de l´Information et
de la Communication pour
l´Éducation et la Formation
version à télécharger (pdf)
Volume 12, 2005
Article de recherche
|
Contact : infos@sticef.org |
Un Environnement Informatique pour l'Apprentissage Humain au service de la Virtualisation des Objets Pédagogiques
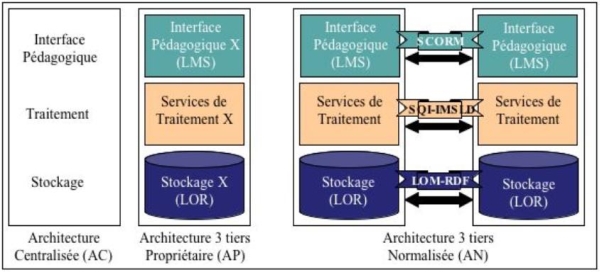
1. IntroductionAu milieu des années 90, plusieurs études convergeaient en affirmant que des changements technologiques de plus en plus fréquents seraient à l'origine du besoin de formation des entreprises. Par voie de conséquence, le domaine de la formation continue et celui de la formation en entreprise deviendraient un des domaines d'activité dont le taux de croissance serait parmi les plus élevés au tournant du siècle. Aujourd'hui, la Formation Ouverte et A Distance (FOAD) est de plus en plus répandue aussi bien dans les institutions publiques que privées, mais elle est loin de représenter une méthode d'apprentissage utilisée par tous. Un moyen de contribuer à son développement est de mettre à disposition des utilisateurs une masse importante d'objets pédagogiques de natures variées tant au niveau des domaines d'apprentissage visés que du type de supports numériques utilisés, ainsi que de la langue dans laquelle ils sont produits. Dans le domaine de la FOAD, l'émergence de standards laisse entrevoir la possibilité d'atteindre des solutions de fédération nous amenant à partager et à réutiliser les ressources pédagogiques. Nous parlons ainsi de virtualisation des objets pédagogiques contribuant à l'utilisation de masse de la FOAD. ''La virtualisation fournit une vue globale de l'ensemble des ressources disponibles sur un réseau et en facilite l'accès indépendamment de leur emplacement'' (Gimont, 2003) (Guangzuo, 2003). Dans le cas d'un système de formation à distance, elle permet de mettre à disposition des utilisateurs un nombre considérable de ressources pédagogiques tout en leur facilitant la recherche, l'acquisition, et la mise à disposition de ce matériel pédagogique. Dans ce document, nous distinguons clairement deux objectifs à réaliser pour atteindre la virtualisation des objets pédagogiques, respectivement la fédération des objets pédagogiques stockés dans différents viviers de connaissance (ainsi que des services qui y sont associés), et l'intégration de cette fédération au sein de plates-formes de gestion d'apprentissage. Nous présentons un Environnement Informatique pour l'Apprentissage Humain qui favorise le partage et la réutilisation du matériel pédagogique par la mise en œuvre de la virtualisation des objets pédagogiques. ''Un Environnement Informatique pour l'Apprentissage Humain (EIAH) est un environnement informatique conçu dans le but de favoriser l'apprentissage humain, c'est-à-dire la construction de connaissances chez un apprenant'' (Tchounikine, 2002). Nous utiliserons dans cet article le terme EIAH pour dénoter un système d'apprentissage (un ''EIAH'') mais également le domaine de recherche correspondant (l'''EIAH''). Dans notre EIAH, la fédération d'une multitude de ressources pédagogiques stockées dans des viviers de connaissance distincts est transparente aux utilisateurs ; bien que les systèmes demeurent des entités indépendantes, ils représentent une vue virtuelle unique leur permettant d'être interrogés et utilisés simultanément comme s'ils constituaient une entité unique. Toutes les ressources accessibles à travers la fédération sont contextualisées pour l'apprentissage à distance par l'usage de métadonnées, et directement utilisables par des indexeurs, étudiants, enseignants, mais aussi et surtout par les plates-formes de gestion d'apprentissage, ou Learning Management System (LMS). Dans cette optique, une interface de programmation d'applications, ou Application Programming Interface (API), offre une intégration des objets pédagogiques au sein de différents LMS. Nous exposons dans la deuxième partie les différentes évolutions des architectures des EIAH afin de mettre en évidence les barrières à franchir pour atteindre la virtualisation des ressources pédagogiques. Nous proposons dans la troisième partie une architecture structurée en couches pour le support de notre EIAH qui prend en compte des normes et standards en cours d'élaboration dans le domaine de la FOAD ; nous nous attacherons à détailler les deux niveaux de l'architecture qui mettent en œuvre les fonctionnalités et services nécessaires à la virtualisation. Dans la quatrième partie, nous présentons deux expérimentations déployées avec des LMS distincts qui sont actuellement en phase de test au sein d'un projet international et d'un projet local à notre université et qui valident l'architecture proposée. Les expérimentations démontrent également comment notre EIAH permet de bénéficier du contexte d'apprentissage de la plate-forme d'enseignement pour faciliter le processus d'indexation d'un nouvel objet pédagogique au sein d'un vivier de connaissance, ou Learning Object Repository (LOR), encourageant ainsi les acteurs impliqués dans ce mécanisme à décrire les ressources pédagogiques qu'ils indexent. Enfin, nous exposons dans la dernière partie de ce document les futurs travaux qui contribueront à l'amélioration de notre environnement d'apprentissage avant d'élargir nos perspectives de recherche. 2. Evolution des architectures des EIAH2.1 IntroductionLors de l’apparition de la Formation Ouverte et A Distance, trois fonctionnalités vitales ont été mises en avant pour la mise en œuvre d’un EIAH (Paquette, 2000): un moyen de stockage des ressources pédagogiques produites, un ensemble de services offrant des opérations de traitement sur ces ressources pédagogiques, et une interface dédiée à l’apprentissage à travers des fonctionnalités spécialisées qui exploitent les services disponibles sur les ressources d’apprentissage d'une part, et qui proposent des fonctionnalités de gestion inter-acteurs d'autre part. Les premiers systèmes proposaient une application centralisée réalisant l’ensemble de ces fonctionnalités (Figure 1– AC) (OWASIS, 2001), mais ce type d’architecture cloisonnée n’autorise aucun partage ou réutilisation des outils et matériels disponibles.
Figure 1 : Evolution des architectures des EIAH Les acteurs de la FOAD se sont rapidement rendus compte de la nécessité de dissocier ces fonctionnalités, c’est-à-dire de décomposer un EIAH en un ensemble complémentaire d’outils, chacun se focalisant sur une tâche spécifique. Ces ensembles de briques pourraient alors être réutilisées indépendamment les unes des autres. Les systèmes conçus au sein d’une même institution étaient destinés aux seuls membres de l’organisation, et mettaient en œuvre des solutions propriétaires qui n’avaient pas pour vocation de s’ouvrir vers les autres EIAH existants (Figure 1– AP) (Forte et al., 1996). De nombreuses initiatives de normalisation sont alors apparues (Vidal et al., 2003), qui ont permis à des systèmes d’intégrer d’autres environnements existants, mais sous la condition qu’ils respectent les mêmes spécifications (Figure 1 – AN) (CANCORE, 2000). 2.2. Composants et standards associésPour chacun des trois niveaux de l’architecture, de nombreuses normes et standards ont émergé ces dernières années. Nous évoquons ici ceux qui sont les plus aboutis et largement répandus au sein des EIAH. 2.2.1 Viviers de connaissance et LOMAu niveau du stockage des objets pédagogiques, les viviers de connaissance fournissent un moyen transparent pour partager et réutiliser des objets pédagogiques. Ces systèmes renferment de véritables objets pédagogiques, c'est-à-dire à la fois les documents eux-mêmes mais également les métadonnées décrivant ces ressources pédagogiques. Les métadonnées fournissent un moyen pour catégoriser et indexer des ressources d'apprentissage, facilitant ainsi leur recherche et leur réutilisation (Moore, 2001). Différents modèles de métadonnées sont actuellement implémentés au sein des viviers de connaissance (Vidal et al., 2004), incluant le Dublin Core Metadata Set (DC, 1995) ou le standard Learning Object Metadata (LOM) de l'IEEE (Ieee, 2002). Une distinction doit être faite entre les viviers de connaissance (LOR) qui contiennent des objets pédagogiques (documents numériques ET métadonnées) et les viviers de métadonnées d'objets pédagogiques (Learning Object reFeratory, LOF) qui renferment uniquement les métadonnées, les objets consistant en une URL (Uniform Resource Locators) représentée par un champ du modèle de métadonnées. 2.2.2 Services de traitement et SQIUn ensemble de services est nécessaire pour effectuer des opérations de traitement sur les objets pédagogiques dans le cas des LOR, et sur les métadonnées uniquement dans le cas des LOF. Jusqu'à présent, la majorité des services proposés étaient spécifiques à un LOR(F) particulier, obligeant les développeurs à connaître les spécifications des méthodes propres à chaque LOR(F). Ainsi, une initiative de standardisation nommée Simple Query Interface (SQI) (Simon et al., 2004) a pour objectif de spécifier un ensemble d'opérations qui permettent d'interroger des viviers hétérogènes de métadonnées pédagogiques (LOR et LOF). Ses principales caractéristiques sont les suivantes : simplicité et facilité d'implémentation, neutralité en termes de langages de requête et de formats de résultat, support des requêtes en mode synchrone ou asynchrone. 2.2.3 Plates-formes de gestion d'apprentissage et SCORMDe nombreuses plates-formes de gestion d'apprentissage, ou LMS, existent aujourd'hui mais nous constatons cependant que la majorité d'entre elles stockent leurs ressources pédagogiques au sein d'espaces dédiés, les empêchant de communiquer, d'échanger et de réutiliser du matériel pédagogique puisque les ressources sont enfermées ''dans la boîte''. Pour pallier à cette restriction, le modèle SCORM (Sharable Content Object Reference Model) (Scorm, 2004) définit des règles régissant l'instauration d'un modèle d'agrégation de contenus et d'environnement d'exécution pour les objets d'apprentissage sur le Web. Son organisation respecte certains critères tels que la durabilité, l'interopérabilité, l'accessibilité, et la réutilisation de contenus à partir de différents outils d'apprentissage (Arapi et al., 2003). 2.3. Verrous à leverMalgré les efforts de normalisation qui prétendent apporter une solution universelle pour le partage et la réutilisation du matériel pédagogique, nous constatons que les solutions d’intégration de différents systèmes basés sur l’architecture AN de la Figure 1 sont souvent limitées à une intégration point-à-point entre deux systèmes particuliers (Friesen et Mazloumi, 2004). Pour être en mesure de fédérer les ressources pédagogiques réparties dans différents viviers et de les rendre accessibles à différentes plates-formes d'apprentissage, nous avons introduit une couche intermédiaire de virtualisation qui encapsule l’hétérogénéité cohabitante et persistante des solutions existantes (Vidal et Broisin, 2005). Ce niveau supplémentaire doit prendre en compte certaines exigences : Etre capable d’intégrer l’ensemble des solutions hétérogènes existantes tout en prenant en compte le caractère distribué des composants d’un EIAH. Etre transparent à l'utilisateur final ; un mécanisme capable d’identifier les composants impliqués dans la collaboration ainsi que d'authentifier les utilisateurs de ces systèmes est nécessaire. Offrir des services tels que la recherche, le téléchargement, l'importation, ou l'indexation de ressources pédagogiques au sein des différents composants. Dans la section suivante, nous suggérons une architecture qui introduit cette couche de Virtualisation dans l’architecture AN (Figure 1). 3. Virtualisation des Ressources Pédagogiques3.1. Architecture de virtualisation
Figure 2 : Une architecture pour la virtualisation des ressources pédagogiques Nous proposons ici une architecture structurée en couches, technique de décomposition largement utilisée dans le développement logiciel pour augmenter la réutilisation et l’interopérabilité des composants. Nous avons introduit un niveau supplémentaire à l’architecture normalisée (Figure 1), ce qui donne une architecture globale divisée en quatre niveaux illustrés sur la Figure 2. La couche de Virtualisation, divisée en deux sous-couches, offre une virtualisation des objets pédagogiques : la couche de Fédération permet de retrouver et d'exploiter les objets pédagogiques stockés dans des viviers de connaissances hétérogènes en invoquant les services rendus par la couche Services de Traitement, alors que la couche d'Intégration a pour objectif de rendre facilement disponibles les services de la couche de Fédération aux systèmes inclus dans la couche Interfaces Pédagogiques. L'intégration de ces services doit être transparente pour l'utilisateur final, tandis que l'interface de fédération des ressources doit être claire et simple d’utilisation afin de masquer la complexité du système global. Dans la mesure où les couches Stockage et Interfaces Pédagogiques ont été évoquées dans la deuxième partie, nous détaillons maintenant les couches d'Intégration et de Fédération permettant la mise en œuvre de la virtualisation des objets pédagogiques. 3.2. Couche de FédérationComme nous l'avons évoqué dans la section 2.2.3, la majorité des LMS stocke les ressources pédagogiques au sein d'un espace disque dédié, la plupart du temps sans métadonnées associées, ou du moins sans métadonnées permettant à l'utilisateur final d'identifier du matériel pertinent à son contexte. En section 2.2.1, nous avons présenté l'intérêt des viviers de connaissance qui permettent le stockage d'objets pédagogiques (documents ET métadonnées) tout en fournissant un environnement transparent pour partager et réutiliser ces ressources. Toutefois, ces objets pédagogiques stockés dans des systèmes isolés ne sont pas utiles à l'apprentissage s'ils ne peuvent pas être déployés sur des plates-formes d'enseignement. Aujourd'hui, la plupart des institutions publiques et privées possèdent un système similaire à des plates-formes d'apprentissage (Paulsen, 2003), alors certains services doivent leur permettre d'interagir avec les différents viviers de connaissance existants de façon transparente : un service doit permettre de rechercher des objets pédagogiques dans différents viviers, un autre service doit permettre de télécharger/importer des documents existants externes, et un service doit supporter l'indexation de nouvelles ressources dans un vivier particulier (Broisin et al., 2005a). 3.2.1 Service de recherche des objets pédagogiquesLe service de recherche des objets pédagogiques a pour but d'offrir une vue unique de l'ensemble des ressources stockées dans différents LOR afin de favoriser l’échange et la réutilisation par tous de ces ressources pédagogiques. C'est ce service qui permet de réaliser la première étape de la virtualisation des ressources pédagogiques.
Figure 3 : Diagramme d'activités du processus d'obtention d'objets pédagogiques (Massart, 2005)
Figure 4 : Scénario de recherche des ressources pédagogiques Le processus d'obtention d'un objet pédagogique illustré par la Figure 3 consiste à : (1) chercher et évaluer les métadonnées : sélectionner un objet pédagogique qui satisfait la requête de l'utilisateur. Cette étape peut être répétée dans le but de raffiner la recherche et de trouver les objets pédagogiques appropriés. (2) localiser l'objet pédagogique : selon la nature du vivier de connaissance (LOR ou LOF), la localisation de l'objet est indiquée par une référence (utilisable seulement dans le contexte du vivier) ou par une URL. (3) consommer l'objet pédagogique : exploiter l'objet pédagogique à partir de sa localisation. Pour réaliser les première et deuxième étapes du processus d'obtention d'un objet pédagogique, le service de recherche exploite les services de traitement respectant la spécification SQI déployés sous la forme de services Web et qui sont associés à chacun des viviers de connaissance fédérés. L'ensemble des méthodes implémentées permet d'obtenir les métadonnées ainsi que la localisation des objets pédagogiques sous la forme d'un champ de métadonnées (référence ou URL). La Figure 4 illustre le diagramme de séquence UML correspondant aux différentes phases nécessaires à la recherche et à la localisation des objets pédagogiques : 1. Critères de recherche : à travers l'interface de la couche de Fédération (Figure 6), l'utilisateur connecté au LMS spécifie d'une part un ensemble de mots-clés décrivant les documents recherchés, et d'autre part les viviers dans lesquels il souhaite effectuer la recherche. 2. Authentification : le service de recherche invoque la méthode createAnonymousSession du service de traitement SQI associé au vivier cible qui retourne un identifiant de session sous forme d'une chaîne de caractères. Cet identifiant est un élément obligatoire pour identifier les systèmes dans toutes les communications sous-jacentes. 3. Négociation du contexte : le service de recherche, en invoquant les méthodes setQueryLanguage et setResultsFormat, définit respectivement le langage de requête qui sera utilisé lors des communications sous-jacentes ainsi que le format de résultat correspondant au modèle de métadonnées décrivant les ressources pédagogiques. 4. Envoi de la requête et réception des résultats : dans un premier temps, le service de recherche construit la requête correspondant aux critères de recherche et invoque la méthode synchronousQuery du service de traitement SQI cible qui effectuera la recherche des métadonnées au sein du LOR fédéré. Ce service retourne ensuite à la couche de Fédération les métadonnées des objets pédagogiques satisfaisant les critères de la requête sous la forme d'une chaîne de caractères. 5. Formatage des résultats : lorsque le service de recherche obtient les résultats de la requête, un mécanisme de mise en forme des métadonnées est effectué afin de proposer à l'utilisateur final une interface claire et simplifiée. 6. Affichage des résultats : après la mise en forme des résultats, l'interface de la couche de Fédération propose à l'utilisateur final une liste des objets pédagogiques retrouvés ainsi que leurs métadonnées associées. Seul le titre du document est directement visible, mais un hyperlien sur ce titre permet de visualiser l'ensemble des métadonnées de la ressource (Figure 6). Lorsque l'utilisateur dispose d'une vue unique des ressources stockées dans différents viviers, des services doivent lui être offerts afin qu'il puisse consommer le document correspondant, c'est-à-dire le télécharger ou l'intégrer au sein de la plate-forme d'apprentissage. 3.2.2 Services de téléchargement et d'importationLe service de recherche nous permet d'obtenir les métadonnées associées à un document pédagogique particulier. Dans la mesure où l'une d'entre elles correspond à la localisation des ressources pédagogiques, deux services ont été mis en œuvre : Téléchargement du document sur le poste local : dans le cas d'un LOF, le service de téléchargement permet de visualiser l'URL associée à l'objet pédagogique alors que dans le cas d'un LOR, le document est véritablement importé sur le poste local grâce au service de traitement spécifique au vivier cible. Intégration du document au sein de la plate-forme d'apprentissage : dans le cas d'un LOF, l'URL associée à l'objet pédagogique est attribuée à la valeur de la localisation de la ressource au sein du LMS (Figures 9 et 10) alors que dans le cas d'un LOR, le document est recopié au sein de l'espace dédié dans le répertoire correspondant. Deux hyperliens qui permettent à l'utilisateur final d'accéder aux services de téléchargement et d'intégration sont associés à chaque objet pédagogique (Figure 6). Alors que le téléchargement sur le poste local est indépendant de la plate-forme d'apprentissage cible, l'intégration est fortement liée au LMS puisque la couche de Fédération doit connaître le répertoire destiné au stockage de la ressource pédagogique ; l'identification de cette propriété est déterminée à partir des informations fournies par la couche d'Intégration qui sont détaillées dans la section 3.3.2. Certains viviers de connaissance n'offrent pas la possibilité d'obtenir l'intégralité des documents pédagogiques librement, comme c'est le cas du Knowledge Pool System (KPS) (Duval et al., 2001) de la Fondation Ariadne (ARIADNE, 1996). Dans ce cas, un mécanisme d'authentification est mis en oeuvre afin de connaître les droits des utilisateurs vis-à-vis du vivier de connaissance ; ce mécanisme est présenté dans la section 4.2.2. 3.2.3 Service d'indexationUn service supplémentaire de la couche de Fédération permet d'insérer de nouveaux objets pédagogiques à la fois dans l'espace dédié du LMS, mais aussi dans un vivier de connaissance afin de rendre les ressources accessibles à d'autres systèmes. Dans un premier temps, l'interface de ce service permet à l'utilisateur de choisir un document résidant sur son disque local afin de l'insérer dans l'espace dédié du LMS grâce aux informations fournies par la couche d'Intégration. A travers un vaste formulaire électronique décrivant le standard de métadonnées implémenté dans le vivier cible, l'utilisateur doit ensuite renseigner l'ensemble des métadonnées requises pour l'insertion d'un nouvel objet pédagogique dans le vivier cible. Lorsque l'ensemble des champs obligatoires du formulaire sont remplis, le service d'indexation invoque le service de traitement responsable de la gestion du vivier cible qui insèrera les métadonnées et le document au sein du système. Ce service est également réservé à certains utilisateurs, donc le mécanisme exposé dans la section 4.2.2 est de nouveau mis en œuvre. Ce processus d'indexation est fastidieux et la majorité des acteurs de la FOAD ne prennent pas le temps de générer des métadonnées ; pour les autres, des problèmes de consistance et de fiabilité peuvent apparaître (Jenkins et al., 1999). Pourtant, les objets pédagogiques (documents ET métadonnées) jouent un rôle prédominant au sein d'un EIAH (Michau et Poix, 2003). Alors pour lever ce verrou et favoriser la mise à disposition de nouvelles ressources d'apprentissage, la couche de Fédération offre un service complémentaire au service d'indexation qui permet de générer automatiquement la majorité des métadonnées nécessaires à l'indexation d'un objet pédagogique dans un vivier de connaissance. 3.2.4 Service de génération automatique de métadonnéesDans l'optique de générer automatiquement les métadonnées les plus importantes lors de l'indexation d'un objet pédagogique, un service de la couche de Fédération détaillé dans la section 4.4 permet d'extraire des informations liées au contexte de la plate-forme d'apprentissage et de les faire correspondre à des attributs du modèle de métadonnées implémenté au sein du LOR, réduisant ainsi le nombre de champs à remplir manuellement (Broisin et al., 2005b). En effet, la plupart des LMS demandent aux créateurs de formations de décrire brièvement le sujet relatif au cursus qu'ils définissent, c'est-à-dire de déterminer un ensemble de mots clés et de termes en relation avec le sujet du cursus. Ces termes représentent une forme de métadonnées qui peuvent être utilisées pour alléger le processus d'indexation. D'autres métadonnées peuvent être déduites à partir du nom et de l'extension du fichier associé au nouvel objet pédagogique à indexer. La qualité de ce service dépend fortement de l'adoption d'un standard commun pour déployer les ressources pédagogiques, permettant ainsi aux auteurs d'objets pédagogiques de développer du matériel indépendant des plates-formes. La couche de Fédération permet donc de réaliser la première étape de la virtualisation des objets pédagogiques puisqu'elle fournit une vue unique des ressources stockées au sein de différents LOR ; elle fournit aussi un ensemble de services qui permettent d'exploiter ces ressources. Nous exposons maintenant la couche d'Intégration qui offre un accès facilité à ces ressources à partir d'un LMS et qui permet d'aboutir à la virtualisation des objets pédagogiques. 3.3. Couche d'intégrationLa couche d'Intégration joue deux rôles bien distincts : d'une part elle permet à l'utilisateur final d'atteindre la couche de Fédération ainsi que les services qui lui sont associés, et d'autre part elle fournit à cette même couche de Fédération les informations nécessaires à la réalisation du service d'importation des ressources externes au sein du LMS. 3.3.1 Lien entre le LMS et la couche de FédérationLa couche d'Intégration permet à un utilisateur connecté à la plate-forme d'apprentissage d'accéder facilement aux ressources retrouvées par les services de Fédération. Les services proposés par les LMS sont plus ou moins avancés mais l'opportunité d'insérer un nouveau document au sein de l'espace dédié est toujours offerte. Nous avons donc ajouté un hyperlien vers la couche de Fédération dans l'espace de travail dédié à l'insertion de nouveaux documents (Figures 9 et 10). Ainsi, le déploiement de la couche d'Intégration au sein d'un LMS est très aisé car (a) peu de pages ont besoin d'être modifiées, et (b) repérer l'espace de travail correspondant est très rapide. D'autre part, plusieurs contraintes sont satisfaites : pour l'administrateur, le déploiement de la couche de Virtualisation au sein de la plate-forme cible est simple à réaliser : un fichier doit être mis à jour afin d'ajouter l'hyperlien vers la couche de Fédération, et un nouveau répertoire correspondant aux services de Fédération doit être ajouté dans l'arborescence de la plate-forme cible. pour les créateurs de cursus, le déploiement de ressources stockées dans des LOR distants est facile à réaliser puisque notre approche présente une méthodologie similaire à celle mise en œuvre pour le déploiement de ressources internes au LMS. la couche de Virtualisation est facilement adaptable à différents LMS cibles puisque notre approche n'est pas fortement liée à une plate-forme particulière, comme le montre la section suivante. 3.3.2 Fournisseur d'informationsAfin de rendre la couche de Fédération la plus indépendante et générique possible, le nombre de variables spécifiques au LMS et nécessaires à la bonne conduite des services de Fédération doit être aussi faible que possible. L'intégration ne se rapporte qu'à la gestion du matériel pédagogique et nécessite l'identification de seulement trois caractéristiques : le nom de l'utilisateur connecté au LMS afin de contrôler ses droits d'usage relatifs aux LOR. le chemin du répertoire racine correspondant à l'espace dédié au stockage du matériel pédagogique au sein du LMS. l'identifiant du répertoire de la formation en cours afin de savoir où stocker les ressources au sein du répertoire racine. Ces trois variables spécifiques au LMS peuvent être obtenues facilement : le nom de l'usager connecté (son ''login'') est très souvent stocké dans une variable Session, le répertoire racine est soit identique, soit spécifique pour chaque instance du LMS (dans le dernier cas, il figure dans un fichier de configuration), et l'identifiant du répertoire de la formation en cours correspond à une variable visible dans la barre d'adresse du navigateur. Lorsqu'un utilisateur cherche à accéder aux services de Fédération, la couche d'Intégration prend connaissance de ces trois caractéristiques et les transmet à la couche de Fédération qui est alors en mesure d'assurer l'ensemble des services présentés dans la section 3.2. L'architecture proposée offre une vue unique de ressources pédagogiques réparties dans des viviers de connaissance distincts ainsi qu'un accès facilité à celles-ci à travers les plates-formes d'apprentissage : elle permet donc de mettre en œuvre la virtualisation des objets pédagogiques qui favorise le partage et la réutilisation du matériel pédagogique. Nous exposons dans la partie suivante les expérimentations réalisées qui valident cette architecture et qui sont déployées au sein d'un projet international et d'un projet local à notre Université. 4. Expérimentations
Figure 5 : Architecture de virtualisation des ressources pédagogiques Nous exposons ici deux expérimentations qui intègrent la couche de Virtualisation. La communication entre les composants de l'EIAH repose sur un ensemble de services Web. Cette technologie de Middleware bénéficie, à l'instar des Middleware orientés objet, de son ouverture et de son étendue basées sur des standards communs tels que XML ou HTTP, de sa capacité à ''traverser'' les pares-feu grâce au protocole de transport utilisé (HTTP), et de sa facilité d'utilisation grâce aux multiples outils existants (Barron et Rickelman, 2001). La couche de Virtualisation étant destinée à intégrer des plates-formes d'enseignement implémentant le langage PHP, elle a été développée avec ce langage et s'appuie sur la bibliothèque NuSOAP (NUSOAP, 2002). 4.1. Fédération des viviers ARIADNE, MERLOT et LRC
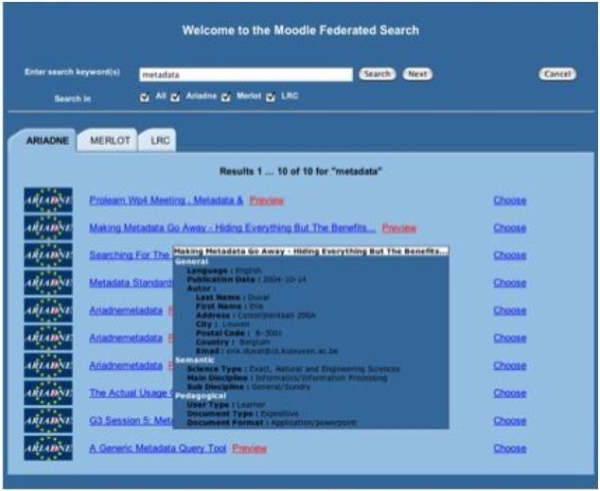
Figure 6 : Interface de la couche de Fédération Nous avons expérimenté le scénario présenté dans la section 3.2.1 entre un LOR et deux LOF basés sur le standard LOM pour le format de métadonnées, respectivement le KPS de la Fondation Ariadne, et les LOF MERLOT (MERLOT, 1997) et Learning Resource Catalog (LRC) (LRC, 2003). Ces trois viviers de connaissance sont étudiés dans le cadre de nos travaux au sein de la Fondation Ariadne et de groupes de travail définis par le réseau d'excellence Prolearn dans lesquels nous sommes impliqués. Pour être capable de rechercher des ressources dans le KPS et MERLOT, nous invoquons des services Web qui implémentent la spécification SQI et qui ont été développés par l'Université Katholique de Leuven (KUL, 2005). En revanche, le LRC dispose d'une API proposant un ensemble spécifique de méthodes qui ne respectent pas SQI. Afin de proposer une solution homogène, une cible SQI établissant la correspondance entre les méthodes des services de l'API du LRC et les spécifications SQI a été mise en place. La Figure 6 illustre le résultat d'une requête portant sur le mot clé "metadata" exécutée dans les trois LOR fédérés ; un click sur le titre d'un document permet de consulter les métadonnées qui lui sont associées. L'interface expérimentale de recherche masque à l'utilisateur final la complexité du système mis en œuvre et propose une vue unique de toutes les ressources disponibles dans les viviers fédérés. Notre moteur de recherche inspiré de ''Google'' permet de réaliser le processus d'obtention d'un objet pédagogique puisqu'il permet de rechercher les métadonnées pertinentes pour des critères de recherche, de les consulter, et de localiser les documents pédagogiques correspondants. Les utilisateurs finaux ont alors la possibilité de télécharger ou d'importer des ressources externes grâce aux services de la couche de Fédération. 4.2. Téléchargement et importation de ressources externesLes liens "Preview" et "Choose" (Figure 6) permettent d'invoquer respectivement les services de téléchargement et d'importation d'une ressource au sein de la plate-forme dans le cursus courant. Dans le cas du LOR Ariadne, l'ensemble des métadonnées peut être consulté librement mais l'accès à certains documents est limité à des utilisateurs particuliers. Il est donc nécessaire de mettre en place un système qui permet d'authentifier l'usager du LMS afin de connaître ses droits vis-à-vis du KPS. Une solution basique mais sécurisée a été mise en œuvre : les identifiants, sans les mots de passe associés, ainsi que les droits des usagers répertoriés dans le système de gestion des utilisateurs du KPS sont mentionnés dans un simple fichier texte fourni avec la couche de Virtualisation. Lorsqu'un utilisateur tente d'accéder à l'interface de la couche de Fédération, la couche d'Intégration consulte tout d'abord le compte correspondant dans le LMS, recherche cet usager dans le fichier texte afin d'obtenir ses droits relatifs au KPS, et enfin délivre à la couche de Fédération le rôle associé. Ce mécanisme d'authentification, qui ne nécessite qu'une identification unique, ne représente pourtant pas une solution durable. En effet, si un nouvel utilisateur est créé dans le système de gestion du KPS et que le fichier texte n'est pas manuellement mis à jour au sein du LMS, cet utilisateur n'aura accès qu'au service de recherche, même s'il est autorisé à télécharger des documents. Une solution plus consistante et robuste est suggérée dans la dernière partie de ce document. 4.3. Indexation d'une nouvelle ressourceNos expérimentations relatives à l'indexation de nouveaux objets pédagogiques reposent sur la collaboration entre différents LMS (INES et Moodle) détaillés dans la section 4.5 et le vivier de connaissance Ariadne (le KPS). L'interface du service d'indexation permet de sélectionner le nouveau document sur le disque local de l'utilisateur, et propose ensuite un formulaire correspondant au profil de métadonnées Ariadne conforme au standard IEEE-LOM afin d'être en mesure d'insérer le nouveau document au sein du KPS ; notons que si le document est inséré à la fois dans le LMS et dans le KPS, les métadonnées ne sont stockées que dans le KPS. Ainsi l'indexeur doit renseigner au minimum un ensemble de dix huit valeurs obligatoires pour l'indexation de la nouvelle ressource ; nous proposons donc une aide à ce processus en générant la quasi-totalité des métadonnées obligatoires à l'indexation d'un nouvel objet pédagogique au sein du KPS. 4.4. Extraction et génération automatiques de métadonnées LOML'extraction et la génération automatiques de métadonnées exposées dans cette section s'appliquent au profil de métadonnées Ariadne/LOM défini par les membres du Comité Directeur de la fondation. Cet ensemble de métadonnées mentionne plus de quarante métadonnées, dont dix huit doivent obligatoirement être renseignées lors de l'indexation d'un nouvel objet dans le vivier de connaissance. 4.4.1 Indexation d'une ressource SCORM
Figure 7 : Extraction automatique de métadonnées LOM à partir d'une ressource SCORM Lorsque les utilisateurs insèrent de nouvelles activités SCORM au sein du LMS, il est possible d'extraire l'ensemble des métadonnées qui décrivent la ressource SCORM selon le standard LOM de l'IEEE en analysant le fichier XML manifest contenu dans le package et qui renferme les métadonnées décrivant le package. Ainsi, le formulaire électronique est automatiquement et entièrement rempli (Figure 7), et les objets pédagogiques SCORM peuvent être immédiatement indexés dans le KPS en invoquant le service de traitement correspondant. Les métadonnées spécifiées pour indexer le package SCORM au sein du KPS coïncident avec celles définies dans le fichier manifest. Ainsi, l'extraction de métadonnées : inhibe les interprétations et erreurs humaines : alors que les indexeurs humains ne décrivent pas nécessairement les métadonnées comme le font les auteurs, elle assure la consistance des métadonnées en ne prenant en compte que celles générées par les auteurs. associe une description unique à un document unique : il n'est pas rare de trouver différentes descriptions pour un même document. Toutefois, un fichier manifest ne renferme pas nécessairement l'ensemble des métadonnées LOM qui représentent un élément optionnel. Dans ce cas, le package SCORM doit être traité comme un document arbitraire. 4.4.2 Indexation d’un document arbitraireA partir des diverses informations vitales pour le bon fonctionnement d'un LMS, il est possible de produire automatiquement certaines métadonnées obligatoires à l'indexation d'un document dans le Knowledge Pool System. Cette tâche consiste à extraire des mots clés issus de l'environnement d'apprentissage du LMS et à les associer aux métadonnées du profil Ariadne-LOM réparties en quatre catégories : Général, Sémantique, Pédagogique et Technique. Nous détaillons ici la génération des métadonnées obligatoires même si quelques descripteurs optionnels peuvent être produits. Métadonnées GénéralesSi l'indexeur est aussi l'auteur de la ressource, il est possible de collecter ses nom et prénom à partir de son profil dans le LMS. En effet, une base de données dédiée à la gestion des utilisateurs est souvent présente au sein des plates-formes d'apprentissage, comme c'est le cas pour les LMS déployés dans le cadre de nos expérimentations. De plus, des métadonnées optionnelles telles que l'email, le téléphone ou le pays peuvent souvent être retrouvées et appliquées au profil Ariadne-LOM. D'autre part, le champ Langue des métadonnées peut être déduit de la langue courante utilisée dans le LMS. Selon les politiques définies au sein de l'EIAH, les Droits d'usage prennent pour valeur "Libre" ou "Restreint". D'autres métadonnées générées automatiquement ne sont pas liées au contexte d'apprentissage. En supprimant l'extension du fichier, le Titre du document peut être déduit à partir du nom du fichier correspondant à la ressource à indexer, alors que la Date de publication prend pour valeur la date du jour. Métadonnées Sémantiques
Figure 8 : Extrait du fichier XML pour la génération automatique de métadonnées Sémantiques Cet ensemble de métadonnées définit quatre champs obligatoires : Type de Science, Discipline Principale, Discipline Secondaire, et Concepts Principaux. Le profil Ariadne-LOM fournit des listes prédéfinies de choix pour les trois premières métadonnées ci-dessus, offrant ainsi la possibilité d'associer les métadonnées au contexte d'apprentissage. En effet, la formation ou catégorie en cours peut facilement être extraite du contexte du LMS et être associée aux deux métadonnées Type de Science et Discipline Principale. Par exemple, la catégorie ''Informatique'' ou la formation ''Doctorat en Informatique'' doit être associée au type de science ''Sciences Exactes, Naturelles, et de l'Ingénieur'', mais aussi à la discipline principale ''Traitement de l'Informations / Informatique''. Finalement, la Discipline Secondaire peut être déduite à partir de la combinaison des noms de la catégorie et du cursus courants. Ces associations sont stockées dans un fichier XML (Figure 8) qui décrit tous les types de science, disciplines principales et disciplines secondaires définies dans le profil Ariadne-LOM. Enfin, les mots clés extraits des descriptions de la catégorie et du cursus courants sont associés à la métadonnée Concepts Principaux. Ainsi l'ensemble des métadonnées Sémantiques obligatoires sont automatiquement produites. Métadonnées PédagogiquesLe Groupe cible peut être déduit à partir du rôle de l'utilisateur au sein du LMS : lorsque le rôle représente un enseignant, nous pouvons supposer que la nouvelle ressource constitue une brique du cursus courant et qu'elle est destinée à des apprenants, alors que si le rôle de l'utilisateur décrit un apprenant, nous pouvons supposer que la nouvelle ressource désigne un devoir à rendre et qu'elle est adressée à des enseignants. Ce raisonnement ne peut être appliqué dans le cas d'un travail collaboratif, mais l'utilisateur a la possibilité de modifier les métadonnées générées automatiquement. Une librairie intégrée dans la couche de Virtualisation permet de connaître, à partir d'une extension particulière, le type mime, le type de document, le format de document, et le système d'exploitation associés à cette extension. Ainsi d'autres métadonnées obligatoires peuvent être déduites à partir du l'extension du fichier à insérer : un fichier texte ou un fichier PDF indique un document expositif, alors qu'un fichier EXE décrit un document actif ; l'une des valeurs "Actif" ou "Expositif" peut donc être automatiquement affectée au Type de document. de nombreux types mime sont largement répandus et peuvent être associés à un format de document. Par exemple, un fichier TXT représente un fichier ne contenant que du texte et la métadonnée Format de document prendra pour valeur "Texte narratif". La seule métadonnée pour laquelle nous ne pouvons produire une valeur pertinente est la Durée pédagogique. En effet, ce descripteur est lié au contenu du document lui-même ainsi qu'au niveau d'apprentissage des apprenants. Métadonnées TechniquesLa dernière section de la classification définit quatre métadonnées obligatoires qui peuvent toutes être produites à partir du fichier lui-même : le Nom principal du fichier correspond au nom du fichier représentant la ressource à indexer. le Type mime et le Système d'exploitation sont obtenus à partir de l'extension du fichier et de la librairie mentionnée dans la section précédente. l'Espace disque nécessaire correspond à la taille du document. Si l'indexeur est aussi l'auteur du document, notre EIAH permet de générer automatiquement dix sept des dix huit métadonnées du profil Ariadne/LOM nécessaires à l'insertion d'un objet pédagogique dans le KPS. Alors que la tâche d'indexation de documents peut être longue et parfois difficile à réaliser dans certains contextes, elle représente un processus automatique dans notre EIAH et encourage les indexeurs humains à créer de réels objets pédagogiques plus faciles à retrouver et à réutiliser. Les efforts déployés dans la création d'une interface de démonstration, c'est-à-dire huit jours de développement d'un unique programmeur, sont insignifiants comparés aux bénéfices apportés par un service de génération automatique. En effet, même si les métadonnées produites automatiquement ne sont pas aussi satisfaisantes que celles générées par les indexeurs humains, elles n'ont pas besoin d'être parfaites mais suffisamment justes pour permettre le partage et la réutilisation (Duval et Hodgins, 2004). 4.5. Déploiement de la couche d'Intégration4.5.1 INES et International E-Mi@geLa première expérimentation avec la plate-forme INteractive E-learning management System (INES) (Cochard et al., 2003), un système de gestion d'apprentissage ''open source" développé par l'Université de Picardie d'Amiens, a été motivée par les besoins exprimés par le projet International E-Mi@ge (IEM) (Cochard et Marquié, 2004). IEM, issu des appels à propositions ''Campus Numériques Français'' de la Direction de la Technologie des années 2000, 2001 et 2002, est un programme de mise à distance de la filière d'enseignement MIAGE (Méthodes Informatiques Appliquées à la Gestion des Entreprises). Le lien vers la couche de Fédération apparaît dans l'espace de travail dédié à la gestion des ressources de la plate-forme qui est illustré par la Figure 9.
Figure 9 : Déploiement de la couche d'Intégration au sein de la plate-forme INES Les trois variables nécessaires à la réalisation des services de Fédération ont facilement été acquises : les informations des utilisateurs sont stockées dans la table "personnels" de la base de données principale d'INES. le répertoire racine dans lequel sont stockés les documents pédagogiques est le même pour chaque instance d'INES, il se nomme "foadF". l'identifiant du répertoire de la formation en cours apparaît dans la barre d'adresse du navigateur sous le nom "VNForm". L'organisation architecturale de IEM, dédiée à une exploitation en commun par les membres du consortium IEM et des partenaires, est constituée de deux composants majeurs : un unique vivier de connaissance géré par l'Université Paul Sabatier (UPS - Toulouse 3) dispose des dernières versions des contenus pédagogiques, et une instance de la plate-forme INES pour chaque centre d'exploitation. Le vivier de connaissance est en fait celui de la Fondation Ariadne : un accord entre le consortium IEM et la Fondation ARIADNE a été conclu en 2004. Jusqu'à maintenant, les différents centres d'exploitation s'approvisionnent à partir de ce vivier en téléchargeant puis en installant manuellement les documents sur leur propre plate-forme INES. La couche de Virtualisation a été mise en place au coeur de l'EIAH de l'UPS et permet de rechercher, d'importer des documents existants au sein de la plate-forme INES et d'indexer de nouveaux modules dans le KPS automatiquement. Actuellement en phase de test, elle sera déployée dans les autres centres d'exploitation à la prochaine rentrée universitaire. 4.5.2 Moodle et la Structure Universitaire de Pédagogie de l'Université Paul SabatierDans la deuxième expérimentation nous nous sommes intéressés au système Moodle (MOODLE, 2002), une plate-forme d'enseignement ''open source'' largement utilisée à travers le monde.
Figure 10 : Déploiement de la couche d'Intégration au sein de la plate-forme Moodle A partir de l'intégration existante et spécifique à INES, l'approche a consisté à établir l'équivalence entre les variables spécifiques à INES et celles propres à Moodle. Dans un premier temps, nous avons identifié l'espace de travail réservé à la gestion des ressources afin d'y insérer la couche d'Intégration (Figure 10). Ensuite, nous avons utilisé la table "mdl_user" pour obtenir les informations de l'utilisateur connecté à Moodle. Le répertoire racine dans lequel sont stockés les documents est défini dans le fichier de configuration de la plate-forme, tandis que l'identifiant du répertoire de la formation en cours apparaît dans la barre d'adresse du navigateur sous le nom "wdir". L'adaptation à la plate-forme Moodle a nécessité un coût de développement minimal comparé aux bénéfices qu'apporte la solution proposée ; elle démontre aussi le caractère générique de notre couche de Virtualisation. La solution Moodle/Ariadne devrait représenter la base de l'EIAH de la Structure Universitaire de Pédagogie (SUP, 2003) qui a été mise en place au mois de Janvier 2005 afin de susciter, d'accompagner, et de valoriser les projets portés par des équipes d'enseignants et de favoriser de nouvelles situations d'apprentissage au sein de l'Université Paul Sabatier. Suite à une récente présentation de cet outil devant des acteurs impliqués dans le développement et le maintien de la plate-forme Moodle, l'intégration de ces travaux dans la prochaine version 1.6 du système est en cours de discussion. Cette contribution permettrait de sensibiliser un nombre très important d'utilisateurs à la nécessité de partager et de réutiliser les documents pédagogiques tout en leur facilitant l'accès à des ressources de natures variées. 5. Conclusions et futures OrientationsNous avons présenté un Environnement Informatique pour l'Apprentissage Humain au service de la virtualisation des ressources pédagogiques. La flexibilité du cadre de travail proposé, en partie due à l'adoption et à la facilité d'utilisation des protocoles et technologies retenues, offre une modularité des composants, spécifiquement lorsqu'il s'agit d'offrir une vue unique de ressources stockées dans des viviers distincts ou de fournir un accès facilité à celles-ci à travers les plates-formes d'apprentissage à distance. Cet EIAH favorise donc le partage et la réutilisation des objets pédagogiques et contribue ainsi à l'utilisation de masse de la FOAD. La fédération de différents viviers de connaissance nous a permis d'augmenter considérablement la masse pédagogique disponible à partir d'un outil unique, puisque le nombre de ressources visibles est d'environ seize mille. Un danger conséquent de cette fédération est l'obtention d'un nombre trop important de ressources. Nous devons donc optimiser les requêtes en collaboration avec des spécialistes de ce domaine afin d'affiner les capacités du service de recherche. Supporté par les services Web, nous avons ensuite illustré le caractère générique de la couche de Virtualisation qui offre une interaction entre des viviers de connaissance et des LMS tout en masquant la complexité des systèmes mis en jeu. Les expérimentations déployées avec des plates-formes d'apprentissage différentes au sein d'un projet international (IEM) et d'un projet local (SUP) ont montré que l'approche par couche d'abstraction peut être appliquée avec succès et réutilisée par d'autres environnements d'apprentissage. Dans le but d'enrichir l'EIAH présenté dans cet article, trois orientations majeures vont être mises en œuvre : la première consiste à déployer l'ensemble des services présentés sous forme de services Web. Une telle évolution permettrait une séparation plus claire du code du LMS et du code de la couche de Virtualisation, et faciliterait l'accès à ces services par d'autres plates-formes déployées dans un autre langage de programmation. la deuxième concerne le mécanisme d'authentification exposé dans la section 4.2. Ce système sera remplacé dans quelques semaines par un mécanisme global basé sur un annuaire LDAP (Lightweight Directory Access Protocol). D'une part, le système de gestion des utilisateurs du KPS offre depuis peu une telle fonctionnalité, et d'autre part certaines plates-formes d'enseignement comme Moodle proposent un service d'authentification basé sur cette technologie. Ainsi, à partir du nom de l'utilisateur connecté au LMS, une requête vers l'annuaire permettra de connaître les droits de l'usager vis-à-vis du KPS. enfin, la dernière étape concerne l'extraction et la génération automatiques de métadonnées. Nous souhaitons intégrer les travaux présentés dans la section 4.4 au sein d'un cadre de travail existant dédié à la génération automatique de métadonnées (Automatic Metadata Generation, AMG) (AMG, 2005). Des services Web d'indexation basés sur le contenu d'un document permettent d'obtenir des métadonnées comme la langue du document, son format ou son type. Notre EIAH bénéficiera de métadonnées produites par les deux outils, rendant alors possible la comparaison de métadonnées redondantes et améliorant ainsi la consistance et la fiabilité des métadonnées générées ; les retours d'expérience issus des projets IEM et SUP contribueront également à cet objectif. En considérant une collaboration totale entre plusieurs plates-formes d'apprentissage et de multiples viviers de connaissance, se posent les problèmes du suivi et de la gestion des objets pédagogiques pour maintenir leur consistance vis-à-vis des systèmes exploitant ces ressources. Des outils devraient permettre de savoir dans quels cursus un objet pédagogique particulier est déployé, au sein de quels systèmes et par quels utilisateurs. Des statistiques comme le nombre de consultation, de téléchargement ou d'intégration dans un cursus d'un objet particulier pourraient permettre une recherche plus pertinente et aider les formateurs dans le processus de création d'un scénario pédagogique. Enfin, nous souhaitons analyser les facteurs sociaux et culturels qui facilitent ou qui empêchent l'utilisation des EIAH comme méthode d'enseignement dans les institutions publiques et privées. Dans le cadre des Programmes d'Actions Intégrées (PAI) de l'association Egide (EGIDE, 2002), nous initions une collaboration avec un laboratoire localisé à l'Université Chinoise d'Hong-Kong et impliqué dans l'initiative LEARNet (LEARNET, 2003) afin de réaliser nos études sur des cultures et sociétés variées. BIBLIOGRAPHIEArapi P., Moumoutzis N., Christodoulakis S. (2003). Supporting Interoperability in an Existing e-Learning Platform Using SCORM, Actes de la conférence ICALT'03, Athènes, 388-390. Barron A. E., Rickelman C. (2001). Management systems, by Adelsberger H.H., Collis B., and Pawlowski J. M., Handbook of Information technologies for education and training. Broisin J., Vidal P., Baqué P., Duval E. (2005). Sharing & Re-using Learning Objects : Learning Management Systems and Learning Object Repositories, Actes de la conférence EDMEDIA 2005, Montreal, 4558-4565. Broisin J., Vidal P., Meire M., Duval E. (2005). Bridging the gap between learning management systems and learning object repositories: exploiting learning context information, ELETE 2005, Lisbonne, 478-483. Cochard G. M., Sidir M., Pires L., Baudoux S. (2003). INES, une plate-forme orientée vers la gestion des acteurs et des activités, Colloque Campus Numériques et Universités Numériques en région, Montpellier. Cochard G. M., Marquie D. (2004). An E-learning version of the French higher Educationn Curriculum ''Computer Methods for the Companies Management'', Actes de la conférence IFIP WCC 2004, Toulouse, VA, 557-572. Duval E., HodginsW. (2004). Making Metadata go away. Hiding everything but the benefits, Dublin Core Conference 2004, Shangai, http://purl.org/metadataresearch/dcconf2004/papers/Paper_15.pdf (consulté en Novembre 2005) Duval E., Forte E., Cardinaels K., Verhoeven B., Durm V., Hendrikx K., Forte M.W., Ebel N., Macowicz M., Warkentyne K., Haenni F. (2001). The ARIADNE Knowledge Pool System, Association for Computing Machinery 44(5), 73-78. Forte E., Wentland-Forte W., Duval E. (1996). Ariadne: a framework for technology-based open and distance education, Actes de la conférence Telematics for Future Education and Training, Oulu, 69-72. Friesen K., Mazloumi N. (2004). Integration of Learning Management Systems and Web Applications using Services Web, Advanced Technology for Learning 1(1), 16-24. Gimont J. Le monde informatique du 19 Décembre 2003. Guangzuo C. (2003). OntoEdu: A Case Study of Ontology based Semantic Grid for Education Service. Report at Annual Conference of CETA ,China. IEEE 1484.12.1-2002. (2002). Draft Standard for Learning Object Metadata, http://ltsc.ieee.org/wg12/files/LOM_1484_12_1_v1_Final_Draft.pdf (consulté en Novembre 2005) Jenkins C., Jackson M., Burden P., Wallis,J. (1999). Automatic RDF Metadata Generation for Resource Discovery, Computer Networks (31), 1305-1320. Massart D. (2005). Accessing Learning Contents Using a "Simple Query Interface" Adapter, Prolearn-iClass Thematic Workshop, http://www.cs.kuleuven.ac.be/~hmdb/ProlearnIClass/papers/Massart.pdf (consulté en Novembre 2005) Michau F., Poix S.S. (2003). Proposition de carte organisationnelle - Décrire le rôle d’un Environnement informatique au sein d’un dispositif pédagogique, Actes de la conférence EIAH 2003, Strasbourg, 331-342. Moore M. G. (2001). Standards and Learning Objects, American Journal of Distance Education 15(3), 1-4. Paquette G. (2000). Construction de portails de télé-apprentissage Explor@ - Une diversité de modèles pédagogiques, Science et Techniques Educatives 7(1), 207-226. Paulsen M. F. (2003). Experiences with Learning Management Systems in 113 European Institutions, Educational Technology & Society 6(4), 134-148. Advanced Distributed Learning. (2004). SCORM (Sharable Content Object Reference Model Information) Conformance Requirements Version 1.2, http://www.adlnet.org/screens/shares/dsp_displayfile.cfm?fileid=1059 (consulté en Novembre 2005) Simon B., Massart D., Van Assche F., Ternier S., Duval E. (2004). Simple Query Interface Specification, http://nm.wu-wien.ac.at/e-learning/inter/SQI_V1.0alpha_2004_12_30.pdf (consulté en Novembre 2005) Tchounikine P. (2002). Pour une ingénierie des Environnements Informatiques pour l'Apprentissage Humain, Revue I3 information - interaction - intelligence 2(1), 59-95. Vidal P., Broisin J. (2005). Vers la fédération des ressources pédagogiques : une architecture fédérée de systèmes de gestion de contenus d'apprentissage, Actes de la conférence EIAH05, Montpellier, Accepté (papier long). Vidal P., Broisin J., Duval E. (2004). Learning Objects : the ARIADNE Experience, Actes de la conférence IFIP WCC 2004, Toulouse, 551-556. Vidal P., Alibert A., Baqué P. (2003). Towards E-Learning Platforms Interoperability : an Opening Solution, Actes de la conférence ITHET’03, Marrakech, 193-199. SITES INTERNET
http://www.ariadne-eu.org (consulté en Novembre 2005) Automatic Metadata Generation 2005 : http://www.cs.kuleuven.ac.be/~hmdb/amg/ (consulté en Novembre 2005) Projet CANCORE 2000 : http://www.cancore.ca/fr (consulté en Novembre 2005) Dublin Core 1995 : http://www.dublincore.org (consulté en Novembre 2005) EGIDE Premier opérateur français de la mobilité internationale 2002 : http://www.egide.asso.fr (consulté en Novembre 2005) Katholieke Universiteit Leuven : http://kuleuven.ac.be (consulté en Novembre 2005) LEARNet Sharable Learning Resources in Hong Kong 2003 : http://learnet.hku.hk (consulté en Novembre 2005) Projet Learning Resource Catalog 2003 : http://learnet.hku.hk/objects.htm (consulté en Novembre 2005) Initiative MERLOT (Mutimedia Educational Resource for Learning and Online Teaching) 1997 : http://www.merlot.org (consulté en Novembre 2005) Plate-forme de gestion d'apprentissage Moodle 2002 : http://moodle.org (consulté en Novembre 2005) http://dietrich.ganx4.com/nusoap/index.php (consulté en Novembre 2005) Projet OWASIS 2001 : http://gi.insa-lyon.fr/insav/public/village/Apropos/page1.html (consulté en Novembre 2005) Projet Structure Universitaire de Pédagogie 2003 : http://sup.ups-tlse.fr (consulté en Novembre 2005)
| ||||
Référence de l'article :Julien Broisin, Philippe Vidal, Un Environnement Informatique pour l'Apprentissage Humain au service de la Virtualisation des Objets Pédagogiques, Revue STICEF, Volume 12, 2005, ISSN : 1764-7223, mis en ligne le 16/02/2006, http://sticef.org |