looi, G. McCalla, B. Bredeweg & J. Breuker (dir.), Artificial Intelligence in Education: Supporting Learning through Intelligent and Socially Informed Technology. (Vol. 125, pp. 88-95). Amsterdam: I O S Press. BROISIN, J. et VIDAL, P. (2007). Une approche conduite par les modèles pour le traçage des activités des utilisateurs dans des EIAH hétérogènes. Revue des Sciences et Technologies de l'Information et de la Communication pour l'Education et la Formation (STICEF), 14, p. 18 pages. CARBERRY, S. (2001). Techniques for plan recognition. User Modeling and User-Adapted Interaction, 11(1-2), p. 31-48. CHIU, C.-M., HSU, M.-H., SUN, S.-Y., LIN, T.-C. et SUN, P.-C. (2005). Usability, quality, value and e-learning continuance decisions. Computers & Education, 45(4), p. 399-416. CHOQUET, C. et IKSAL, S. (2007). Modélisation et construction de traces d'utilisation d'une activité d'apprentissage : une approche langage pour la réingénierie d'un EIAH. Revue des Sciences et Technologies de l'Information et de la Communication pour l'Education et la Formation (STICEF), 14, p. 24 pages. COCEA, M. (2011). Disengagement Detection in Online Learning: Validation Studies and Perspectives. IEEE Transactions on Learning Technologies, 4, p. 114-124. COCEA, M. et WEIBELZAHL, S. (2006). Can Log Files Analysis Estimate Learners' Level of Motivation? Lernen – Wissensentdeckung – Adaptivität (LWA), Hildesheim, Ge. COCEA, M. et WEIBELZAHL, S. (2009). Log file analysis for disengagement detection in e-Learning environments. User Modeling & User-Adapted Interaction, 19(4), p. 341-385. CONEJO, R., GUZMÁN, E., MILLÁN, E., TRELLA, M., PÉREZ-DE-LA-CRUZ, J. L. et RÍOS, A. (2004). SIETTE: A Web-Based Tool for Adaptive Testing. International Journal of Artificial Intelligence in Education, 14(1), p. 29-61. CRAM, D., JOUVIN, D. et MILLE, A. (2007). Visualisation interactive de traces et réflexivité : application à l'EIAH collaboratif synchrone eMédiathèque. STICEF, (Numéro spécial Analyse des traces d'interactions dans les EIAH), 14, p. CSIKSZENTMIHALYI, M. (2008). Flow : the psychology of optimal experience (1st Harper Perennial Modern Classicse éd.). New York: Harper Perennial. DELESTRE, N. et MALANDAIN, N. (2007). Analyse et représentation en deux dimensions de traces pour le suivi de l'apprenant. Revue des Sciences et Technologies de l'Information et de la Communication pour l'Education et la Formation (STICEF), 14, p. 21 pages. DESHPANDE, M. et KARYPIS, G. (2004). Selective Markov models for predicting Web page accesses. ACM Transactions on Internet Technology (TOIT), 4(2), p. 163-184. DESMARAIS, M., GIROUX, L. et LAROCHELLE, S. (1989). Plan recognition in HCI: the parsing of user actions. Selected papers of the 8th Interdisciplinary Workshop on Informatics and Psychology: Mental Models and Human-Computer Interaction 2.(pp. 291-311): North-Holland Publishing Co. DURBIN, R., EDDY, S. R., KROGH, A. et MITCHISON, G. (1998). Biological sequence analysis: probabilistic models of proteins and nucleic acids: Cambridge university press. EBBINGHAUS, H. (1885). Memory: A Contribution to Experimental Psychology. Classics in the History of Psychology. Consulté le 2013-02-27, Tiré de http://psychclassics.yorku.ca/Ebbinghaus/ FALMAGNE, J.-C., COSYN, E., DOIGNON, J.-P. et THIÉRY, N. (2006). The Assessment of Knowledge, in Theory and in Practice Formal Concept Analysis. (pp. 61-79). FENG, M., BECK, J., HEFFERNAN, N. et KOEDINGER, K. (2008). Can an Intelligent Tutoring System Predict Math Proficiency as Well as a Standardized Test. In Baker & Beck (Eds.). Proceedings of the First International Conference on Educational Data Mining, GABADINHO, A., RITSCHARD, G., MÜLLER, N. S. et STUDER, M. (2011). Analyzing and Visualizing State Sequences in R with TraMineR. Journal of Statistical Software, 40(4), p. 1-37. GINON, B. et JEAN-DAUBIAS, S. (2012). Prise en compte des connaissances, capacités et préférences pour une personnalisation multi-aspects des activités sur les profils d’apprenants. Revue STICEF, 9. Tiré de Internet. http://sticef.org HADWIN, A., NESBIT, J., JAMIESON-NOEL, D., CODE, J. et WINNE, P. (2007). Examining trace data to explore self-regulated learning. Metacognition and Learning, 2(2), p. 107-124. HARDY, M. E. (2004). Use and evaluation of the ALEKS interactive tutoring system. J. Comput. Small Coll., 19(4), p. 342-347. JANSEN, B. J. (2009). Understanding User-Web Interactions via Web Analytics. Synthesis Lectures on Information Concepts, Retrieval, and Services, 1(1), p. 1-102. JARUŠEK, P. et PELÁNEK, R. (2012) Analysis of a simple model of problem solving times. 11th International Conference on Intelligent Tutoring Systems, ITS 2012: Vol. 7315 LNCS (pp. 379-388). Chania, Crete. JEAN-DAUBIAS, S., GINON, B. et LEFEVRE, M. (2011). Modèles et outils pour prendre en compte l'évolutivité dans les profils d'apprenants. STICEF, 18, p. 23. JEONG, H., GUPTA, A., ROSCOE, R., WAGSTER, J., BISWAS, G. et SCHWARTZ, D. (2008). Using Hidden Markov Models to Characterize Student Behaviors in Learning-by-Teaching Environments. In B. Woolf, E. Aïmeur, R. Nkambou & S. Lajoie (dir.), Intelligent Tutoring Systems. (Vol. 5091, pp. 614-625): Springer Berlin Heidelberg. KEFI, H. (2010). Mesures perceptuelles de l'usage des systèmes d'information : Application de la théorie du comportement planifié. Cahiers de Recherche du CEDAG(G 2010 - 04), p. 21. KÖCK, M. et PARAMYTHIS, A. (2011). Activity sequence modelling and dynamic clustering for personalized e-learning. User Modeling and User-Adapted Interaction, 21(1), p. 51-97. KOEDINGER, K., ANDERSON, J., HADLEY, W. et MARK, M. (1995). Intelligent Tutoring Goes to School in the Big City. Proceedings of the 7th World Conference on {AIED}, p. KOSALA, R. et BLOCKEEL, H. (2000). Web mining research: A survey. ACM SIGKDD Explorations Newsletter, 2(1), p. 1-15. LEE, M.-C. (2010). Explaining and predicting users’ continuance intention toward e-learning: An extension of the expectation–confirmation model. Computers & Education, 54(2), p. 506-516. LI, C. et YOO, J. (2006). Modeling student online learning using clustering. Proceedings of the 44th annual Southeast regional conference.(pp. 186-191): ACM. LIAW, S.-S. (2008). Investigating students’ perceived satisfaction, behavioral intention, and effectiveness of e-learning: A case study of the Blackboard system. Computers & Education, 51(2), p. 864-873. LIAW, S.-S. et HUANG, H.-M. (2013). Perceived satisfaction, perceived usefulness and interactive learning environments as predictors to self-regulation in e-learning environments. Computers & Education, 60(1), p. 14-24. LINDEN VAN DER, W. J., SCRAMS, D. J. et SCHNIPKE, D. L. (1999). Using Response-Time Constraints to Control for Differential Speededness in Computerized Adaptive Testing. Applied Psychological Measurement, 23(3), p. 195-210. MCMILLAN, J. H. et HEARN, J. (2008). Student Self-Assessment: The Key to Stronger Student Motivation and Higher Achievement. Educational Horizons, 87(1), p. 40-49. MERCERON, A. et YACEF, K. (2005). TADA-Ed for Educational Data Mining. Interactive Multimedia Electronic Journal of Computer-Enhanced Learning, 7(1). http://www.imej.wfu.edu/articles/2005/1/03/index.asp PERRY, N. E. et WINNE, P. H. (2006). Learning from Learning Kits: gStudy Traces of Students’ Self-Regulated Engagements with Computerized Content. Educational Psychology Review, 18(3), p. 211-228. QIQI, J., CHUAN-HOO, T., CHEE WEI, P. et WEI, K. K. (2012). Using Sequence Analysis to Classify Web Usage Patterns across Websites. System Science (HICSS), 2012 45th Hawaii International Conference on.(pp. 3600-3609). RITTER, F. E. et SCHOOLER, L. J. (2001). Learning Curve, The. In J. S. Editors-in-Chief: Neil & B. B. Paul (dir.), International Encyclopedia of the Social & Behavioral Sciences. (pp. 8602-8605). Oxford: Pergamon. SCHRAW, G. (2007). The use of computer-based environments for understanding and improving self-regulation. Metacognition and Learning, 2(2), p. 169-176. SNODDY, G. S. (1926). Learning and stability: a psychophysiological analysis of a case of motor learning with clinical applications. Journal of Applied Psychology, 10(1), p. 1-36. SRIVASTAVA, J., COOLEY, R., DESHPANDE, M. et TAN, P.-N. (2000). Web usage mining: Discovery and applications of usage patterns from web data. ACM SIGKDD Explorations Newsletter, 1(2), p. 12-23. STAMPER, J., LOMAS, DEREK, CHING, D., RITTER, S., KOEDINGER, K. et STEINHART., J. (2012). The Rise of the Super Experiment Proceedings of the 5th International Conference on Educational Data Mining., Chania, Greece. http://educationaldatamining.org/EDM2012/uploads/procs/EDM_2012_proceedings.pdf TAN, K. H. K. (2012). Student self-assessment : assessment, learning and empowerment. Singapore: Research Publishing. TARABAN, R., RYNEARSON, K. et STALCUP, K. (2001). Time as a variable in learning on the World-Wide Web. Behavior Research Methods, 33(2), p. 217-225. THOMPSON, J. J., YANG, T. et CHAUVIN, S. W. (2009). Pace: An Alternative Measure of Student Question Response Time. Applied Measurement in Education, 22(3), p. 272-289. TOLLE, J. E. (1983). Transaction log analysis online catalogs. SIGIR Forum, 17(4), p. 147-160. VENABLES, W. N., SMITH, D. M. et TEAM, R. D. C. (2012). An Introduction to R: Notes on R: a Programming Environment for Data Analysis and Graphics, Version 2.15.1: Network Theory. WALONOSKI, J. et HEFFERNAN, N. (2006). Detection and Analysis of Off-Task Gaming Behavior in Intelligent Tutoring Systems. Intelligent Tutoring Systems. In M. Ikeda, K. Ashley & T.-W. Chan (dir.). (Vol. 4053, pp. 382-391): Springer Berlin / Heidelberg. WANG, T. et HANSON, B. A. (2005). Development and Calibration of an Item Response Model That Incorporates Response Time. Applied Psychological Measurement, 29(5), p. 323-339. WINNE, P. H., NESBIT, J. C., KUMAR, V., HADWIN, A. F., LAJOIE, S. P., AZEVEDO, R. et PERRY, N. E. (2006). Supporting self-regulated learning with gStudy software : The learning kit project. Tech., Inst., Cognition and Learning, 3 :, . Technology, Instruction, Cognition and Learning, 3(1-2), p. 105-113. WISE, S. L. et KONG, X. (2005). Response Time Effort: A New Measure of Examinee Motivation in Computer-Based Tests. Applied Measurement in Education, 18(2), p. 163-183. WRIGHT, T. P. (1936). Factors Affecting the Cost of Airplanes. Journal of Aeronautical Sciences, 3, p. 122-128.
| |||||||||||||||||||||||||
Référence de l'article :François LEMIEUX, Michel C. DESMARAIS, Pierre-N. ROBILLARD, Analyse chronologique des traces journalisées d’un guide d’étude pour apprentissage autonome, Revue STICEF, Volume 20, 2013, ISSN : 1764-7223, mis en ligne le 11/03/2014, http://sticef.org |













© Revue Sciences et Techniques de l'Information et de la Communication pour l'Éducation et la Formation, 2013