de l´Information et
de la Communication pour
l´Éducation et la Formation
version à télécharger (pdf)
Volume 18, 2011
Article de recherche
|
Contact : infos@sticef.org |
La modélisation du tutorat dans les systèmes tutoriels intelligents
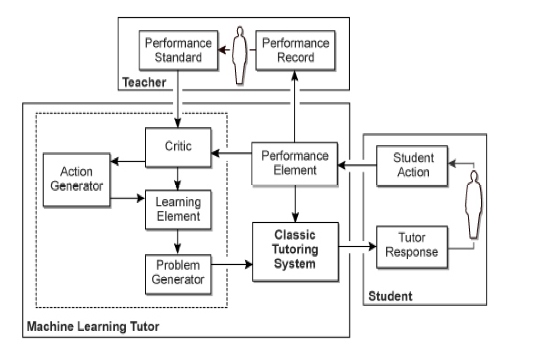
1. IntroductionDans le domaine de l’intelligence artificielle (IA) en éducation, la recherche sur les systèmes tutoriels intelligents (STI) représente un effort pour concevoir, développer, implémenter et évaluer des systèmes qui appliquent des principes et des techniques de l’IA pour résoudre des problèmes d’apprentissage humain. Cet article propose une synthèse et une réflexion sur les origines des STI, les efforts pour modéliser les différentes composantes, particulièrement le modèle de tutorat, et finalement les résultats obtenus et les questions ouvertes. 2. Le tutorat dans les STILe tutorat est une forme d’enseignement qui possède deux caractéristiques principales. Premièrement, le ratio tuteur/élève est de 1 à 1, 2 ou 3, et généralement de 1 à 1, de sorte que l’attention du tuteur est en général entièrement consacrée à un élève à la fois. Deuxièmement, le tuteur exerce un certain guidage et donc un contrôle, bien que celui-ci puisse être partagé avec l’élève, par exemple dans le cas de la découverte guidée. En termes d’adaptation, essentielle dans les systèmes intelligents, le tutorat joue un rôle inverse à celui de l’enseignant en classe. Ce dernier demande à chaque élève de s’adapter à un enseignement commun pour la classe, tandis que le tuteur cherche à adapter son intervention aux besoins particuliers d’un élève. 3. La place du tutorat dans les STI La communauté de chercheurs dans le domaine des STI s’est saisie de cette notion de tutorat et a élaboré différentes hypothèses pour lui faire une place, que ce soit dans la modélisation du domaine ou dans celle de l’étudiant. L’hypothèse de l’interaction, privilégiée aujourd’hui, considère que le cœur du tutorat se situe dans l’interaction, et voit le tuteur et l’élève travailler ensemble comme un duo (Graesser et al., 2001), (VanLehn, 2006). Le défi de l’adaptation pour le tutorat dans un STI consiste donc d’abord à concevoir des interactions de façon à soutenir une adaptation fine, et ensuite à concevoir le comportement de la composante tutorat de façon à ce qu’elle puisse raisonner à partir de données provenant de l’étudiant, aussi près que possible du temps réel. L’hypothèse de l’interaction continue d’évoluer, et Van Lehn a introduit la notion d’Interaction Plateau, estimant que l’interactivité ne devrait pas dépasser celle qui existe de façon naturelle entre les humains ; au delà de ce seuil, l’efficacité pédagogique serait réduite (VanLehn, 2008). Le défi de réussir au moins aussi bien que les tuteurs humains est constant dans la recherche sur les STI. Il s’agit de définir et de formaliser les fonctions et les variables, de découvrir ce qui pourrait ‘causer’ le succès du tutorat humain, et finalement d’évaluer l’éventuel succès de la représentation du tutorat dans un STI, ainsi que le succès obtenu dans l’interaction d’un élève avec ce STI. 3.1. Les fonctions du tutoratLes deux principales fonctions du tutorat sont celles de tout enseignement : susciter l’apprentissage et l’évaluer. Ces deux fonctions sont traitées soit séparément soit conjointement dans le domaine des STI. Ainsi, le système ASSISTment doit son nom à la volonté explicite d’intégrer les deux fonctions. Le principal dilemme qui préoccupe les chercheurs est le suivant : quand et comment intervenir auprès de l’étudiant pour le soutenir dans son apprentissage : To Tutor or Not to Tutor: That is the Question (Razzaq et Heffernan, 2009), and Does Help Help? (Beck et al., 2008). La fonction de soutien à l’apprentissage peut elle-même se subdiviser en deux sous-fonctions : le diagnostic cognitif, qui consiste à détecter les sources des erreurs, et la sélection de stratégies de tutorat ou de remédiation qui soient les mieux adaptées. Ces fonctions incluent depuis récemment l’adaptation aux états affectifs des étudiants, dans la mesure où ceux-ci font partie intégrante des conditions de l’apprentissage. Un défi récent pour les STI est d’équilibrer les dimensions cognitive et affective dans le raisonnement qui conduit à une décision de tutorat (Boyer et al., 2008) . 3.2. Les variables du tutoratUne équipe de recherche dans le domaine des STI est confrontée à une multitude de variables lorsqu’elle entreprend de concevoir un tel système. La première question à se poser est : qui est l’étudiant ? quelles sont ses caractéristiques, ses connaissances antérieures, son but, sa motivation, sa culture ? Connaître l’étudiant est la condition sine qua non de l’adaptation recherchée. La recherche sur les STI s’est longtemps concentrée sur un raisonnement capable d’induire les états cognitifs de l’étudiant ; elle explore aujourd’hui des méthodes de calcul à partir de données extraites des interactions avec l’étudiant. La deuxième question est celle du contenu : qu’est-ce qui est enseigné ? la matière, le curriculum, (maths, langues, biologie) avec les caractéristiques qui lui sont propres ; on distingue également le type d’apprentissage (concept, règle), les habiletés (résolution de problème), et les compétences (mise en œuvre des savoirs). La troisième question est celle du comment : quelles sont les stratégies appropriées pour enseigner tel contenu à tel étudiant se trouvant dans tel état cognitif et affectif ? Dans ce cas, le raisonnement s’exerce sur les caractéristiques des stratégies : dialogue socratique, ‘scaffolding/fading’, élicitation des connaissances, jeu/simulation, visualisation multiple, etc.. Les interrogations des chercheurs portent tant sur l’adaptabilité du système que sur l’efficacité des stratégies (VanLehn et al., 2007). Enfin, la dernière grande question à se poser est celle du contexte : dans quel contexte se déroule le tutorat ? Cette dimension peut être interprêtée de différentes façons : le contexte physique, par exemple la salle de classe, la maison, l’apprentissage mobile ; les contextes cognitif, affectif et culturel. Tandis que les trois premières dimensions ont fait l’objet de nombreuses investigations, il est notable que la dernière, soit le contexte, a été moins étudiée et reste une limite sérieuse dans le domaine des STI. 3.3. Le tutorat, un fondement pour les STILe domaine de l’intelligence artificielle en éducation, connu sous le sigle de sa société, AIED, était en pleine émergence (Wenger, 1987) lorsqu’en 1984 Bloom publia son célèbre article sur l’efficacité du tutorat (Bloom, 1984), peu après que Cohen et al. aient publié leur méta-analyse sur le tutorat (Cohen et al., 1982). Les chercheurs virent dans le tutorat un fondement solide sur lequel bâtir des systèmes adaptatifs et interactifs, qu’ils appelèrent systèmes tutoriels intelligents, soit des systèmes capables d’offrir des services individualisés puisque le ratio 1-1 n’est pas une option pour tous. Dans les systèmes éducatifs, le tutorat privé est une exception, et le tutorat en formation à distance en est une autre1. Ces repères sur la nature du tutorat étant acquis, se pose la question de la modélisation dans les STI. 4. La modélisation du tutorat dans les STISi le but d’un STI est d’être au moins aussi efficace qu’un bon tuteur humain, de quelles connaissances devrait-il être composé ? Un tuteur humain possède une bonne compréhension du curriculum, de la cognition et de l’apprentissage, et des stratégies d’enseignement. Il possède des connaissances factuelles constamment à jour sur les états cognitifs et affectifs de l’étudiant, sa personnalité, le contexte, et possède aussi la capacité de s’adapter à toutes les nuances de la situation. Afin de se concentrer sur les questions de la modélisation du tutorat dans les STI, il est nécessaire d’en faire une définition et une caractérisation plus précise, d’identifier les sources de connaissances sur le tutorat, et d’en considérer les implications pour le design des interactions avec l’étudiant, ainsi que pour l’apprentissage collaboratif et l’apprentissage basé sur le Web. 4.1. Les sources de connaissances du tutoratEn 2001, dans leur article intitulé Modeling human teaching tactics and strategies for tutoring systems, DuBoulay et Luckin (DuBoulay et Luckin, 2001) pointaient trois principales méthodologies pour développer l’expertise pédagogique dans les STI : l’observation d’enseignants, l’étude des théories de l’apprentissage, et l’observation d’étudiants en situation réelle d’interaction avec des systèmes en ligne. Ces trois méthodes sont toujours d’actualité. En ce qui concerne l’observation d’enseignants en classe, il importe de noter les différences entre la situation en classe et le tutorat. Premièrement, interagir avec 1, 2 ou 3 étudiants est bien différent d’enseigner à une classe. Deuxièmement, comme le soulignent DuBoulay et Luckin, la question se pose de savoir si les stratégies employées par les enseignants peuvent être aussi efficaces lorsqu’appliquées par une machine. Troisièmement, comme l’indique Grandbastien (Grandbastien, 1999), les stratégies observées l’ont souvent été alors que les ordinateurs n’étaient pas présents dans la classe ni dans la vie quotidienne. Il y a lieu de s’interroger si les décisions stratégiques de tutorat peuvent ou devraient être les mêmes lorsqu’utilisées par un humain ou par une machine, qu’il s’agisse d’enseignement en classe ou de tutorat humain en ligne. Le développement de la fonction de tuteur en ligne a en effet suscité des études qui enrichissent les observations déjà disponibles sur le tutorat, voir par exemple (Denis, 2003) et (Jaillet et al., 2011) Par ailleurs, plusieurs chercheurs dans le domaine des STI ont fondé leur travail directement sur des théories cognitives notamment la théorie ACT-R de Anderson, sur des théories de l’apprentissage collaboratif ou social, notamment celle de Vigotsky, des théories de l’enseignement comme le ‘Mastery Learning’ de Bloom et la théorie du design pédagogique de Gagné. Quant aux sources de connaissances pratiques, étant donné qu’elles sont mal définies et difficiles à systématiser, elles sont également difficiles à modéliser, qu’elles soient les observations des enseignants ou des tuteurs privés. En outre, l’idée d’arrimer les connaissances pratiques et théoriques dans un modèle de connaissances unifié reste encore un problème ouvert. La modélisation des connaissances déclaratives sous la forme d’une ontologie semble une piste particulièrement prometteuse, et est illustrée par le projet OMNIBUS-SMARTIES, qui propose une ontologie du domaine de l’éducation (Hayashi et al., 2009). Une autre source de connaissances sur l’étudiant est celle des données capturées lors des interactions étudiant-système. Les défis de l’utilisation des techniques de ‘data mining’ et de ‘machine learning’ à cette fin sont documentées dans l’ouvrage de Woolf (Woolf, 2009) et les réalisations sont suffisamment prometteuses pour avoir donné naissance à une nouvelle communauté de recherche avec sa conférence annuelle, ‘Educational Data Mining’ (EDM), les chercheurs appartenant également à la communauté STI. 4.2. La caractérisation du tutorat et sa définitionLa tradition dans la recherche sur les STI est de définir le tutorat par sa structure et ses composantes : modèle du domaine, modèle de l’étudiant, modèle du tutorat, et interface de communication. Par contraste, VanLehn (VanLehn, 2006) propose de caractériser les STI par leur comportement. Selon cet auteur, les STI démontreraient l’existence de deux boucles, l’une externe, au niveau de la tâche (task), et l’autre interne, au niveau de l’étape (step). Seraient des STI seulement les systèmes qui possèdent la boucle interne, qui témoigne de la capacité d’adaptation du système. Cette position a été appréciée mais aussi critiquée par DuBoulay (DuBoulay, 2006) et Lester (Lester, 2006). DuBoulay accepte cette caractérisation pour certains STI, la plupart dans les domaines techniques, mais selon lui elle ne vaudrait pas pour d’autres, pour lesquels les notions de tâche et d’étape ne s’appliquent pas. Lester quant à lui commence par souligner la contribution majeure de VanLehn avec ce qu’il appelle le ‘KVL Framework’, qui distille les efforts des chercheurs pour en extraire une procédure générique composée d’itérations de deux boucles imbriquées l’une dans l’autre. Cependant, à l’instar de DuBoulay, il estime que ce cadre ne s’appliquerait pas aux domaines mal-définis. Une autre perspective sur les STI est celle des hypothèses qui les sous-tendent. Outre celles du modèle du domaine et du modèle étudiant, l’hypothèse de l’interaction (Interaction Hypothesis) prévaut depuis quelques années, et tend à se substituer aux hypothèses centrées sur l’apprenant, le domaine, ou l’enseignant. En 2001, Graesser, VanLehn et d’autres chercheurs (Graesser et al., 2001), dans le cadre d’une large réflexion sur la complexité des STI, proposaient cette hypothèse comme étant centrale pour atteindre le but de l’adaptation du système. Ils ouvraient la porte à des recherches approfondies sur l’analyse du dialogue en langue naturelle, entre tuteurs humains (novices et experts) et apprenants, et la conception de systèmes capables de conduire ces dialogues. Ayant examiné cette hypothèse à l’œuvre dans plusieurs STI, ils décrivent comment ces interactions sont structurées du côté des systèmes, et comment celles de l’étudiant peuvent être prédites, interprétées et évaluées (VanLehn et al., 2007). La stratégie des systèmes AutoTutor est basée sur des structures de dialogue en langue naturelle, avec une reconnaissance de ce qu’exprime l’étudiant. Le dialogue est guidé par un agent qui peut encourager, approuver, donner du feedback. La stratégie dans le système ANDES, pour la résolution de problèmes en physique, repose sur le ‘model-tracing’. Le dialogue s’adapte selon les actions de l’étudiant qui sont capturées. Les résultats de ces études indiquent que le dialogue tutoriel est, dans certains cas, aussi efficace que la lecture, mais, dans d’autres cas, plus efficace et de façon significative (VanLehn et al., 2007) ; dans tous les cas, c’est le degré d’adaptation qui joue un rôle-clé. Un des fondateurs du domaine, John Self, proposait la caractérisation suivante d’un STI : ‘ ITSs are computer-based learning systems which attempt to adapt to the needs of learners and are therefore the only such systems which attempt to 'care' about learners in that sense. Also, ITS research is the only part of the general IT and education field which has as its scientific goal to make computationally precise and explicit forms of educational, psychological and social knowledge which are often left implicit’ (Self, 1999). Cette caractérisation met en lumière la nature adaptative d’un STI comme le cœur d’un tel système. Si la notion de ‘caring’ peut s’interpréter comme étant une adaptation pleine d’attention et de sensibilité aux états cognitifs et émotifs d’un étudiant, alors elle est équivalente à un bon tutorat. Ces perspectives permettent de proposer la définition suivante du tutorat dans les STI : susciter et évaluer l’apprentissage par une interaction adaptative entre l’étudiant et le système. Il apparaît donc crucial d’accorder une attention particulière à la conception des interactions. 4.3. La conception des interactionsLa clé du succès d’un STI pourrait bien dépendre de la conception des interactions. Les concepteurs font face à la question : interagir par le dialogue en langue naturelle? Ce dialogue étant le plus naturel, et efficace en termes d’adaptation, il a fait l’objet de nombreux travaux, malgré les difficultés de cette technologie (Graesser et al., 2001). Une alternative est celle d’interactions par des manipulations du système qui réagit comme c’est le cas dans les simulations et les environnements de découverte (Woolf, 2009). Dans ces environnements, le tutorat est intégré dans : 1) la simulation elle-même, qui représente un monde ou un phénomène, avec ses lois ou ses équations, 2) les actions offertes à l’étudiant pour manipuler les variables, 3) l’interprétation faite par le système, 4) le changement d’état du système et 5) le feedback à l’étudiant. Ces interactions sont propres à l’apprentissage individuel d’un étudiant. Toutefois, les STI sont parfois conçus pour d’autres contextes, tel l’apprentissage collaboratif et l’apprentissage par navigation sur le Web. En 1988, Chan présentait ‘the computer as a learning companion’ (Chan et Baskin, 1990) ; il pavait le chemin pour l’apprentissage collaboratif (Computer-assisted collaborative learning, CSCL), une nouvelle piste de recherche qui faisait l’objet d’un numéro spécial du Journal IJAIED en 1998. Les chercheurs se sont regroupés en une communauté qui possède son journal et organise un colloque biannuel, mais ils continuent pour la plupart à contribuer au domaine des STI. Dans les environnements CSCL, les interactions sont rarement vues comme du tutorat. Toutefois, les efforts par exemple pour construire des scripts adaptatifs et pour utiliser les données provenant de l’étudiant pour réaliser cette adaptation sont comparables aux efforts d’adaptation dans les STI. Le développement de l’apprentissage par navigation sur le Web a également donné lieu à une nouvelle piste de recherche et à un numéro spécial du Journal IJAIED intitulé ‘Adaptive and Intelligent Web-Based Systems’ (Brusilovsky et Peylo, 2003). Ces systèmes tentent de s’adapter à l’aide d’un modèle des buts, des préférences et aussi des données provenant de l’étudiant. Plutôt que de simplement viser une personnalisation de l’environnement, ils incorporent des actions de tutorat par exemple en guidant l’étudiant ou en diagnostiquant des conceptions erronées. Comme EDM et CSCL, ‘Adaptive Hypermedia’ s’est développé comme un champ de recherche autonome, et organise des conférences biannuelles. 5. Le développement d’un modèle du tutorat dans les STIDans cette section, le terme ‘modélisation du tutorat’ désigne toute forme par laquelle les chercheurs tentent de conceptualiser et opérationnaliser les fonctions et les variables du tutorat. Cette section en examine les différentes perspectives et en propose une nouvelle : ouvrir le modèle de tutorat à l’usager. 5.1. Un modèle de tutorat dans une architecture STIUne façon d’aborder la question de la modélisation du tutorat est de situer le modèle dans l’architecture du système : le tutorat trouve-t-il sa place dans une composante distincte ou bien est-il intégré dans une autre, que ce soit le domaine ou le modèle étudiant? Ou bien les fonctions de tutorat sont-elles réparties entre les composantes ? Le modèle tient-il compte des données fournies par l’étudiant dans ses interactions avec le système ? fait-il la place à un enseignant avec sa propre interface ? L’illustration proposée par Woolf (Woolf, 2009) pour des architectures qui combinent les composantes classiques avec une connaissance émergente, tout en ayant deux humains dans la boucle, met en lumière la complexité du design architectural des STI (Figure 1).
Figure 1 : Composantes de ‘machine learning techniques’ intégrées dans un STI (Woolf, 2009, permission de reproduire) Cette problématique de l’architecture est étroitement reliée aux paradigmes choisis par le concepteur, parfois à ses croyances : quelle architecture cognitive est utilisée? Quelles sont les sources privilégiées de connaissance pour le tutorat? Le tutorat devrait-il avoir une existence indépendante du domaine et de l’étudiant? Ces choix fondamentaux orientent le design de l’architecture, des fonctions, et le poids accordé aux variables. Le tutorat est modélisé d’abord en fonction d’un paradigme tel le behaviorisme ou le contructivisme, qui influence le choix des fonctions telles que quand et comment intervenir, et finalement des interactions telles que le dialogue. Les décisions de design pédagogique sont modélisées selon une ou plusieurs théories, cognitives ou pédagogiques. La modélisation du tutorat peut donc être définie comme un ensemble de décisions visant à susciter et évaluer l’apprentissage. Selon les cas, l’emphase sera mise sur le cognitif, le métacognitif, ou la collaboration, ou encore sur un aspect tel le diagnostic cognitif. Plusieurs équipes de recherche incorporent le tutorat dans le modèle du domaine ou dans celui de l’étudiant. Le débat sur la place du tutorat dans le système a nourri la réflexion et inspiré divers développements. Cependant, la disparité des modèles a limité les possibilités du partage et de la réutilisation (share and reuse), deux processus essentiels pour le développement de STI à grande échelle. Le modèle de tutorat se cristallise fréquemment autour du diagnostic cognitif, c’est-à-dire le mécanisme qui permet de détecter les erreurs, faire des hypothèses sur la cause de ces erreurs, les valider et offrir des moyens soit de les corriger, soit d’exploiter les erreurs à des fins de découverte. Ainsi, dans le cas du système PROLOG-TUTOR (Tchetagni et al., 2007), avec une situation d’apprentissage du langage PROLOG, le diagnostic s’opère à partir d’une base de connaissances, de règles causales, et de données provenant de l’étudiant encadrées dans un dialogue socratique (Figure 2). La boucle d’adaptation réalisée par PROLOG-TUTOR est un exemple de la complexité du diagnostic, malgré le fait que le domaine soit bien défini. Une autre technique de modélisation proposée pour le diagnostic est celle fondée sur la théorie de la décision, notamment pour la génération automatique d’une rétroaction épistémique Cette approche a été appliquée avec succès à l’apprentissage du logiciel de requêtes SQL (Mayo et Mitrovic 2001), et à celui de gestes chirurgicaux (Mufti-Alchawafa et Luengo, 2008). Un modèle de tutorat très différent est celui de la génération automatique de cours (Ullrich, 2007). Cette approche, basée sur la technique Hierarchical Task Network Planning, modélise les fonctions de conception de cours en permettant au tuteur ou à l’apprenant d’adapter les séquences d’activités en fonction des besoins de l’apprenant. Le système génère le scénario choisi (discover, rehearse, etc.), auquel il associe des ressources d’apprentissage pertinentes qu’il a repérées. Cette approche a été illustrée principalement en mathématiques dans le projet européen LeActiveMath, en mettant en œuvre l’approche par compétences prônée par le modèle européen PISA. Toutefois, malgré les efforts d’abstraction des connaissances dans des modèles et des ontologies, (Ullrich, 2007) , p. 218, fait remarquer qu’il reste beaucoup à faire pour généraliser l’approche à d’autres domaines que les mathématiques, notamment en rendant le modèle de compétences indépendant de celui du domaine.
Figure 2. Learner Modeling in Prolog-Tutor Using a Tutoring Dialogue (Tchetagni et al., IJAIED, 2007, permission de reproduire) 5.2. Systèmes-auteurs et développement de STILes systèmes-auteurs sont des environnements logiciels spécialisés dans le développement de STI. Le développement (authoring) du tutorat dans les STI - que ce soit une composante, des fonctions intégrées dans une autre composante, ou des services - reflète les choix fondamentaux déjà faits pour l’ensemble du STI en termes de paradigmes de la cognition. Il est bien différent s’il s’agit d’un environnement de découverte, d’un système basé sur le dialogue socratique, ou visant spécifiquement le diagnostic cognitif. Ceci explique que les systèmes-auteurs soient eux aussi axés sur un paradigme ou un autre, et que le partage et la réutilisation soient limités à des systèmes de la même famille (par analogie, ils partagent le même code génétique). En 1999, Murray proposait une classification des systèmes-auteurs existants, et constatant leur hétérogénéité et le besoin de partage et réutilisation, il suggérait que les ontologies offraient une solution à ce problème (Murray, 1999). Il proposait le système-auteur EON, qui possédait les caractéristiques suivantes : 1) une relation 1/1 entre les composantes et les outils-auteurs ; 2) indépendant des théories ou paradigmes, donc capables d’accommoder toutes les visions de l’apprentissage et du tutorat, 3) des ontologies comme fondement commun pour les composantes du système. En 2003, il publie l’ouvrage intitulé ‘Authoring Tools for Advanced Technology Learning Environments’ qui contient une présentation détaillée de plusieurs systèmes-auteurs, ainsi que de la problématique de partage et réutilisation (Murray et al., 2003). En 2000, Mizoguchi et Bourdeau décrivaient comment l’ingénierie ontologique était un instrument qui permettrait aux systèmes-auteurs de partager et réutiliser les connaissances explicitées et représentées comme des connaissances déclaratives (Mizoguchi et Bourdeau, 2000). Cette approche respecte la diversité des STI et de leurs paradigmes, et offre la possibilité de partager une collection de stratégies explicitement reliées à leurs sources théoriques ou empiriques. Le projet OMNIBUS-SMARTIES (Hayashi et al., 2009) en est l’illustration, puisque l’ontologie relie explicitement les stratégies pédagogiques aux différentes théories cognitives et pédagogiques.
Table 1. Les trois fonctions principales de CD-SPECIES (inspiré et traduit librement de Tchetagni et al., 2006, avec la permission des auteurs). Outre les systèmes-auteurs qui visent le développement de l’ensemble du système, certains outils se spécialisent dans une composante, comme c’est le cas pour le diagnostic cognitif. Pour exemple, CD-SPECIES se veut un outil-auteur permettant de produire les spécifications nécessaires pour le diagnostic cognitif appliqué à une situation éducative (Tchetagni et al., 2006). À partir de trois fonctions principales, soit 1) gérer la base de connaissances, 2) assister le concepteur pédagogique, 3) informer le programmeur, CD-SPECIES offre plusieurs menus permettant aux deux classes d’usagers de concevoir puis de programmer la composante de diagnostic (Table 1). Par ailleurs, des équipes de recherche se dotent de certains outils-auteurs spécifiques à leur paradigme. Elles visent à la fois à augmenter l’accessibilité et à réduire les coûts de développement, en construisant des outils-auteurs simplifiés, de plus haut niveau, et qui n’exigent pas de connaissance en IA, tel l’ASSISTment Builder (Razzaq et al., 2009). 6. Vers un modèle ouvert de tutoratBeaucoup de STI ont été conçus dans la perspective d’une utilisation en autonomie et en conséquence n’étaient pas ouverts au tuteur humain. Or une des raisons souvent avancée pour expliquer la faible utilisation des STI par exemple dans des classes est que les enseignants souhaitent pouvoir adapter un produit à leurs besoins et leurs habitudes de travail (Grandbastien, 1999). De plus, montrer aux enseignants les stratégies disponibles au sein du STI ne peut qu’enrichir leur propre pratique et susciter de leur part des suggestions d’amélioration de la version utilisée. Ouvrir le modèle de tutorat aux enseignants peut se faire avant les sessions d’apprentissage, par exemple pour faire un paramétrage du déroulement de la session, entrer de nouveaux exercices ou tests. Cela peut se faire aussi après la session pour recueillir et analyser les traces laissées par les apprenants. Des tentatives pour laisser des enseignants paramétrer des STI ont été faites dans plusieurs systèmes. Par exemple, les auteurs de REDEEM expliquent que ce système auteur pour créer des STI a été utilisé par des professeurs qui n’avaient aucune expérience préalable de la construction de STI (Ainsworth et al., 1999). Il s’agit cependant d’apprendre à utiliser un langage auteur spécifique pour écrire les règles pédagogiques. Les initiatives actuelles tendent à proposer des environnements flexibles pour répondre aux différents niveaux de besoins exprimés par les enseignants. On peut citer comme exemples le système PEPITE (Delozanne et al., 2008) qui permet de tester les compétences en algèbre élémentaire d’élèves de lycée et l’ASSISTment Builder (Razzaq et al., 2009). Dans PEPITE, l’enseignant dispose d’un éventail de possibilités allant de la fourniture d’un ensemble complet d’exercices pour les tests à l’utilisation du système clés en main en passant par la sélection d’exercices préenregistrés et l’adaptation des énoncés au travers de simples formulaires à compléter. En plus des réponses brutes des élèves aux tests, l’enseignant dispose aussi d’une vue synthétique des compétences de chaque élève et des groupes d’élèves ayant le même profil de compétences. Une fois adapté aux besoins des utilisateurs, le système peut aussi être utilisé individuellement par chaque élève. Il s’agit donc avec ces nouvelles générations de systèmes d’offrir davantage d’initiative et d’assistance aux enseignants tout en conservant l’utilisation individuelle. On peut aussi faire une analogie avec l’ouverture du modèle de l’apprenant et se demander pour quels apprenants et dans quelles conditions il serait bénéfique d’expliciter à un apprenant les stratégies tutorielles modélisées dans un STI. 6.1. L’évaluation du modèle de tutorat dans les STIL’évaluation du modèle de tutorat dans les STI est généralement indissociable de l’évaluation de l’ensemble du système. Toutefois, le but de l’évaluation dans ce cas peut être de tester la pertinence d’une ou de stratégies en lien avec une situation donnée, de tester l’efficacité de certains outils, par exemple le diagnostic d’erreurs, ou encore d’évaluer la capacité d’adaptation. Dans un ouvrage récent, Woolf propose une synthèse approfondie des méthodes d’évaluation pertinentes et des conditions de leur utilisation (Woolf, 2009). Plusieurs appliquent des approches comparatives, jusqu’à comparer les méthodes d’évaluation elles-mêmes (Zhang et al., 2008).. Les études in situ sont souvent hors de portée pour les petites équipes, mais lorsqu’elles sont possibles, elles fournissent des données précieuses pour justifier la présence des STI dans les écoles. Les équipes telles celles des Cognitive Tutors à Pittsburgh ou de AutoTutor à Memphis, se sont constitué des corpus de données à partir de « log files » ou d’autres traces en même temps que des outils d’analyse spécifiques. Le Pittsburgh Science of Learning Center s’est doté d’un laboratoire d’entreposage de données appelé Data shop, et d’une série d’outils d’analyse, tels le Error Report et le Learning Curve Generator. Il en résulte que le potentiel d’analyse a été amélioré, ainsi que l’étude des représentations dans les STI. Le concept de ’step’ (la plus petite entrée possible qu’un étudiant peut faire) a été réexaminé pour devenir un concept-clé pour les Cognitive Tutors et pour leur évolution. Malgré ces progrès, de nombreuses questions restent ouvertes et sont présentées dans la section suivante. 7. Questions ouvertesAlors que certains systèmes tutoriels sont utilisés dans des écoles et des universités, une première question mérite attention : celle du passage à l’échelle. L’atelier tenu à la conférence AIED 2009 a identifié plusieurs questions à travailler dont la prise en compte du curriculum sur des périodes plus longues (par exemple un semestre alors que les premiers tuteurs couvraient un sujet étroit et une ou quelques séances) et la mise à disposition de suites de produits interopérables sur les plateformes de formation en ligne et ouverts à plusieurs catégories d’utilisateurs, notamment les enseignants et les administrateurs. Nous présentons ensuite les questions liées aux avancées technologiques, les dimensions cognitives, affectives et contextuelles et nous soulevons des questions relatives au développement des jeux sérieux. 7.1. Avancées technologiquesLe dialogue étant un élément essentiel du tutorat, les progrès faits en traitement des langues naturelles vont continuer à bénéficier aux STI. Mais d’autres modes de communication viennent le compléter, notamment l’utilisation de schémas et croquis qui peuvent être le mode naturel de communication dans certains domaines. La modélisation et l’interprétation des schémas est désormais accessible, par exemple dans la plate-forme CogSketch (CogSketch, 2011). Les interfaces de complète immersion, les systèmes haptiques avec retour de force permettent la création d’environnements de formation professionnelle dans des domaines où l’utilisation d’environnements informatisés semblait impensable. Certains de ces nouveaux environnements de formation qui font largement appel à la réalité virtuelle incluent un modèle de tutorat, par exemple VR for Risk Management (Amokrane et Lourdeaux, 2009), (Amokrane et Lourdeaux, 2010). En 2000, Johnson, Rickel et Lester étaient les premiers à utiliser des personnages de synthèse sous forme d’agents pédagogiques animés (Johnson et al., 2000). Les progrès récents permettent de proposer des personnages aux expressions faciales et gestuelles sophistiquées et réalistes. En combinant réalité virtuelle et personnages virtuels qui agissent dans l’environnement de l’apprenant, Johnson a développé la série des Alelo’s Tactical Language and Cultural Training Systems (TLCTS). Certains de ces systèmes comme Tactical Iraqi ™ et Tactical French ™ sont utilisés par de nombreux apprenants. Les auteurs proposent une synthèse partielle des principes issus de leurs observations à propos du développement et de l’usage de systèmes de guidage en environnement immersif virtuel dans (Lane et Johnson, 2008), (Johnson et Valente, 2009). La technologie utilisée dans ces systèmes rejoint alors celle des jeux vidéo pour donner naissance au courant des jeux sérieux. 7.2. Dimensions affective, cognitive et contextuelleDe nombreuses études ont montré l’importance de la dimension affective dans les processus d’apprentissage. Cette dimension n’était pas du tout prise en compte dans les premiers modèles de décision tutorielle. Or les techniques développées pour suivre l’expression des visages, le mouvement des yeux, et d’autres données physiologiques permettent d’apporter des réponses pédagogiques qui tiennent compte de l’état affectif de l’étudiant. Arroyo et al. ont utilisé des capteurs pour enregistrer des données physiologiques et les ont comparées aux déclarations faites par les étudiants au sujet de leur état émotionnel (Arroyo et al., 2009). De plus l’utilisation des systèmes tutoriels en ligne permet d’enregistrer des données d’interaction entre l’apprenant et le système. Lorsqu’on a beaucoup de données de ce type, des techniques de data mining permettent de faire émerger des régularités qui sont autant de nouvelles informations à exploiter. L’objectif est d’arriver à une compréhension en profondeur des intérêts, intentions et émotions de l’étudiant en observant ses interactions, et par la suite d’améliorer l’efficacité du tutorat. On peut donc s’attendre à une nouvelle génération de systèmes prenant en compte cette dimension affective dans le fonctionnement humain. Cependant, Conati et Mitrovic rappellent que nous manquons encore de théories bien établies sur lesquelles fonder l’usage de l’affectif dans les interactions pédagogiques et de résultats prouvant l’efficacité de la prise en compte de l’aspect affectif pour améliorer l’apprentissage (Conati et Mitrovic, 2009). La dimension cognition située est de plus en plus présente dans les environnements virtuels d’apprentissage qui proposent aux apprenants des activités dans des contextes authentiques sur les plans physique, social et culturel (Lane et Johnson, 2008). Prendre en compte le contexte, c’est aussi mettre en œuvre la complémentarité entre tuteur artificiel et tuteur humain et l’implémenter dans les nouveaux environnements. En effet, les bonnes décisions tutorielles peuvent conduire à une très grande variété d’activités pour l’apprenant. La gestion de cette diversité peut être partagée entre tuteur humain et tuteur artificiel de façon à optimiser le service offert. Cela suppose l’ouverture des systèmes aux enseignants, l’association de ces mêmes enseignants à la conception des systèmes et la fourniture d’une vue générale des activités de chaque apprenant (et des activités du groupe s’il s’agit d’une classe) pour les enseignants, par exemple comme nous l’avons mentionné précédemment pour les systèmes PEPITE et ASSISTment. 7.3. Les jeux sérieuxLes jeux vidéos connaissent un succès grandissant auprès des jeunes et des adultes qui se montrent actifs et motivés pendant de longues périodes dans les univers qui leur sont proposés. L’utilisation de ces jeux à des fins de formation a donné naissance à une famille d’applications nommée jeux sérieux. Un jeu sérieux peut être défini comme une compétition intellectuelle jouée sur ordinateur pour atteindre un but en respectant un ensemble de règles et qui utilise l’aspect ludique pour développer des connaissances et des compétences dans des domaines variés. (Blanchard et al., 2012) soulignent que dans un jeu sérieux les objectifs d’apprentissage et de jeu ont même priorité et sont très fortement interconnectés et distribués au sein des objets et personnages des mondes virtuels. Ils rappellent des caractéristiques qui, selon (Gee, 2008), sont présentes dans un jeu qui suscite un apprentissage en profondeur : Interactivité ; adaptation, identités fortes, problèmes ordonnés, frustration motivante. Le lecteur intéressé pourra également consulter la synthèse publiée par (Moreno-Ger et al., 2009). Comment cette introduction des ressorts du jeu dans un environnement de formation peut-elle s’appliquer aux STI? Nous avons déjà mentionné le travail pionnier de Johnson et al. qui a abouti à des produits commercialisés et utilisés à grande échelle, (Johnson et Valente, 2009) mettent en scène des agents animés dans un environnement virtuel pour la formation à la langue et à la culture d’un pays. Lors de l’atelier organisé durant la conférence AIED 2009 et intitulé Intelligent Tutoring in Serious Games, (McNamara et al., 2009) ont proposé d’incorporer des éléments de jeu au sein des STI afin de fusionner le meilleur des deux mondes et d’obtenir des environnements offrant des niveaux optimaux de motivation et d’engagement permettant les apprentissages visés. Pour atteindre un tel objectif, des recherches fines sont encore nécessaires de façon générale sur l’intérêt des jeux dans les apprentissages et de façon plus ciblée sur l’interconnexion entre STI et jeux sérieux. De façon générale, par exemple (Squire, 2007) identifiait les sujets de recherche suivants : développer des théories de base sur l’apprentissage par le jeu, analyser des jeux pour comprendre leur influence positive sur les apprentissages, comprendre le rôle des interactions humaines au sein des jeux, développer des modèles pédagogiques fondés sur les jeux, analyser l’influence des jeux sur l’évolution des pratiques éducatives et l’adoption de pratiques fondées sur les jeux. Du point de vue spécifique aux STI, plusieurs directions sont déjà ou pourraient être explorées. Une première approche consiste à alterner pour l’apprenant des séquences de jeu et des séquences utilisant un STI. Il serait alors intéressant de déterminer quelles données issues de la phase de jeu pourraient nourrir le modèle d’apprenant du STI. Une autre approche consiste à intégrer des phases de jeu au sein d’un STI. Dans une telle configuration, le modèle de l’apprenant peut être constamment nourri par les actions du joueur et peut être utilisé pour personnaliser les rétroactions au sein même de la phase de jeu. Dans l’approche complètement intégrée proposée par McNamara et al., il n’y a plus de distinction entre phase de jeu et phase tutorielle, la production objet de l’apprentissage, par exemple une stratégie de vente ou la conduite d’un dialogue et la réalisation d’actions dans un environnement donné, fait partie du jeu ; le diagnostic s’affine au fur et à mesure des interactions et les rétroactions sont calculées et dynamiquement adaptées au joueur en fonction des objectifs de jeu et des objectifs d’apprentissage. Pour concevoir des systèmes fondés sur cette approche, il faudrait mieux étudier comment ne pas ‘casser’ la motivation pour le jeu par des conseils et remarques de nature pédagogique, ce qui ramène aux travaux de (VanLehn et al., 2007) sur l’hypothèse de l’interaction. Ensuite, du point de vue de la construction de tels systèmes, il faudra proposer des environnements auteur permettant de modéliser à la fois les stratégies de jeu et les stratégies tutorielles. D’autres questions n’ont pas encore été abordées et rejoignent des perspectives déjà évoquées dans cet article sur les systèmes collaboratifs ou la prise en compte des émotions : Quel est l’intérêt des jeux à plusieurs joueurs, quand faut-il les utiliser et comment gérer et utiliser l’interaction entre joueurs? Comment gérer et utiliser l’engagement du joueur pour que le système s’adapte dans ses interactions avec l’apprenant? Si les percées technologiques, ainsi que l’étude des dimensions affective, cognitive et contextuelle, et du potentiel des jeux pour l’apprentissage constituent des pistes de recherche sur la fonction tutorielle, on constate également des environnements qui proposent des séquences collaboratives permettant d’établir des liens entre systèmes tutoriels et systèmes sociaux du Web (Greenhow et al., 2009). Enfin, des travaux ont débuté pour rapprocher éducation et neurosciences (Varma et al., 2008) et observer des phénomènes liés aux apprentissages dans le cerveau humain. 8. ConclusionEn 2011, la recherche sur les STI témoigne d’un progrès en ce qui concerne la conception des fonctions de tutorat, tout en laissant ouverte la question du partage et de la réutilisation. L’intégration des données fournies par les outils de Machine Learning est prometteuse dans le sens d’une adaptation plus fine. Des efforts sont faits pour améliorer le coût de développement grâce à des outils-auteurs. La prise en compte de la dimension affective ouvre de nouveaux horizons et pourrait dans l’avenir s’enrichir en se combinant aux dimensions cognitive, métacognitive, et sociale. En conclusion, le but est de parvenir à une intelligence du tutorat qui suscite et évalue l'apprentissage, qui offre un soutien complet et en profondeur, et qui puisse offrir un service au moins aussi bon que celui d'un excellent tuteur humain. BIBLIOGRAPHIEAINSWORTH S., GRIMSHAW S., UNDERWOOD J. (1999). Teachers implementing pedagogy through REDEEM. Computers and Education, Vol. 33 n°2-3, p. 171-187. AMOKRANE K., LOURDEAUX, D. (2009). Virtual Reality Contribution to training and risk prevention. Proc. ICAI 2009, Las Vegas, USA, CSREA Press, p. 466-472. AMOKRANE K., LOURDEAUX D. (2010). Pedagogical system in virtual environments for high-risk sites. Proc. ICAART 2009, Valencia, Spain, INSTICC Press, p. 371-376. ARROYO I., COOPER D.G., BURLESON W., WOOLF B., MULDNER K., CHRISTOPHERSON B. (2009). Emotion Sensors Go To School, in V. DIMITROVA et al. (Ed.), Proc. AIED 2009, Amsterdam, IOS Press, p. 17-24. BECK J., CHANG K., MOSTOW J., CORBETT A. (2008). Does Help Help? Introducing the Bayesian and Assessment Methodology . Actes du Colloque Intelligent Tutoring Systems, Berlin, Springer, p. 383-394. BLANCHARD, E.G., FRASSON, C.,LAJOIE, S.P. (à paraitre, 2012). Learning with games. Dans Seel N. M. (Ed.), Encyclopedia of the Sciences of Learning. New York : Springer. BLOOM B. (1984). The 2 Sigma Problem: The Search for Methods of Group Instruction as Effective as One-to-One Tutoring. Educational Researcher, Vol. 13 n°6, p 3-16. BOYER K., PHILLIPS R., VOUK M., LESTER, J. (2008). Balancing Cognitive and Motivational Scaffolding in Tutorial Dialogue. Actes du Colloque Intelligent Tutoring Systems, Berlin, Springer, p. 239-249. BRUSILOVSKY P., PEYLO C. (2003). Adaptive and intelligent Web-based educational systems, IJAIED, Vol.13 n°2-4, p. 159-172. CHAN T-W., BASKIN A. B. (1990). Learning Companion Systems. Actes du Colloque Intelligent Tutoring Systems, Ablex, Norwood, NJ, p. 6-34. Plateforme de téléchargement CogSketch du Spatial Intelligence and Learning Center en ligne http://www.spatialintelligence.org/initiatives/tools/sketching.html (consulté le 22 juillet 2011) COHEN P., KULIK J., KULIK C. (1982). Educational outcomes of tutoring: A meta-analysis of findings, American Educational Research Journal, Vol. 2 n°19, p. 237-248. CONATI C., MITROVIC T. (2009). Closing the Affective Loop in Intelligent Learning Environments (Workshop), in V. DIMITROVA et al. (Ed.), Proc. AIED2009, Amsterdam, IOS Press, p. 810. DELOZANNE E., PRÉVIT D., GRUGEON B., CHENEVOTOT F. (2008). Automatic Multi-criteria Assessment of Open-Ended Questions: A case study in School Algebra. Actes du Colloque Intelligent Tutoring Systems, NY, Springer, p. 101-110. DENIS B.(2003) Quels rôles et quelle formation pour les tuteurs intervenant dans des dispositifs de formation à distance ? , Distances et savoirs Vol. 1, p. 19-46. DUBOULAY B., LUCKIN R. (2001). Modeling human teaching tactics and strategies for tutoring systems , IJAIED, Vol. 12 n°3, p. 1-24. DUBOULAY B. (2006). Commentary on Kurt VanLehn's The Behavior of Tutoring Systems. IJAIED, Vol. 16 n°3, p. 267-270. GEE, J. P.(2008) ‘Learning and Games.’ The Ecology of Games: Connecting Youth, Games, and Learning. Edited by Katie Salen. The John D. and Catherine T. MacArthur Foundation Series on Digital Media and Learning. Cambridge, MA: The MIT Press, p. 21-40 GRAESSER A., VANLEHN K., ROSÉ C., JORDAN P., HARTER D. (2001). Intelligent Tutoring Systems with Conversational Dialogue. AI Magazine, Vol. 22 n°4, p. 39-51. GRANDBASTIEN M. (1999). Teaching expertise is at the core of ITS research . IJAIED, Vol.10, p. 335-349. GREENHOW G., ROBELIA B., HUGHES J.E. (2009). Learning, Teaching, and Scholarship in a Digital Age. Web 2.0 and Classroom, Educational Researcher, n°38, p. 246-259. HAYASHI Y., BOURDEAU J., MIZOGUCHI R. (2009). Using Ontological Engineering to Organize Learning/Instructional Theories and Build a Theory-Aware Authoring System, IJAIED, Vol. 19 n°2, p. 211-252. JAILLET A., DEPOVER C., DE LIEVRE B, PERAYA D, QUINTIN Jean-Jacques (dir.) (2011) Le tutorat en formation à distance, De Boeck, Coll. Perspectives en éducation et formation, 288 pages, JOHNSON W. L., RICKEL J.W., LESTER J.C. (2000). Animated Pedagogical Agents: Face-to-Face Interaction in Interactive Learning Environments, IJSIE, n°11, p. 47-78. JOHNSON W. L., VALENTE A. (2009). Tactical Language and Culture Training Systems: Using AI to Teach Foreign Languages and Cultures. AI Magazine, Vol. 30 n°2, p. 72-83. LANE H.C., JOHNSON W.L. (2008). Intelligent tutoring and pedagogical expertise manipulation, in D. Schmorrow, J. Cohn, , D. Nicholson (Ed.) The PSI Handbook of Virtual Environments for Training and Education. Westport, CT: Praeger Security International. LESTER J. (2006). Reflections on the KVL Tutoring Framework: Past, Present, and Future, IJAIED, Vol.16 n°3, p. 271-276. MAYO, M., MITROVIC, A. (2001). Optimising ITS behavior with bayesian networks and decision theory, IJAIED, Vol. 12, p. 124--153. Mc NAMARA D., JACKSON G.T., GRAESSER A., Intelligent Tutoring and Games (ITaG), AIED 2009 worshop proceedings, available at http://people.ict.usc.edu/~lane/AIED2009-IEG-WorkshopProceedings-FINAL.pdf (consulté le 22 juillet 2011) MIZOGUCHI R., BOURDEAU, J. (2000). Using Ontological Engineering to Overcome Common AI-ED Problems , IJAIED, Vol. 11 n°2, p. 107-121. MORENO-GER P., BURGOS J. TORRENTE, J. (2009). Digital Games in eLearning Environments: Current Uses and Emerging Trends. Simulation and Gaming, Vol. 40 n°5, p. 669-687. MUFTI ALCHAWAFA, D., LUENGO, V. (2008). A decision-making process to produce adaptive feedback in learning environments for professional domains, ICHSL’6 : IEEE 6th International Conference on Human System Learning, Toulouse, May 14-16. MURRAY T. (1999). Authoring Intelligent Tutoring Systems: An Analysis of the State of the Art . IJAIED, Vol. 10, p. 98-129. MURRAY T., BLESSING S., AINSWORTH S. (2003). Authoring Tools for Advanced Technology Learning Environments, Kluwer Academic Publ., Netherlands. RAZZAQ L., HEFFERNAN N. (2009). To Tutor or not to Tutor: That is the Question. Actes du Colloque AIED, Amsterdam, IOS Press, p. 457-464. RAZZAQ L., PATVARCZKI J., ALMEIDA S., VARTAK M., FENG M., HEFFERNAN N. KOEDINGER K. (2009). The ASSISTment Builder: Supporting the Life Cycle of Tutoring System Creation. IEEE Tr. on Learning Technologies, Vol. 2 n°2, p. 157-166. SELF, J. (1999). The defining characteristics of intelligent tutoring systems research: ITSs care, precisely, IJAIED, Vol. 10, p. 350-364. SQUIRE, K. (2007). Games, learning, and society: Building a field. Educational Technology, Vol . 4 n°5, p. 51-54. TCHETAGNI J, NKAMBOU R. , BOURDEAU J. (2006). A Framework to Specify a Cognitive Diagnosis Component in ILEs. Journal of Interactive Learning Research. Vol. 17 n°3, Chesapeake, VA, AACE, p. 269-293 TCHETAGNI J., NKAMBOU R., BOURDEAU J. (2007). Explicit Reflection in Prolog-Tutor, IJAIED, Vol. 17 n°2, p. 169-217. ULLRICH, C. (2007), Course Generation as a Hierarchical Task Network Planning Problem, unpublished PhD Thesis, Computer Science Department, Saarland University. Saarbrücken VANLEHN K., (2006). The behavior of tutoring systems, IJAIED, Vol. 16 n°3, p. 227-265. VANLEHN K. (2008). The Interaction Plateau: Answer-Based Tutoring < Step-Based Tutoring = Natural Tutoring. Actes Colloque Intelligent Tutoring Systems, Berlin, Springer, p. 7. VANLEHN K., GRAESSER A., JACKSON G., JORDAN P., OLNEY A., ROSE C. (2007). When are tutorial dialogues more effective than reading? Cognitive Science, Vol. 31 n° 3, p. 3-62. VARMA S., MCCANDLISS B., SCHWARTZ D. (2008). Scientific and Pragmatic Challenges for Bridging Education and Neuroscience. Educational Researcher, Vol. 37 n°3, p.140 -152. WENGER E. (1987). Artificial Intelligence and Tutoring Systems. Los Altos, CA: Kaufman Publishers. WOOLF B. (2009). Building Intelligent Interactive Tutors: Student-centered Strategies for Revolutionizing E-learning. Burlington, MA, Morgan Kaufmann. ZHANG X., MOSTOW J., BECK J. (2008). A Case Study Empirical Comparison of Three Methods to Evaluate Tutorial Behaviors. Actes du Colloque Intelligent Tutoring Systems, Berlin, Springer, p. 152-162.
| ||||||||||||||||
Référence de l'article :Jacqueline BOURDEAU (LICEF, Montréal), Monique GRANDBASTIEN (LORIA, Nancy), La modélisation du tutorat dans les systèmes tutoriels intelligents, Revue STICEF, Volume 18, 2011, ISSN : 1764-7223, mis en ligne le 16/11/2011, http://sticef.org |


© Revue Sciences et Techniques de l'Information et de la Communication pour l'Éducation et la Formation, 2011