de l´Information et
de la Communication pour
l´Éducation et la Formation
version à télécharger (pdf)
Volume 16, 2009
Article de recherche
|
Contact : infos@sticef.org |
Modèles et outils pour rendre possible la réutilisation informatique de profils d’apprenants hétérogènes
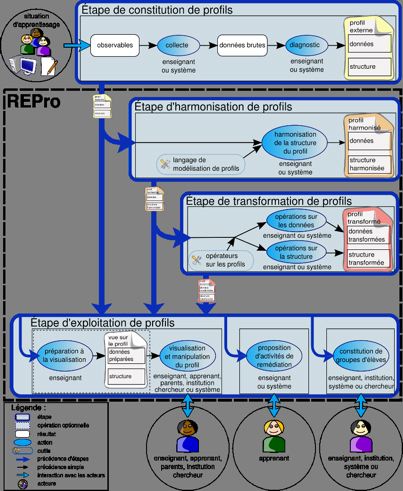
1. IntroductionDans le domaine de l’éducation, le profil d’apprenant fait l’objet d’attentions particulières, à la fois des praticiens, des chercheurs et des institutions. Concernant les praticiens, les enseignants du primaire et du secondaire sont incités à individualiser toujours plus l'apprentissage. Pour ce faire, ils ont besoin de rassembler des indicateurs de l’apprentissage de leurs élèves, point de départ nécessaire à la proposition de solutions de remédiation adaptées aux difficultés identifiées. Concernant les apprenants eux-mêmes, des recherches ont démontré l'intérêt de leur présenter des informations concernant l’état de leur connaissances en vue de les aider à développer des compétences réflexives et de renforcer leur motivation et leur responsabilisation face à leur apprentissage (Bull et al., 2007). Concernant les institutions, les initiatives menées autour des référentiels de compétences (telles que les évaluations nationales ou le livret personnel de compétences (BO_n°22, 2007)), les travaux de standardisation visant à favoriser l’échange de documents pédagogiques (IMS, 2001) (Pernin, 2006) ou encore le portfolio (Eyssautier-Bavay, 2004) montrent l'intérêt croissant des institutions éducatives nationales ou internationales pour élaborer des représentations communes des informations liées aux connaissances des apprenants. Concernant les concepteurs d'Environnements Informatiques pour l'Apprentissage Humain (EIAH), l’utilisation de profils (ou modèles) d'apprenants est l’un des moyens permettant d’adapter l’apprentissage aux spécificités des apprenants, c’est aussi une façon d'aider l'enseignant ou le tuteur dans sa tâche de suivi (Grandbastien et Labat, 2006). Diverses initiatives tentent de répondre à ces besoins variés, par la création et l’utilisation de nombreuses formes différentes de profils d’apprenants, mais force est de constater que ces initiatives restent souvent isolées, qu’elles demandent beaucoup de ressources aux acteurs concernés et que les résultats obtenus sont souvent décevants. Dans cet article, nous nous proposons de faire le point sur l’objet profil d’apprenant, afin de mettre en lumière sa richesse et son potentiel. Nous y présentons notre vision de la valorisation des travaux existants sur les profils à travers le projet PERLEA et nous présentons les modèles et outils que nous proposons dans ce contexte. Dans les travaux que nous présentons ici, nous nous intéressons à la problématique de la réutilisation de ces profils très divers, tant par leur contenu que par leur structuration, par les différents acteurs de la situation d'apprentissage. La première partie de cet article présente le contexte et la problématique du projet PERLEA, illustrés par un scénario d'usage, ainsi que des précisions sur le concept de profil d’apprenants et une revue de l'existant en lien avec ces recherches. La deuxième partie traite du processus de gestion et d’exploitation de profils : nous y présentons le modèle que nous proposons et sa mise en œuvre. Nous détaillons dans la troisième partie de l’article le processus de description de structures de profils, puis celui d’intégration de données externes dans la quatrième partie. Après un retour sur notre scénario d’usage initial, nous concluons cet article par un bilan des recherches présentées et une présentation des perspectives qui s'offrent à nous. 1.1. ContexteLe projet PERLEA (Profils d'Élèves Réutilisés pour L'Enseignant et l'Apprenant) (Jean-Daubias, 2003) vise à proposer d'une part des modèles pour la réutilisation et l’exploitation mutualisée des profils d'apprenants hétérogènes, existants ou à venir, papier-crayon ou logiciels, dans des contextes différents et par des acteurs autres que leur auteur, et d'autre part un environnement informatique à destination des enseignants mettant en œuvre ces modèles. Cet environnement informatique, nommé EPROFILEA, est constitué de deux parties : la préparation des profils et l’exploitation pédagogique de ces profils. Nous présentons dans cet article la première partie, indispensable et complexe, qui permet la réutilisation dans un même environnement informatique de profils très divers, de contenus et de structures différents. 1.2. Scénario d’usagePauline est enseignante en mathématiques au lycée et professeure principale d'une classe de seconde. Pour chacune de ses classes, elle utilise un référentiel de compétences de l’Éducation Nationale afin de constituer un profil de chacun de ses élèves en mathématiques. Elle utilise par ailleurs le logiciel Mathenpoche (Mathenpoche, 2002) lors de séances en salle informatique une fois par mois. En tant que professeure principale, elle propose à ses élèves de discuter une fois par mois de leurs notes dans toutes les matières, ainsi que de leur profil détaillé en mathématiques. À l'heure actuelle, faute de temps et de moyens techniques, elle ne peut pas intégrer les informations issues du logiciel Mathenpoche à sa pratique. Elle ne peut pas non plus, comme elle le souhaiterait, constituer de manière efficace un profil global intégrant les informations des différentes disciplines pour les élèves dont elle est professeure principale. Enfin, du fait de l'absence d'un logiciel pour supporter ces activités, elle ne peut pas proposer à ses élèves d'exploitations variées de leur profil. 1.3. DéfinitionsDans les recherches en EIAH, deux termes sont utilisés pour désigner des informations que l'on possède sur l'apprenant : « modèle » ou « profil » de l'apprenant. Si l’on trouve plus souvent le terme de « modèle » dans les recherches en EIAH, on emploie plus fréquemment celui de « profil » dans le milieu éducatif. Alors que le terme de modèle correspond à la modélisation générique des apprenants dans un système informatique, celui de profil fait référence aux informations concernant un individu donné dans un contexte donné. Le profil de l’apprenant peut être considéré comme l’instanciation du modèle de l’apprenant dans le système. Ainsi, dans nos travaux, nous préférons utiliser le terme « profil » d'apprenant, comme le font par ailleurs (Keenoy et al., 2004), (Vassileva et al., 2003), (Villanova-Oliver, 2002). Nous définissons un profil d'apprenant comme un ensemble d'informations interprétées, concernant un apprenant ou un groupe d'apprenants, collectées ou déduites à l'issue d'une ou plusieurs activités pédagogiques, qu’elles soient ou non informatisées. Les informations contenues dans le profil de l’apprenant peuvent concerner ses connaissances, compétences, conceptions, son comportement, ou encore des informations d’ordre métacognitif. Les profils représentent les spécificités de chaque apprenant en opposition avec les profils-type caractérisant des regroupements de profils ressemblants. Notons enfin que les données d’un profil sont définies selon une structure précise. Cette structure est indépendante des données d'un apprenant particulier et peut être partagée : elle peut être utilisée pour les profils de plusieurs apprenants, alors que les données sont personnelles et relèvent de l'apprenant ou du groupe d'apprenants concerné par le profil. L’objet profil d'apprenant recouvre une grande diversité. Les profils d’apprenants peuvent être créés à la demande de différents acteurs de la situation d’apprentissage : l'enseignant, afin de suivre l’évolution de l’apprentissage de ses élèves dans l'année ; l'institution, pour suivre celle de l’ensemble des apprenants (M.E.N.EducEval, 2008) ; ou encore l'apprenant lui-même afin de suivre l’évolution de ses connaissances. Par ailleurs, les profils sont constitués dans le but d'être exploités par différents destinataires, humains ou logiciels. Les profils créés par un enseignant sont destinés à être exploités par ce même enseignant, par l'institution scolaire, parfois par l'apprenant concerné ou sa famille. Les profils créés par un système informatique sont la plupart du temps destinés à être exploités par le système lui-même. Toutefois, certains logiciels « externalisent » leurs profils, c’est-à-dire qu’ils les rendent visibles de l’extérieur, ce principalement à destination de l'apprenant et de l'enseignant (Paiva et al., 1995) ; d’autres créent même des profils avec pour but principal de les communiquer aux acteurs humains, c’est l’approche adoptée par les recherches sur les modèles de l’apprenant ouverts (Bull et Kay, 2007). De plus, les profils d’apprenants ont différentes origines. Certains sont constitués de façon automatique par un logiciel comportant un modèle de l’apprenant, d’autres sont issus des pratiques des enseignants, pouvant s'appuyer sur des documents de référence (programmes scolaires ou référentiels de compétences), le plus souvent sous forme papier, mais parfois sous forme numérique (tableur par exemple). Nous pouvons en outre différencier les profils selon la nature des informations qu'ils comportent : d'une part les profils d’utilisation, qui rendent compte de l’utilisation qu’a fait l’apprenant du logiciel, tel que le temps qu’il a mis pour effectuer l’activité, et d'autre part les profils conceptuels, qui correspondent aux modèles conceptuels de l’apprenant en rendant compte des connaissances ou métaconnaissances de l’apprenant, de ses compétences ou de ses conceptions (Balacheff, 1994). La forme de ces informations peut également varier. Une compétence peut être valuée par une note (« 3/7 »), un taux de réussite (« 87% »), un critère d’analyse (« connaissance partiellement maîtrisée »), une appréciation (« en progrès »), ou encore un commentaire de type métacognitif (« je pense maîtriser cette compétence »). Enfin, dans un profil créé par un logiciel, il faut distinguer sa représentation interne (celle qu'utilise le logiciel pour stocker le profil, sous forme de faits, règles, graphes conceptuels...), de sa représentation externe (celle qui est proposée aux destinataires : sous forme textuelle, numérique, graphique, de graphe notionnel, ou encore d'images indiquant le niveau atteint), et de son format de stockage (tableur, base de données, fichier XML ou texte...). Pour compléter, notons que pour un même apprenant, il est possible de disposer de plusieurs profils qui représentent l’état de ses connaissances dans des domaines différents, selon des points de vue différents, dans des contextes différents et parfois aussi à différents moments. L’une des difficultés dans la réutilisation de profils est de réussir à prendre en compte toute cette diversité. 1.4. Les environnements de réutilisation et d’exploitation de profilsLes systèmes qui permettent de gérer et d’exploiter des profils d’apprenants sont rares, mais il existe de nombreux logiciels de gestion de notes conçus soit par les enseignants eux-mêmes, comme Moyennes et Fnotes, soit par des éditeurs, comme WCarNote, CANOE et Almuce. Ces logiciels permettent aux enseignants de saisir les notes de leurs élèves pour une matière ou une classe donnée, mais disposent aussi, selon les systèmes, de fonctionnalités complémentaires : création de moyennes avec coefficients ou non, ajout d’appréciations, visualisation de notes ou de l'évolution des résultats des élèves dans le temps, création de profils de classe, exportation ou impression de notes, gestion des données personnelles des élèves (telles les dates de naissance et redoublements). Ces logiciels, prévus pour un usage en collège ou lycée, gèrent uniquement des notes et appréciations globales pour chaque matière, ils ne sont donc pas compatibles avec des profils plus complexes et les exploitations proposées se limitent à des traitements statistiques. Le logiciel J'ADE (J'ADE, 2007) édité par le ministère de l'Éducation Nationale française est associé aux évaluations qui établissent un suivi national d’une classe d'âge (M.E.N.EducEval, 2008). Ce logiciel permet aux enseignants de saisir les résultats de cette évaluation et fournit par ailleurs des outils (comme la constitution de graphiques) pour leur permettre d'en exploiter les résultats. Ces exploitations sont limitées à quelques traitements statistiques, mais la principale limite de ce logiciel est inhérente à son objectif : étant spécifique aux évaluations nationales, il n’est pas ouvert à d’autres profils. Le système ViSMod (Zapata-Rivera et Greer, 2004) est plus ouvert quant à la source des profils, puisqu’il permet la visualisation par l'apprenant et l'enseignant d'un modèle de l'apprenant provenant d'un autre système informatique. Toutefois ce système doit être représenté sous forme de réseau bayésien, ce qui exclut nombre de profils issus d’EIAH, ainsi que la plupart des profils papier-crayon créés par des enseignants. Le système DynMap+ (Rueda et al., 2006) permet la visualisation sous forme de cartes conceptuelles d'un modèle d'apprenant de type réseau bayésien constitué par d’autres systèmes informatiques. Les données sont traduites par DynMap+, au moyen d’un traducteur implémenté spécifiquement et manuellement pour chaque EIAH source, dans un formalisme XML interne à DynMap+. Ce formalisme est composé de deux parties : la définition des données du domaine et la définition des données d'apprentissage de l’apprenant. S’il prévoit une traduction automatique des profils externes connus, ce système ne prévoit toutefois pas de procédure automatisée pour la prise en compte de nouveaux profils externes. De plus, il se limite, comme le précédent, aux réseaux bayésiens. (Ramandalahy et al., 2009) adoptent une approche légèrement différente. Ils proposent un modèle du profil de l’apprenant, pouvant être étendu, intégrant IMS-LIP ainsi qu’un certain nombre d’éléments d’ordre cognitif et métacognitif. Ce modèle est mis en œuvre de manière à enrichir des profils d’apprenants à partir d’applications hétérogènes. La limite principale de cette approche du point de vue de notre problématique, est son manque de souplesse : la prise en compte d’un élément de profils non prévu demande la modification du modèle en amont et de l’application. Ainsi, s’il existe des systèmes permettant de manipuler l’objet profil d’apprenant, aucun n’adopte une démarche suffisamment générique pour traiter facilement tous les types de profils. De plus, les exploitations proposées s’arrêtent à des visualisations plus ou moins poussées et ne permettent pas d’exploiter pleinement la richesse des informations que peuvent contenir les profils. Nos travaux de recherche nous permettent d’envisager de lever les verrous empêchant une exploitation unifiée et poussée des profils d’apprenants de tous types. Pour cela, nous adoptons une approche générique en proposant une modélisation du processus de gestion et d’exploitation des profils d’apprenants et une mise en œuvre adaptée aux enseignants. 2. Le processus de gestion et d’exploitation de profils d’apprenantsDans le projet PERLEA, nous étudions de façon approfondie l’objet profil d’apprenant : son cycle de vie, comment le représenter à l’aide d’un formalisme commun, afin de proposer des outils génériques de gestion et d’exploitation de profils. Ainsi, nous proposons un modèle du processus de gestion de profils (REPro : Reuse of External Profiles (Eyssautier-Bavay, 2008) (Eyssautier-Bavay et Jean-Daubias, 2009)), que nous mettons en œuvre au travers de l'environnement EPROFILEA. 2.1. REPro, un modèle de processus de gestion de profilsLe modèle REPro (cf. Figure 1) donne les moyens de comprendre le processus de gestion et d’exploitation de profils en modélisant la chaîne des traitements nécessaires pour aller de la situation d'apprentissage initiale jusqu'à l'exploitation des profils par les différents acteurs. L'étape de constitution de profils d'apprenants, qui se situe en amont de REPro, représente la constitution d'un profil initial par des logiciels ou des enseignants, à partir d'une situation d'apprentissage particulière, informatisée ou non. Nous distinguons dans le profil ses données de sa structure. Figure 1 : Modèle REPro Habituellement, un enseignant ou un système informatique constituant un profil d'apprenant le fait pour l'exploiter lui-même : l'étape de constitution de profils est donc directement suivie de l'étape d'exploitation de profils. Dans une perspective de réutilisation de profils existants, créés par d'autres, la nature et la structure des informations recueillies, qui peuvent être hétérogènes, ne sont pas connues. Leur réutilisation nécessite par conséquent une étape d'harmonisation de profils. L'harmonisation prend en entrée le profil externe que l'on souhaite réutiliser, sous forme papier-crayon ou numérique, et consiste en la réécriture par l'enseignant, assisté ou non d'un système informatique, de la structure du profil selon un formalisme donné prédéfini : le langage de modélisation de profils. Seule la structure du profil est concernée par cette harmonisation, les données n'ayant pas besoin d'être modifiées. À l'issue de cette opération, un profil harmonisé est établi : un profil à la structure conforme au langage de modélisation de profils comportant les données du profil initial. Une fois les profils harmonisés, il est possible de passer soit directement à l'étape d'exploitation, soit à l'étape de transformation de profils. Cette dernière permet de réaliser des opérations sur les profils, comme filtrer les informations, ou constituer un profil de groupe à partir des profils individuels. Enfin, l'étape d'exploitation des profils permet aux différents acteurs de la situation d'apprentissage d'exploiter les informations du profil de l'apprenant en fonction de leurs rôles respectifs. 2.2. EPROFILEA, un environnement réutilisant des profils d’apprenantsL’environnement EPROFILEA met en œuvre le modèle REPro pour proposer des outils génériques de gestion et d’exploitation de tous types de profils permettant à chaque enseignant de travailler avec ses propres profils selon ses besoins et ses habitudes de travail. Les profils utilisés peuvent être issus de sources diverses, évaluations papier ou profils logiciels, et contenir des informations caractérisant les connaissances, métaconnaissances, compétences et/ou comportements des apprenants, pour tous niveaux, de l’école élémentaire à l’université sans oublier la formation continue, ce, dans toutes les disciplines. L’articulation entre la généricité de l’environnement EPROFILEA et la spécificité des besoins des enseignants se fait par la définition par les enseignants de la structure décrivant les profils qu’ils souhaitent manipuler. C’est l’instanciation de cette structure de profils, avec les données correspondant aux connaissances de ses élèves (données issues de profils externes : logiciels ou papier-crayon), qui crée les profils d’apprenants conformes au formalisme de l’environnement. Une même structure de profils permet donc de créer autant de profils que l’enseignant a d’élèves. Par ailleurs, EPROFILEA permet de créer autant de structures de profils que nécessaire, chacune adaptée aux besoins et aux spécificités de son utilisateur. Un professeur principal créera ainsi par exemple deux structures de profils : l’une donnant une vue d’ensemble de chaque discipline suivie par ses élèves et l’autre détaillant tous les points traités dans la discipline qu’il enseigne, intégrant son travail papier-crayon et les profils des EIAH qu’il utilise. L’environnement EPROFILEA comporte deux parties : la préparation de profils conformes à l’environnement, c'est-à-dire exprimés selon un même formalisme qui rend possible leur réutilisation, et leur exploitation (cf. Figure 2). C’est la première partie (correspondant au cadre large dans la figure) qui fait l’objet de cet article. 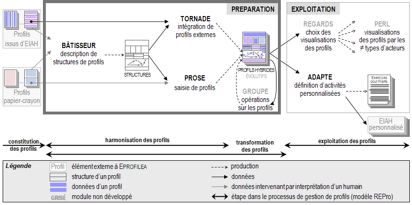
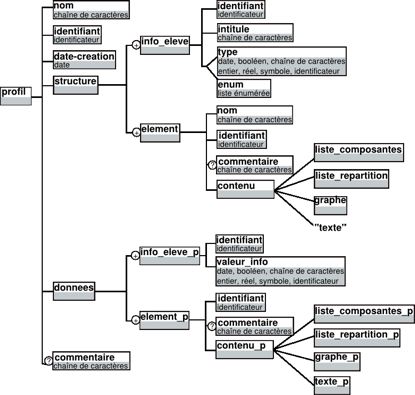
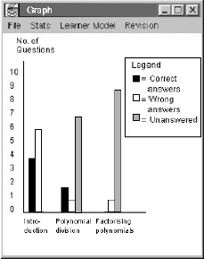
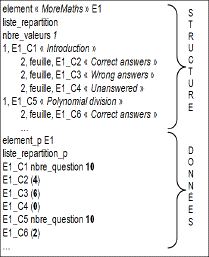
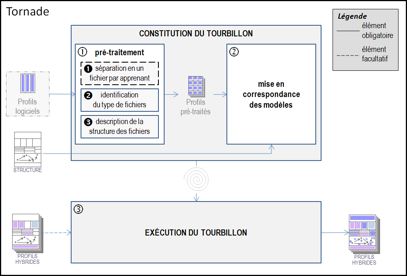
Figure 2 : Architecture de l’environnement EPROFILEA La première partie de l’environnement, consacrée à la préparation des profils, correspond à l’étape d’harmonisation du modèle REPro. Elle consiste pour l’enseignant à établir la structure des profils qu’il souhaite manipuler, avant d’y intégrer les données issues des profils externes. Cette étape permet de constituer des profils d’apprenants conformes au souhait de l’enseignant et respectant le formalisme d’EPROFILEA. La description de la structure des profils est élaborée par l’enseignant dans le module Bâtisseur (cf. section 3.3) qui opérationnalise le langage de modélisation de profils PMDL (cf. section 3.2) dans EPROFILEA. En opérationnalisant ce langage, Bâtisseur permet à l’enseignant d’exprimer la structure des profils préexistants, qu’ils soient issus d’EIAH ou papier-crayon, quels que soient les types d’informations qu’ils contiennent. Compléter la structure de profils créée dans Bâtisseur avec les données personnelles des apprenants pour constituer les profils se fait de façons différentes selon que les données sont issues de profils papier-crayon ou d’un EIAH. Dans le cas de profils papier-crayon, EPROFILEA comporte un assistant, Prose, aidant l’enseignant à saisir les données de chacun de ses apprenants selon la structure de profils définie dans Bâtisseur (cf. section 4.3). Dans le cas de profils issus de logiciels, EPROFILEA propose des systèmes de conversion de profils (les « tourbillons »), interfaces entre les logiciels externes et EPROFILEA, ainsi qu’un module, Tornade, assistant un enseignant-expert dans la constitution de tourbillons adaptés aux EIAH dont on souhaite réutiliser les profils (cf. section 4.2). Les profils ainsi créés peuvent être hybrides, c'est-à-dire provenir de plusieurs sources (différents EIAH et/ou différentes activités papier-crayon), la structure de profils sera alors instanciée à la fois dans Prose avec des données papier-crayon et dans Tornade avec des données provenant de profils logiciels. Les profils résultants reposant sur un formalisme commun, ils donnent accès aux deux types d’exploitations proposées par EPROFILEA : visualisations riches et propositions d’activités personnalisées. Pour les visualisations, l’enseignant commencera par établir dans le module Regards différentes vues d’un même profil, adaptées à chaque acteur de la situation d’apprentissage. Pour construire ces vues, il choisira les parties du profil qui seront consultables par l’acteur concerné, le vocabulaire utilisé ou encore le mode de présentation des informations à l’interface. Les modules Perl permettront la visualisation interactive des profils par les différents acteurs selon les vues déterminées par l’enseignant dans Regards. Pour l’apprenant, le module Perl proposera en plus de leur visualisation, des activités autour des profils (reformulation, négociation des éléments du profil, etc.) permettant à l’apprenant d’entrer dans une démarche réflexive par rapport à son apprentissage. Pour la proposition d’activités personnalisées, le module Adapte propose aux apprenants des activités adaptées aux compétences et connaissances mises en évidence par leur profil (Lefevre et al., 2009b) selon les préférences pédagogiques de l’enseignant : activités papier-crayon (Lefevre et al., 2009a) ou activités logicielles gérées par un EIAH externe (Lefevre et al., 2009c). Pour proposer des activités papier-crayon, Adapte crée une feuille d’exercices pour chaque profil d’apprenant en générant les exercices qui la composent. Dans le cas d’activités logicielles, Adapte personnalise l’interface de l’EIAH, ainsi que les séquences de travail proposées aux apprenants. Cette personnalisation passe par l’utilisation des générateurs d’exercices éventuellement contenus par les EIAH et par le paramétrage des fichiers de configuration de chaque EIAH. Nous venons de voir que l'environnement EPROFILEA est composé de deux parties (cf. Figure 2) : la préparation des profils (intégrant les étapes d'harmonisation de la structure des profils et de transformation des profils du modèle REPro) et l'exploitation des profils par les acteurs (correspondant à l'étape d'exploitation dans le modèle REPro). L’étape de constitution de profils, présente en amont de REPro, n’est pas traitée dans EPROFILEA, mais préalablement, par les acteurs, humains ou logiciels, à l’origine des profils externes. Nous revenons maintenant sur la partie préparation (matérialisée par un cadre gras sur la Figure 2). Nous présentons dans la partie suivante de l’article les moyens que nous mettons en œuvre pour harmoniser la structure des profils, puis nous montrons, dans la quatrième partie, comment l’intégration des données des profils est traitée dans EPROFILEA. La partie de l’environnement qui concerne l’exploitation des profils étant hors du propos de cet article centré sur les moyens permettant la réutilisation de profils. 3. Description de structures de profils d’apprenantsDans nos travaux, nous nous intéressons à la question de la réutilisation de profils d'apprenants créés par d'autres, dont nous ne connaissons ni le contenu ni la structure. Nous avons présenté dans la partie précédente les grandes lignes du modèle REPro, modélisant la suite d'étapes nécessaires à cette réutilisation, en insistant sur l'étape d'harmonisation de profils. Cette étape permet la réécriture des profils externes, issus d'EIAH ou de pratiques des enseignants, selon un formalisme commun. Dans cette section, nous présentons les enjeux de cette étape d’harmonisation et l’approche que nous adoptons. Nous exposons les travaux traitant de la réutilisation de profils, ainsi que la mise en œuvre que nous avons faite. L’harmonisation des structures de profils est cruciale pour la réutilisation de profils externes. C’est cette harmonisation qui permet l’expression de profils divers selon un même formalisme, rendant ainsi possible des traitements variés mais communs sur ces profils. La difficulté et l’intérêt de ce travail résident dans la recherche d’une approche générique, c’est-à-dire permettant la prise en compte des profils dans toute leur diversité, souple, c’est-à-dire n’imposant pas un formalisme particulier, mais s’adaptant au contraire aux formalismes existants, et adaptée aux utilisateurs, principalement des enseignants. L’approche que nous proposons répond à ces contraintes. Nous avons en effet établi un langage générique de description de profils, permettant de décrire la plupart des profils existants, quels que soient la discipline ou le niveau concernés, caractérisant les connaissances, métaconnaissances, compétences, comportement et/ou habitudes de travail des apprenants. Nous avons opérationnalisé ce langage dans un logiciel adapté aux enseignants, leur permettant de convertir les profils externes existants qu’ils utilisent pour les rendre conformes au formalisme utilisé dans notre environnement, permettant ensuite une exploitation de ces profils. Nous exposons ici ce langage et son opérationnalisation, après une présentation des travaux de recherche traitant de la réutilisation de profils. 3.1. Travaux existants concernant la réutilisation de profilsUne des solutions au problème de la réutilisation de profils hétérogènes existants par des acteurs autres que leurs créateurs consiste en la définition consensuelle a priori de ce qu'est un ensemble d'informations sur l'apprentissage d'un individu. C'est l'approche choisie par les travaux sur la normalisation des données personnelles des apprenants, dans laquelle la réutilisation des profils ne nécessite pas d’étape d’harmonisation. Cette étape est en effet rendue inutile par la normalisation qui précède la constitution des profils. Cette approche favorise la réutilisation des profils, mais uniquement pour ceux qui respectent la norme concernée. En l’absence de norme universelle, cette approche n’est pas suffisante pour permettre la réutilisation de tous types de profils. Par ailleurs, les informations les plus pertinentes dans notre contexte de travail ne sont pas décrites suffisamment précisément dans les standards existants. En effet, un profil d'apprenant représente des informations sur les connaissances de l'apprenant à un niveau de granularité fin, alors que les standards cherchent plutôt à faciliter le stockage et l'échange des données pour fournir une aide à la gestion des institutions éducatives, ce qui explique qu'ils s'intéressent à des informations de niveau de granularité plus élevé (Keenoy et al., 2004). Ainsi, le standard PAPI ne fait pas mention des compétences, connaissances ou conceptions de l'apprenant, ni des structures que peuvent avoir ces informations (PAPI, 2002). Le standard IMS_RDCEO permet quant à lui de décrire précisément des compétences (IMS_RDCEO, 2002), mais ne contient pas de données individuelles. Le standard IMS-LIP permet de représenter les différentes compétences et connaissances acquises par un apprenant particulier, mais ne décrit pas les relations des compétences entre elles, ni leur association à un ou plusieurs résultats d'évaluation (IMS-LIP, 2001). Enfin, nous partageons l'avis de (Keenoy et al., 2004) pour qui ces informations, stockées sous forme de texte libre, ne sont pas facilement exploitables par un système informatique, ce qui est une limite importante au vu de notre approche. Une autre approche, dans laquelle nous nous inscrivons, vise à réutiliser des profils externes au sein d'un environnement informatique unique en les réécrivant a posteriori selon un formalisme interne. Nous avons ainsi présenté en section 1.4 les (Zapata-Rivera et Greer, 2004)-Rivera et (Rueda et al., 2006)ap (Rueda et al., 2006) qui réécrivent d'une part les données du domaine étudié (en recréant le réseau bayésien dans le cas de ViSMod), et d'autre part les données de l'apprenant considéré. Dans nos recherches, nous ne reconstituons pas le modèle de connaissances du domaine, nous considérons seulement les données de l'apprenant au temps t. De plus, l'approche de Rueda est centrée activité, alors que la nôtre est centrée compétences et connaissances. Par ailleurs, dans ViSMod et DynMap, l'enseignant intervient peu et ses pratiques ne sont pas prises en compte, seuls les profils issus d'EIAH étant considérés. Enfin, ces approches ne permettent pas de représenter certaines informations présentes dans les profils existants(Ramandalahy et al., 2009)mandalahy et al., 2009), ils sont certes évolutifs, ce qui laisse envisager la prise en compte de profils variés, mais ils manquent de souplesse : tout changement nécessite une modification du logiciel et préalablement du modèle sous-jacent. 3.2. Principes du langage PMDLNous avons vu que l’approche que nous proposons pour la réutilisation de profils externes hétérogènes passe par une étape d’harmonisation conduisant à une représentation unifiée de leur structure et des données associées, ce qui nécessite un formalisme interne commun de description de profils. Nous proposons un tel formalisme à travers le langage de description de profils PMDL (Profiles MoDeling Language), (Jean-Daubias et al., 2009), (Eyssautier-Bavay, 2008). Notre travail s’appuie sur une revue de l'existant en termes de profils que nous avons conduite sur des logiciels issus de la recherche, du marché et de pratiques d'enseignants. Nous avons notamment travaillé avec sept enseignants, de l'école primaire à l'université, en passant par la formation continue, afin de recueillir leurs pratiques concernant les profils, ainsi que les pratiques institutionnelles (telles que les évaluations nationales). À partir de cette étude, nous avons sélectionné une vingtaine de profils jugés particulièrement intéressants, que nous avons étudiés de façon détaillée afin de proposer une catégorisation des informations contenues dans ces profils. Nous avons répertorié cinq catégories d’informations : les informations sur l’élève, les informations sur ses connaissances sous forme de texte, de listes de composantes, de listes de répartition et de graphe. Cette catégorisation nous a permis d’établir un langage de modélisation de profils, PMDL, qui permet de décrire les profils à l'aide des cinq catégories identifiées. 3.2.1. Structuration générale de PMDLFigure 3 : Structuration générale simplifiée de PMDL La Figure 3 présente la structuration gén&eacu1rale du langage PMDL1. Ce langage décrit un profil comme étant constitué d'un nom, d'un identifiant, d'une date-creation, d'une partie structure, d'une partie donnees et éventuellement d'un commentaire. Nous retrouvons ici la dualité structure / données mise en évidence dans la section 1.3. La partie structure est composée d'une ou plusieurs informations générales sur l'élève, info_eleve. Une info_eleve est constituée d'un identifiant, d'un intitule de type chaîne de caractères (par exemple « ville de résidence ») et soit d'un type (« chaîne de caractère » dans cet exemple), soit d'une liste énumérée, enum (par exemple « Lyon, Villeurbanne, Bron »). La partie structure de profils est également composée d'un ensemble non vide d'element. Un element est constitué d'un nom (par exemple « algèbre » ou « MoreMaths »), d'un identifiant, éventuellement d'un commentaire et d'un contenu, qui peut être de quatre types : liste_composantes, liste_repartition, graphe et texte. Ces quatre types auxquels s’ajoute info_eleve correspondent aux cinq catégories d'informations que nous avons identifiées suite à notre étude de l’existant. Chacune de ces catégories donne lieu à des spécifications dans le langage PMDL que nous exposons succinctement ici avant de détailler un element de type liste_repartition à titre d’exemple. La partie donnees du profil est composée, comme la partie structure, d'un ensemble d'informations sur l'élève, ainsi que d'un ensemble d'element_p. Une info_eleve_p est constituée d'un identifiant et d'une valeur_info. Il existera autant d'info_eleve_p (respectivement element_p) que d'info_eleve (respectivement element) précédemment déclarés. Par ailleurs, pour chaque identifiant d'element déclaré, il existera un element_p qui reprendra cet identifiant en lui associant un contenu_p de même type que le contenu précédemment déclaré. Il en sera de même pour les info_eleve. 3.2.2. Exemple d’un element de type liste_repartitionPour illustrer ce langage, prenons l’exemple de la version mobile du profil MoreMaths (Bull et al., 2003) qui comporte des informations de type liste_repartition (cf. Figure 4). Ce profil comporte trois composantes : « Introduction », « Polynomial division » et « Factorising polynomials », chacune ayant les trois mêmes sous-composantes « Correct answers », « Wrong answers » et « Unanswered ». Ce profil permet de représenter la répartition des réponses de l'apprenant entre non réponse, réponse correcte et réponse fausse pour chacune des composantes. Ici, l'apprenant concerné a donné 6 réponses fausses et 4 correctes pour la composante « Introduction ». La Figure 5 représente un extrait de ce même profil réécrit (à la main) selon les spécifications du langage PMDL pour ce type d'element.
Nous y trouvons en premier lieu la description de la structure de ce profil, et en second lieu la description des données de l'apprenant concerné. Dans la partie structure, les composantes sont décrites telles que définies dans MoreMaths : au niveau 1, on trouve les composantes « Introduction », « Polynomial division » et au niveau 2, comme feuilles de l'arbre des composantes, les sous-composantes « Correct answers », « Wrong answers » et « Unanswered » pour chacune des composantes. Un identifiant est associé à chaque composante et sous-composante (E1_C1 pour la première composante). Dans la partie données, le nombre de questions parmi lesquelles s'effectue la répartition des réponses de l'apprenant est associé aux composantes (dans cet exemple : 10). Enfin, les valeurs sont associées aux composantes de niveau terminal. On retrouve ainsi les 6 réponses fausses et les 4 réponses correctes de l'apprenant de l'exemple pour la composante « Introduction ». Le langage PMDL permet ainsi de réécrire les profils externes selon un formalisme commun, ce qui rend possible le traitement et l'exploitation de ces différents profils dans un même environnement, tel qu'EPROFILEA. Nous présentons maintenant la mise en œuvre de PMDL au sein de cet environnement. 3.3. Mise en œuvre de PMDL au sein de BâtisseurLe module Bâtisseur de l'environnement EPROFILEA permet à l'enseignant de décrire la partie structure du profil telle que spécifiée dans le langage PMDL. La partie donnees contenant les informations personnelles d'un apprenant est renseignée séparément et ultérieurement au sein des modules Tornade et Prose présentés dans la partie suivante. Dans la section 3.2.1, nous avons identifié cinq types de structures d’informations contenues dans un profil : quatre pour exprimer les informations issues de l’analyse de l’activité de l’apprenant et un regroupant les informations générales sur celui-ci. À l’aide du module Bâtisseur, les enseignants décrivent la(les) structure(s) des profils qu’ils souhaitent manipuler. Chaque structure de profils possède un ensemble d’attributs : un identifiant unique, un nom, le nom de son créateur, sa date de création, sa date de dernière modification, un statut (public ou privé), etc. Les attributs de chaque structure de profils sont reportés sur les profils issus de cette structure. Pour permettre la description de la structure de profils, Bâtisseur s’appuie sur la métaphore de la construction d’un mur de briques, où chaque brique est un élément de la structure de profils. Quatre types de briques sont proposés : « commentaire », « liste », « répartition » et « graphe ». Ces types de briques respectent les spécifications des quatre principaux types d'element du langage PMDL. Quant aux informations correspondant au cinquième type, info_eleve, concernant l’identification de l’apprenant, nous avons choisi de les gérer de manière globale au sein d’EPROFILEA, on ne les retrouve donc pas dans Bâtisseur. Ainsi, un enseignant utilisant EPROFILEA peut créer ses classes et associer ses apprenants à une classe donnée en fournissant les informations relatives à chacun : nom, prénom, âge, etc. De cette manière, un apprenant pourra avoir plusieurs profils, par exemple un par matière étudiée, et chaque enseignant n’aura pas à ressaisir ou à réimporter les informations générales de l’apprenant pour chacun des profils.
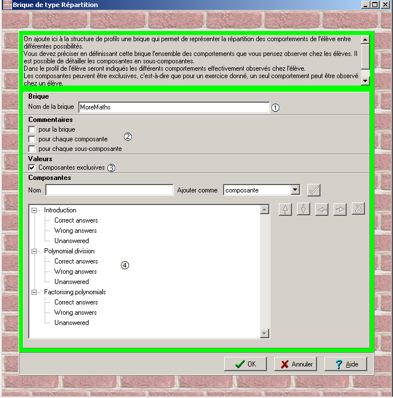
3.3.1. Les quatre types de briques de BâtisseurLes briques de type Commentaire, qui correspondent à l’element texte dans le langage de description de profils PMDL, permettent de représenter des informations sous forme textuelle. Elles correspondent à des zones de texte libre, sans aucune contrainte sur l’organisation des données qui y sont portées. Les briques de type Liste (liste_composantes dans PMDL) permettent de décrire des informations sous forme de liste hiérarchique. Avec ce type de briques, un enseignant peut décrire ses informations sous forme d’un ensemble de composantes, chacune pouvant être détaillée en sous-composantes. Le nombre de niveaux possibles dans la liste hiérarchique est une variable globale à l’environnement EPROFILEA que chaque enseignant peut modifier selon ses habitudes de travail. Cette variable est fixée à trois par défaut : cela permet de représenter la majorité des profils que nous avons pu étudier, tout en limitant la profondeur de la hiérarchie afin de simplifier l’utilisation de l’environnement. Dans le profil de l’apprenant (partie donnees), les valeurs seront attribuées aux composantes de niveau hiérarchique le plus bas. Ces valeurs seront caractérisées par les informations définies par l’enseignant lors de la création de la brique (partie structure) : le nombre de valeurs associées à chacune des composantes (par exemple 2 valeurs), leurs echelles (par exemple une note entre 0 et 20 pour la première valeur et un nombre entier positif pour la seconde) et éventuellement l’unite correspondante (par exemple rien pour la première valeur et « minutes », correspondant à une durée de travail, pour la seconde valeur). Nous reviendrons sur les échelles dans la section 3.3.3. Les briques de type Répartition permettent de décrire la répartition des réponses d’un apprenant entre différentes possibilités listées. Ces briques correspondent à l'element liste_repartition du langage PMDL. De la même manière que dans les briques de type Liste, les alternatives sont définies avec des composantes qui peuvent être détaillées en sous-composantes. Ce type de briques permet de représenter le comportement d’un apprenant par rapport à des comportements attendus, en comptant le nombre de fois où celui-ci a mis en œuvre les différents comportements. Les valeurs associées à ce type de briques sont ainsi des valeurs de comptage et donc des valeurs numériques sans échelle. Les composantes peuvent être exclusives, dans ce cas on ne peut observer qu’un seul comportement à la fois chez l’apprenant. Un exemple de brique de type Répartition, détaillé par la suite, est donné Figure 6. Les briques de type Graphe, correspondant à l'element graphe de PMDL, permettent de décrire des informations sur l’apprenant sous forme de graphe. On représente donc des composantes (les sommets du graphe), mais également les liens qui peuvent exister entre elles (les arcs du graphe). Ces composantes ne sont pas décomposables en sous-composantes contrairement aux briques des deux types précédents. Dans ce type de briques, on peut associer aux composantes et/ou aux liens entre composantes un certain nombre de valeurs, associées à des echelle et éventuellement complétées d’unite. 3.3.2. Exemple d'une brique de type RépartitionFigure 6 : Brique "MoreMaths" de type Répartition dans Bâtisseur Reprenons ici l’exemple de la brique MoreMaths décrite précédemment (cf. section 3.2.2). La Figure 6 présente l’écran proposé par Bâtisseur à un enseignant pour construire une brique de type Répartition. Notons que l’interface de Bâtisseur est générée dynamiquement en fonction d’une description opérationnelle de PMDL, sous forme d’un fichier XML. Pour créer la brique « MoreMaths », de type répartition, l’enseignant indique le nom de celle-ci (le nom de l'element dans PMDL), puis précise si des commentaires seront associés à chaque niveau de l’arbre des composantes et/ou globalement pour la brique (champs commentaire de l'element et de la composante dans PMDL). Ici la répartition est exclusive car un apprenant ne pourra pas avoir une réponse correcte en même temps qu’une réponse fausse (cette notion de réponses exclusives, spécifique à l’implémentation, n’existe pas dans PMDL). Une fois ces informations fournies, l’enseignant peut créer l’arbre des composantes (expression du niveau de chaque composante dans PMDL) en précisant pour chacune son nom (champ intitule de chaque composante dans PMDL).
Figure 7 : Extrait de la structure de profils de la brique "MoreMaths" La Figure 7 montre le résultat de la création de cette structure de profils MoreMaths, stocké sous forme d’un fichier XML par Bâtisseur. Nous retrouvons bien la brique « MoreMaths » ( sur la Figure 7) contenant un arbre de composantes à deux niveaux , avec des composantes exclusives . On retrouve également les intitulés des composantes et des sous-composantes décrites par l'enseignant dans Bâtisseur. Cette structure de profils sera ensuite instanciée dans le module d’intégration de données logicielles de l’environnement EPROFILEA en complétant le nom du logiciel concerné , le nb de questions , puis les différentes valeurs avec les données de chaque apprenant. 3.3.3. La notion d'échelleDans les profils des apprenants, les valeurs qui seront affectées aux composantes, sous-composantes, ainsi qu’aux sommets et arcs des graphes, sont caractérisées par des échelles que les enseignants choisissent lors de la création de la structure du profil dans Bâtisseur. Une échelle est un ensemble de valeurs généralement ordonnées et sémantiquement liées. Dans PMDL, les échelles sont spécifiées à l’aide d’echelle. EPROFILEA propose par défaut un certain nombre d’échelles numériques et textuelles, les enseignants pouvant également créer leurs propres échelles. Ces échelles sont caractérisées par un type (numérique / textuel ordonné / textuel non-ordonné), une borne inférieure bi, une borne supérieure bs et un pas p. Si l’enseignant veut valuer une composante grâce à une note sur 20, il utilisera donc l’échelle « 0..20 » définie par Ech[numérique ; (bi=0, bs=20, p=0,1)]. Les échelles textuelles quant à elles listent l’ensemble E des valeurs possibles. Ainsi l’échelle textuelle ordonnée « maîtrise (3 niveaux) » est définie par Ech[ordonnée ; E=(maîtrisé, partiellement maîtrisé, non maîtrisé)], tandis que l’échelle textuelle non ordonnée « Comportement » est définie par Ech[non-ordonnée ; E=(Attentif, Passif, Bavard)]. Les échelles fournies avec le système et celles créées par les enseignants sont stockées par Bâtisseur dans un fichier XML. 3.4. ÉvaluationCette étape de description de structures de profils d’apprenants a fait l’objet d’évaluations, d’une part concernant l’expressivité de PMDL, et d’autre part concernant la mise en œuvre de ce langage au sein du module Bâtisseur. 3.4.1. Évaluation de l'expressivité de PMDLNous avons réalisé une première évaluation de l'expressivité du langage PMDL en prenant en compte deux aspects : le cadre d’application du langage et l’expressivité de PMDL dans ce cadre. Le cadre d'application du langage PMDL précise les informations que le langage prend en charge ou pas, à l’aide de dix critères auxquels sont associés des degrés de prise en compte. Ainsi, les traces non interprétées sont impossibles à exprimer à travers PMDL, alors que les données personnelles issues d'activités individuelles en termes de connaissances, compétences et conceptions sont parfaitement exprimables. Entre les deux, les huit autres critères (temporalité, temps passé sur les activités, modèle comportemental de l'apprenant, données de pairs, données issues d'activités collaboratives, productions de l'apprenant, modèle du domaine, organisation des éléments du profil entre eux) sont exprimables à des degrés divers par PMDL (Eyssautier-Bavay, 2008). Nous avons ensuite évalué l'expressivité de PMDL au sein de ce cadre d'application pour les vingt-cinq profils de notre étude préalable, profils issus de la littérature, de logiciels du marché et de pratiques des enseignants. Nous avons donc exprimé ces différents profils avec le langage PMDL afin de tester les limites d'expression du langage. Tout d'abord, l'element informations_eleve est présent dans la totalité des profils, puisque tous les profils comportent au minimum une identification de l'élève. liste_composantes est un autre element très répandu : il est présent dans la totalité des profils étudiés issus du marché et des pratiques. Ceci s'explique par l’utilisation qui est faite, dans ces profils, de référentiels de compétences, très utilisés par les enseignants. L'element texte est couramment utilisé dans les pratiques des enseignants pour leurs commentaires sur les élèves et dans certains profils issus de la recherche pour exprimer des conceptions erronées. L'element graphe n'est utilisé que dans certains profils issus de la recherche, la plupart du temps basés sur des réseaux bayésiens. Enfin, l'element liste_repartition est très rarement utilisé (seulement deux des vingt-cinq profils étudiés). Ces deux derniers element étant les plus complexes, les moins intuitifs et de plus absents des référentiels de compétences, il n'est pas étonnant de ne pas les retrouver dans les profils issus de logiciels du marché ou dans les pratiques des enseignants. Les seules informations présentes dans les profils étudiés et ne pouvant pas être entièrement représentées par PMDL se situent en dehors du cadre d'application précédemment défini. Ainsi, les profils représentant des réseaux bayésiens, tels que Hylite+ (Bontcheva, 2001), ne peuvent pas être représentés en intégralité par PMDL : en effet, nous nous intéressons dans ce travail uniquement aux données de l'apprenant, indépendamment du modèle de connaissances qui les a générées. PMDL est donc en mesure de représenter les données de l'apprenant à un instant t, mais ne peut pas gérer les données liées à la modélisation des connaissances du domaine. 3.4.2. Mise à l'essai du module BâtisseurNous avons testé Bâtisseur, le module d’EPROFILEA opérationnalisant PMDL, sur des profils très variés : il permet de créer tous les profils compatibles avec le cadre d’application de PMDL. Bâtisseur a également été mis à l’essai en laboratoire auprès de quatre enseignants avec lesquels nous avons travaillé pendant la phase de conception. Nous l’avons ensuite expérimenté auprès d’une enseignante extérieure au projet. Tout d'abord, les concepts de profil, de composante, de valeur et d'échelle n'ont pas posé de problème de compréhension aux enseignants. La notion de structure de profils a été bien comprise par ceux qui utilisent dans leurs pratiques des référentiels de compétences. Par contre, un enseignant de lycée n'en utilisant pas et ne créant pas non plus de profils a eu besoin de rappels concernant cette notion lors de nos différents entretiens. Ensuite, la métaphore de la construction du mur de briques a été bien acceptée et bien comprise par les enseignants. Elle leur a permis de comprendre l’objectif de ce module et a favorisé une prise en main relativement rapide de l'outil. Les types de briques les plus naturellement utilisées ont été Commentaire et Liste pour lesquelles les enseignants ont trouvé de nombreux exemples. Les types de briques Graphe et Répartition ont été plus difficilement assimilées, les exemples ayant été difficiles à trouver par les enseignants. Ceci est cohérent avec les conclusions de l’évaluation de PMDL : les référentiels de compétences utilisés par les enseignants ne comportent pas d’informations structurées de cette manière, cette représentation leur est donc peu familière. Le module de description de profils a ainsi été bien accueilli par les enseignants auprès desquels il a été testé, ce malgré l’abstraction de la notion de structure de profils manipulée. Notons que l’une des enseignantes ayant testé le logiciel a défini la structure de profils correspondant à son travail en classe de 6ème, cette tâche lui a pris 20 minutes. 4. Intégration de données issues de profils externesL’harmonisation de la structure de profils hétérogènes est rendue possible par la mise en œuvre du langage de description de profils PMDL au sein du module Bâtisseur dans EPROFILEA. Cette étape est ensuite complétée par l’intégration des données issues des différents profils dans la structure de profils harmonisée. Dans EPROFILEA, cette intégration se fait avec le module Tornade pour les profils logiciels et avec le module Prose pour les profils papier-crayon. Ainsi, à partir d’une structure de profils créée dans Bâtisseur, Tornade et Prose permettent d’intégrer les données de profils issus respectivement d’EIAH et de profils papier-crayon. À la fin de cette phase de préparation des profils, l’enseignant dispose d’autant de profils que d’apprenants, les profils respectant la structure de profils définie et donc le formalisme EPROFILEA, ce qui permet de les exploiter dans la seconde partie de l’environnement. L’intégration des données des profils externes à EPROFILEA est le lieu de la transformation du modèle de profils de chacun des EIAH concernés en un modèle conforme à une structure de profils EPROFILEA. Il s’agit donc d’aligner le modèle de profils source (en partie implicite dans le cas de profils non écrits, exprimé par l’organisation des données du profil dans les autres cas), sur le modèle de profils destination (respectant le formalisme EPROFILEA). Pour l’intégration de profils logiciels, l’alignement des modèles se fait explicitement. Il nécessite la connaissance, non seulement du modèle de profils destination (structure de profils respectant le formalisme EPROFILEA), mais également du modèle de profils source (les règles régissant l’organisation des données du profil externe à intégrer) pour chaque logiciel dont seront issus des profils à traiter. Pour l’intégration des profils papier-crayon, cet alignement se fait au contraire implicitement lors de la saisie des profils dans une structure de profils conforme au formalisme EPROFILEA. Dans ce cas, c’est l’interface du module de saisie des profils qui est le lieu de l’alignement des modèles, et c’est l’utilisateur enseignant qui est l’acteur de cet alignement. Dans la suite de cette partie, après un état de l’art concernant l’intégration de données, nous présentons nos approches pour l’intégration de profils externes, ainsi que les modules d’EPROFILEA dédiés à cette tâche : Tornade pour l’intégration de profils logiciels et Prose pour l’intégration de profils papier-crayon. 4.1. Travaux existants concernant l’intégration de donnéesL’intégration de données issues de sources hétérogènes est un problème informatique abordé dans de multiples domaines : recherche d’information, aide à la décision, web sémantique, et de manière plus générale, gestion des connaissances. L’hétérogénéité des données est due aux différents formats et structures de stockage. Ainsi, les données peuvent êtres issues de sources structurées comme des bases de données relationnelles, de sources semi-structurées comme des documents XML ou de sources non structurées comme des documents texte. L’approche des systèmes médiateurs, consiste à définir une interface entre l’agent (humain ou logiciel) effectuant une requête et l’ensemble des sources de données accessibles (Wiederhold, 1992). Le médiateur comporte un schéma global (modèle du domaine d’application et vocabulaire structuré pour l’expression des requêtes), des vues abstraites (décrivant le contenu des différentes sources de données à l’aide du vocabulaire structuré) et des adaptateurs. Lorsqu’une requête est posée au médiateur, celui-ci la traduit en termes de vues et se sert des adaptateurs pour traduire ces vues dans le langage de requêtes accepté par chaque source de données. Un tel système donne l’impression d’interroger un système centralisé contenant des sources homogènes, alors que les sources sont réparties et hétérogènes. La correspondance entre le schéma global et les schémas des sources de données à intégrer peut être fait de deux manières (Hacid et Reynaud, 2004) : en définissant le schéma global en fonction des schémas des sources de données à traiter, ou au contraire les schémas des sources en fonction du schéma global. Eprofilea possède l’équivalent du schéma global par l’intermédiaire du langage PMDL et les sources de données existent déjà puisque nous voulons intégrer des profils d’apprenant issus de logiciels existants. Nous ne pouvons pas définir le schéma global en fonction des schémas des sources de données, puisque celles-ci ne sont pas connues à l’avance. Nous ne pouvons pas non plus agir sur les schémas des sources de données externes sur lesquelles nous n’avons pas d’emprise. Nous ne pouvons donc pas retenir cette approche, mais conservons l’idée qu’il est nécessaire de définir un adaptateur entre le schéma global et chaque source de données. L’approche des entrepôts de données consiste à intégrer et stocker dans un environnement les sources issues de systèmes distribués (Hacid et Reynaud, 2004). Pour cela, un adaptateur est défini pour chaque source de données de manière à en extraire les données et à les transformer pour qu’elles soient compatibles avec le format de l’entrepôt. Des requêtes sur ces données peuvent ensuite être faites via l’entrepôt de données. Eprofilea peut être considéré comme un entrepôt de données, toutefois, nous ne souhaitons pas extraire, convertir et stocker toutes les données contenues dans les profils sources, mais seulement traiter les données nécessaires au moment opportun pour remplir les structures de profils utilisées par les enseignants, ce qui peut se faire en plusieurs fois : soit en fonction des besoins de l’enseignant, soit au fur et à mesure de la création ou mise à jour des profils externes. Un entrepôt de données n’est ainsi pas pleinement adapté à notre situation. Dans le domaine des EIAH des techniques de transformation de modèles ont été proposées pour la spécification de scénarios pédagogiques. Laforcade propose par exemple une traduction entre CPM, le langage qu’il a créé (s’appuyant sur des modèles UML), et des modèles IMS-LD (en XML) (Laforcade, 2005). Cette transformation se réduit conceptuellement à une transformation de modèles UML vers des modèles XML conformes à une certaine DTD. Une première technique consiste à exporter les modèles CPM en modèles XML, puis à transformer un modèle XML vers un autre, en établissant les relations entre les deux DTD correspondantes. Une seconde technique s’appuie sur l’idée qu’un modèle UML outillé peut être interprété comme un système d’information. Ainsi les informations contenues dans les modèles doivent être conservées et synchronisées et un langage permet de faire des requêtes sur ces informations de manière à construire le XML correspondant au modèle UML initial. Pour Eprofilea, cette approche ne peut pas être utilisée, car si nous avons bien en sortie des profils dans un format unique (profils au format XML respectant le langage PMDL), les modèles à convertir sont variés et peuvent être dans différents formats. Ces différentes approches sont connexes à notre démarche, mais n’y sont pas entièrement adaptées, notamment en raison de la généricité de notre approche et du fait que nous ne maîtrisons pas les formats des données à traiter. 4.2. Tornade - intégration de profils logicielsLe module Tornade permet à un enseignant, à l’aide de convertisseurs (des parsers que nous appelons tourbillons), d’intégrer aux structures de profils qu’il a définies dans Bâtisseur, les données de chacun de ses élèves contenues dans des profils logiciels, complétant ainsi le cas échéant les profils déjà en partie renseignés dans Prose. Un tourbillon, noté T(EIAHα, StrProβ), propre au couple formé de l’EIAHα et de la structure de profils EPROFILEA StrProβ est un adaptateur qui permet de transformer tout ou partie du modèle de profils de l’EIAHα en un ensemble de briques contenues dans la structure de profils StrProβ. Un tourbillon est défini pour un EIAHα une fois pour toutes par un expert à l’aide du module Tornade, puis utilisé par un enseignant aussi souvent que nécessaire pour remplir automatiquement les profils EPROFILEA des apprenants avec les données contenues dans leur profil de l’EIAHα selon la structure de profils StrProβ. Dans Tornade, l’intégration de données externes selon une structure conforme au formalisme EPROFILEA se décompose en trois étapes principales (cf. Figure 8) : le prétraitement des données permet de spécifier et uniformiser l’organisation des données dans les profils, la production d’un tourbillon permet d’associer les éléments des profils externes aux éléments d’une structure de profils donnée, et l’exécution d’un tourbillon complète les profils EPROFILEA associés à la structure de profils donnée. Figure 8 : Architecture du module Tornade Le prétraitement des profils des EIAH externes concernés (cf. de la Figure 8) consiste tout d’abord à séparer les fichiers externes de telle manière qu’il y ait autant de fichiers que d’apprenants (), puis à identifier d’une part le type de fichiers () et d’autre part l’organisation des données de l’apprenant dans un fichier (). La séparation des fichiers externes () n’est nécessaire que si l’EIAH externe fournit un ou plusieurs fichiers contenant chacun les données de plusieurs apprenants. Lors de l’identification de l’organisation des données de l’apprenant (), l’expert décrit les données contenues dans les profils, ce qui permet à Tornade de fractionner chaque profil de manière à organiser les données qu’il contient dans un tableau. Cette description de l’organisation des profils du logiciel externe est établie une seule fois par EIAH. La production du tourbillon a pour but de définir l’alignement de modèles en créant le parser (le tourbillon) qui sera capable de faire la conversion entre le modèle des profils externes en entrée et celui des structures de profils EPROFILEA en sortie. Plusieurs briques de cette structure de profils EPROFILEA peuvent concerner l’EIAH externe dont les données doivent être intégrées. Ce sont ces différentes briques que le tourbillon à créer doit savoir remplir dynamiquement. Le traitement d’une brique est générique et s’adapte automatiquement à tous les types de briques conformes au formalisme EPROFILEA opérationnalisant le langage PMDL. Si la structure de profils est une modification d’une structure déjà traitée, Tornade s’appuie sur le premier tourbillon T(EIAHα, StrPro1a) pour créer le second T(EIAHα, StrPro1b). Pour créer un tourbillon, Tornade associe des éléments du profil source, celui de l’EIAH externe, à des éléments de la structure de profils cible, en appliquant d’une part des conversions d’échelles dans le cas où l’échelle des données du profil source ne correspond pas à l’échelle de la structure de profils cibles, et d’autre part des opérations, pour permettre d’associer plusieurs éléments du profil source à un unique élément de la structure de profils cibles. Conversions d’échelles et opérations sur les données du profil externe correspondent à l’étape de transformation des profils du modèle REPro, puisqu’elles transforment les données des profils externes pour les rendre conformes à la nouvelle structure de profils issue de l’étape d’harmonisation du modèle REPro. L’exécution du tourbillon est le lieu de la conversion de modèles. Elle permet de remplir, grâce au parser créé (le tourbillon), la structure de profils avec les données des profils externes sans que l’utilisateur n’intervienne. Tornade remplit la structure de profils dynamiquement pour chaque apprenant, vérifiant qu’il ne manque aucun apprenant et que la création des profils EPROFILEA, ou la complétion dans le cas des profils hybrides, se fait sans erreur. Pour résumer, lors de l’utilisation de Tornade : la phase de prétraitement des données n’est faite qu’une seule fois par EIAH par un enseignant-expert ; la phase de constitution du tourbillon n’est faite qu’une seule fois pour un couple EIAH / structure de profils par un enseignant-expert ; la phase d’exécution du tourbillon sera effectuée par un enseignant chaque fois qu’il voudra créer ou mettre à jour ses profils. 4.2.1. Évaluation du module TornadeNous avons testé le module Tornade avec les fichiers de sortie de 14 EIAH différents non conçus pour fonctionner avec l’environnement EPROFILEA. Les tests ont montré que Tornade permet d’intégrer les données contenues dans les profils correspondants. De plus, Tornade permet de faire des opérations (sommes ou moyennes) sur les données importées des profils externes. Nous devons à présent enrichir le système de nouvelles fonctionnalités pour permettre de traiter plus facilement certains profils, comme la recherche dans un profil de toutes les occurrences d’une compétence donnée ou des opérations plus complexes sur les données importées. Par ailleurs, une enseignante de collège a utilisé avec succès le logiciel pour convertir 12 profils issus d’un EIAH externe dans une structure de profils préalablement créée, ce en 10 minutes. Nous avons également présenté le module Tornade à deux enseignants de primaire. Ils en ont compris le principe, mais ont insisté sur le fait que la majorité des enseignants ne sont pas prêts à utiliser de tels outils. Nous sommes donc conscientes que ce module, pour sa partie constitution de tourbillons, contrairement au reste de l’environnement EPROFILEA, doit être utilisé par ce que nous appelons des enseignants-experts, qui peuvent être les conseillers informatique de l’établissement scolaire ou des enseignants ayant suffisamment de recul sur les logiciels utilisés et un minimum de compétences en informatique. Ces enseignants-experts fabriqueront les tourbillons correspondant aux besoins et aux habitudes de travail des enseignants. Les enseignants pourront ensuite simplement exécuter les tourbillons dans Tornade, sans avoir à les modifier, pour créer ou mettre à jour les profils de leurs élèves. En complément, nous avons effectué un test de la partie constitution de parsers de Tornade avec une enseignante de Français de Collège. Notre objectif était d’évaluer les difficultés rencontrées par un enseignant non-expert pour créer un tourbillon. Nous avons pu constater qu’avec un guidage modéré de la part d’une des expérimentatrices, l’enseignante a pu créer un tourbillon adapté à la structure de profils qu’elle avait préalablement créée et à l’EIAH concerné, ce en 50 minutes. Ces observations sont encourageantes pour l’utilisation de Tornade par des enseignants-experts. 4.3. Prose - intégration de profils papier-crayonLe module Prose permet à un enseignant d’intégrer aux structures de profils qu’il a définies dans Bâtisseur, les données de chacun de ses élèves contenues dans des profils papier-crayon, complétant ainsi le cas échéant les profils déjà en partie renseignés dans Tornade. Ce module ne pose pas de difficulté particulière. Il permet de compléter n’importe quelle structure de profils définie dans Bâtisseur. Nous avons essentiellement travaillé sur les différents modes de saisie et sur l’ergonomie pour faciliter son usage. Ce module prend en entrée une structure de profils que l’enseignant remplit grâce aux informations contenues dans des profils papier dont il dispose, ou directement selon la connaissance qu’il a de ses apprenants, et fournit en sortie des profils conformes au formalisme de l’environnement EPROFILEA. Ces profils peuvent n’être que partiellement remplis avec Prose, soit parce que l’enseignant n’a pas toutes les données pour les remplir, soit parce qu’ils seront ou qu’ils ont été complétés par le module Tornade. Le module Prose dispose de deux modes de navigation. La navigation par élève permet à un enseignant de saisir entièrement le profil d’un apprenant avant de passer au profil de l’apprenant suivant. La navigation par brique permet de remplir une brique donnée pour tous les apprenants avant de passer à la brique suivante. Quel que soit le mode de navigation, un code couleur indique l’état de remplissage des profils d’apprenants d’une part et des briques d’autre part. Prose a été mis à l’essai auprès de plusieurs enseignants de primaire et de collège. Il n’a posé aucune difficulté ni de prise en main, ni d’utilisation. Notons que l’une des enseignantes ayant testé le logiciel a complété sa structure de profils pour deux classes complètes. Lors de la première utilisation, elle a mis 55 minutes pour saisir ses appréciations pour les 23 élèves de sa classe. Lors de la deuxième utilisation, elle a mis 40 minutes pour compléter les profils de sa classe de 22 élèves. 4.4. Des profils hybrides et évolutifsNotons que les profils EPROFILEA sont potentiellement hybrides, c'est-à-dire qu’ils peuvent comporter des informations provenant de sources différentes. Par exemple les données d’une brique peuvent provenir d’un EIAHα et avoir été intégrées grâce au tourbillon T(EIAHα, StrProβ), les données d’une seconde brique peuvent provenir d’un EIAHγ et avoir été intégrées grâce au tourbillon T(EIAHγ, StrProβ), et les données d’une troisième brique peuvent provenir d’une évaluation papier-crayon et avoir été saisies dans Prose. Nous avons par ailleurs identifié les règles permettant de créer, puis de gérer des profils évolutifs, c'est-à-dire que les données d’un profil pourront être mises à jour selon l’avancement d’un apprenant, par exemple au cours d’une année scolaire. Il nous reste à les mettre en place au sein de l’environnement. EPROFILEA offre de plus aux enseignants la possibilité de faire des opérations, que l’on retrouve dans l’étape de transformation de REPro, sur les profils qu’ils ont créés. Ces opérations vont permettre par exemple de filtrer les informations contenues dans les profils, de concaténer des éléments d’un ou plusieurs profils, ou de constituer un profil de groupe à partir de profils individuels. 5. Retour sur le scénario d’usageRevenons maintenant sur le scénario d’usage exposé au début de cet article (cf. section 1.2), pour montrer en quoi les outils proposés par EPROFILEA, s’appuyant sur le modèle REPro et le langage PMDL, permettent une évolution de ce scénario. Figure 9 : Structure de profils « Mathématiques en seconde » de Pauline. Pauline, enseignante de mathématiques en lycée et professeure principale utilise EPROFILEA depuis cette année. Un collègue lui a fourni une structure de profils de mathématiques créée avec Bâtisseur et fondée sur les anciennes évaluations nationales en seconde. Elle y a ajouté une brique pour les données issues du logiciel Mathenpoche et deux briques liées à sa pratique personnelle. La Figure 9 montre à gauche la visualisation globale de cette structure de profils dans Bâtisseur, et à droite un extrait du fichier XML résultant (l’encadré marque les détails de la brique « Fonctions »). Figure 10 : Intégration des données de Pauline avec Prose et Tornade. Elle a pu intégrer grâce à Prose les notes relatives à son référentiel de compétences (cf. partie gauche de la Figure 10) et grâce à Tornade les informations issues du logiciel Mathenpoche (cf. partie droite de la Figure 10). Elle a ainsi un profil par élève pour sa classe de seconde, intégrant ses données papier et les données de Mathenpoche (cf. Figure 11). Figure 11 : Extraits des profils de 2 élèves de la classe de Pauline. Par ailleurs, Pauline crée une seconde structure de profils pour la classe dont elle est professeure principale, dans laquelle elle intègre des briques pour les autres disciplines en fonction des demandes de ses collègues. Ces briques contiennent un bilan de compétences concis pour chaque matière. Chaque enseignant de seconde peut ainsi compléter cette seconde structure de profils avec ses données. En tant que professeure principale, elle réalise dorénavant l'heure de vie de classe en salle informatique, pour permettre aux élèves de travailler sur leur profil et de réaliser des activités d'ordre réflexif. Ainsi, ils peuvent avec son aide visualiser leur profil et poser des objectifs à atteindre pour les prochaines évaluations. Pauline souhaite également par la suite créer des vues adaptées à ses collègues, afin de leur permettre d'avoir une vue globale de l'évolution des élèves. Enfin, elle envisage d’utiliser le module Adapte avec une classe au niveau particulièrement hétérogène pour créer des activités personnalisées en mathématiques afin de s’adapter aux différentes difficultés de huit de ses élèves et à l’avance d’un autre. 6. ConclusionDans les travaux qui font l’objet de cet article, nous nous intéressons à la problématique de la réutilisation de profils d’apprenants très divers, tant par leur contenu que par leur structure. L’hétérogénéité des profils, ainsi que le fait que leur structure n’est pas connue, rend difficile leur réutilisation. Il est donc nécessaire de disposer de modèles génériques et de méthodes permettant de mieux gérer ces profils dans leur diversité pour en permettre une meilleure exploitation par les acteurs concernés. Pour lever ce verrou, nous avons tout d’abord théorisé la chaîne des traitements nécessaires pour aller de la situation d'apprentissage initiale jusqu'à l’exploitation des profils par les différents acteurs, en proposant un modèle générique du processus de gestion de profils, le modèle REPro. Ce processus se décompose en quatre étapes : la constitution des profils, leur harmonisation, leur transformation et enfin leur exploitation. Nous proposons en complément le langage de modélisation de profils PMDL qui permet de décrire la structure des profils lors de l’étape d’harmonisation. Ce langage, indépendant de toute plateforme et donc réutilisable, permet d'exprimer à l’identique, c’est-à-dire sans perte ou corruption d’information, la plupart des profils existants selon un même formalisme, que ces profils soient issus de logiciels ou de pratiques papier-crayon. Ces modèles rendent envisageables le traitement et l’exploitation de profils hétérogènes au sein d'un même environnement informatique. Nous avons mis en œuvre ces résultats dans l’environnement EPROFILEA qui est constitué de deux parties : la préparation des profils et leur exploitation. Nous avons présenté dans cet article la première partie de cet environnement correspondant aux étapes d’harmonisation et de transformation du modèle REPro. Cette partie consiste en la description de la structure des profils (avec Bâtisseur), puis en le remplissage des profils (avec Tornade pour les profils logiciels et/ou avec Prose pour les profils papier-crayon). Bâtisseur permet aux enseignants de décrire la structure des profils qu’ils souhaitent utiliser en s’appuyant sur une opérationnalisation du langage PMDL. Tornade permet à un enseignant-expert de définir les parsers (les tourbillons), qui seront utilisés par les enseignants pour intégrer à une structure de profils EPROFILEA les données issues de profils créés par des EIAH externes à l’environnement, afin de créer des profils conformes à l’environnement. Quant à Prose, il assiste l’enseignant lors de sa saisie de données issues de profils papier-crayon pour compléter les profils EPROFILEA. Cette première partie d’EPROFILEA, assurant la préparation des profils, étant entièrement opérationnelle, elle rend possible la réutilisation de profils très variés, aussi bien papier-crayon que logiciels. Ainsi, des enseignants peuvent intégrer les différents profils qu’ils sont amenés à manipuler, au sein d’un unique environnement. De la même façon, les concepteurs d’EIAH peuvent exporter les profils de leurs systèmes dans un environnement capable de gérer leurs exploitations. Nos travaux devraient ainsi, en permettant la réutilisation de profils existants, puis en proposant d’une part des activités sur les profils, et d’autre part des activités pédagogiques personnalisées adaptées aux besoins des enseignants et aux connaissances des apprenants, favoriser l’intégration des EIAH aux pratiques des enseignants. Nous avons mis cette phase de préparation à l’essai auprès d’enseignants partenaires du projet PERLEA, mais également auprès d’une enseignante extérieure à celui-ci. Nous souhaitons à présent mettre en place des évaluations plus complètes de nos propositions, que ce soit au niveau des modèles ou au niveau des outils développés. Nous prévoyons ainsi de réaliser des expérimentations en situation réelle, avec des enseignants extérieurs au projet. Ces expérimentations feront appel à tous les modules concernés de l’environnement du projet PERLEA, en allant de la définition d’une structure de profils par l’enseignant, à l’utilisation effective des activités personnalisées par les apprenants. Nous attendons de ces expérimentations une validation d'une part de REPro, le modèle de processus de gestion de profils, mis en œuvre dans l’environnement EPROFILEA, d’autre part de l'expressivité du langage PMDL, opérationnalisé dans le module Bâtisseur, ainsi que des différents outils proposés dans l'environnement. Concernant le langage PMDL, nous souhaitons par ailleurs poursuivre son évaluation à travers l'expression d'autres profils existants issus des logiciels du marché ou de la recherche et aller plus loin dans l’étude de son champ d’application, notamment en étudiant la possibilité de l’appliquer plus généralement à la notion de profil d’utilisateur, c’est-à-dire sans se limiter aux profils d’apprenants. À travers ces diverses expérimentations, nous souhaitons mettre l'accent sur la généricité de nos propositions, d'une part au niveau des modèles, et d'autre part au niveau de l'environnement EPROFILEA. Cette première partie de l’environnement, capitale dans le processus de réutilisation de profils existants, ne trouve toutefois sens que dans les exploitations qui seront ensuite faites de ces profils conformes au formalisme de l’environnement. L’une des exploitations auxquelles nous réfléchissons est la visualisation interactive du profil d’un apprenant par les différents acteurs de la situation d’apprentissage, paramétrable par l’enseignant en fonction de l’acteur auquel elle est destinée. L’enseignant pourra ainsi par exemple choisir quelle partie du profil de l’apprenant montrer et à qui, quel mode de visualisation associer à chaque partie visible du profil. D’autres exploitations consisteront à proposer à l’apprenant des activités sur son profil : reformulation, négociation des éléments du profil ou pose d’objectifs par exemple. Enfin, le dernier type d’exploitations proposé par l’environnement EPROFILEA consiste à proposer des activités, papier ou informatisées, adaptées aux compétences et aux difficultés mises en évidence dans les profils d’apprenants, ainsi qu’aux objectifs pédagogiques des enseignants, ceci afin de faire travailler les apprenants sur des points précis de leur profil, soit en remédiation, soit pour acquérir de nouvelles compétences (Lefevre, 2009). BIBLIOGRAPHIEBALACHEFF, N. (1994). Didactique et intelligence artificielle. Recherches en didactique des mathématiques, Vol. 14 n°1-2, p. 9-42. BO_N°22 (2007). Livret Personnel de Compétences. Ministère français de l'éducation nationale de l'enseignement supérieur et de la recherche, Bulletin Officiel (BO), Decret N°2007-860 du 14-5-2007 JO du 15-5-2007, Vol. 22, p. 1277-1278. BONTCHEVA, K. (2001). Tailoring the Content of Dynamically Generated Explanations. User Modelling, Sonthofen, Germany, p. 213-215. BULL, S., DIMITROVA, V., MCCALL, G. (2007). Open Learner Models: Research Questions. Preface of Special Issue of the IJAIED, Vol. 17 n°2, p. 83-87. BULL, S., KAY, J. (2007). Student Models that Invite the Learner In: The SMILI Open Learner Modelling Framework, IJAIED, Vol. 17, p. 89-120. BULL, S., MCEVOY, A. T., REID, E. (2003). Learner Models to Promote Reflection in Combined Desktop PC / Mobile Intelligent Learning Environments. Workshop on Learner Modelling for Reflection, (AIED'2003), Sydney, Australia, p. 199-208. EYSSAUTIER-BAVAY, C. (2004). Le Portfolio en éducation : concept et usages. Colloque Tice Méditérannée, Nice, France. EYSSAUTIER-BAVAY, C. (2008). Modèles, langage et outils pour la réutilisation de profils d'apprenants. Thèse de doctorat en Informatique, Université Joseph Fourier, Grenoble, France. EYSSAUTIER-BAVAY, C., JEAN-DAUBIAS, S., PERNIN, J.-P. (2009). Un modèle de processus de gestion de profils d'apprenants. EIAH'2009. Le Mans, France, p. 69-76. GRANDBASTIEN, M., LABAT, J.-M. (2006). Environnements informatiques pour l'apprentissage humain. Traité IC2, série Cognition et traitement de l'information. HACID, M.-S., REYNAUD, C. (2004). L'intégration de sources de données. Revue I3 (Information Interaction Intelligence), Vol. 4 n°2. IMS-LIP (2001). Spécification finale v1.0 d'IMS-LIP. http://www.imsglobal.org/profiles/lipbest01.html (consulté décembre 2009). IMS (2001). IMS. http://www.imsglobal.org/ (consulté décembre 2009). IMS_RDCEO (2002). Spécification finale v1.0 d'IMS RDCEO. http://www.imsglobal.org/competencies/index.html (consulté décembre 2009). J'ADE (2007). Guide d'installation et d'utilisation, Ministère Français de l'éducation nationale, de l'enseignement supérieur et de la recherche. JEAN-DAUBIAS, S. (2003). Exploitation de profils d'apprenants. EIAH'2003. Strasbourg, France, p. 535-538. JEAN-DAUBIAS, S., EYSSAUTIER-BAVAY, C., LEFEVRE, M. (2009). Uniformisation de la structure de profils d'apprenants issus de sources hétérogènes. EIAH'2009. Le Mans, p. 77-84. KEENOY, K., DE FREITAS, S., LEVENE, M., JONES, A., BRASHER, A., WAYCOTT, J., KASZAS, P., TURCSANYI-SZABO, M., MONTANDON, L. (2004). Personalised trails and learner profiling within e-Learning environments. Kaleïdoscope D22.4.1. LAFORCADE, P. (2005). Approche par transformation de modèles pour la conception d'EIAH. EAIH'2005. Montpellier, France, p. 213-224. LEFEVRE, M. (2009). Processus unifié pour la personnalisation des activités pédagogiques : méta-modèle, modèles et outils. Thèse de doctorat en Informatique, Université Claude Bernard Lyon 1, France. LEFEVRE, M., JEAN-DAUBIAS, S., GUIN, N. (2009). Generation of pencil and paper exercises to personalize learners' work sequences: typology of exercises and meta-architecture for generators. E-Learn 2009. Vancouver, Canada, p. 2843-2848. LEFEVRE, M., JEAN-DAUBIAS, S., GUIN, N. (2009). Personnaliser des séquences de travail à partir de profils d'apprenants. Poster, EIAH'2009. Le Mans, France. LEFEVRE, M., MILLE, A., JEAN-DAUBIAS, S., GUIN, N. (2009). A Meta-Model to Acquire Relevant Knowledge for Interactive Learning Environments Personalization. Adaptive 2009. Athènes, Grèce. M.E.N.EDUCEVAL (2008). Ministère de l'éducation nationale : Evaluations diagnostiques. http://educ-eval.education.fr/evaldiag.htm (consulté décembre 2009). MATHENPOCHE (2002). Mathenpoche. http://mathenpoche.sesamath.net/ (consulté décembre 2009). PAIVA, A., SELF, J., HARTLEY, R. (1995). Externalising Learner Models. AIED'95. Washington, USA, p. 509-516. PAPI (2002). Version de travail de la spécification PAPI. http://edutool.com/papi/ (consulté février 2002). PERNIN, J.-P. (2006). Normes et standards pour la conception, la production et l'exploitation des EIAH. Environnements informatiques pour l'apprentissage humain (Traité IC2, série Cognition et traitement de l'information). RAMANDALAHY, M. T., VIDAL, P., HUET, N., BROISIN, J. (2009). Partage et réutilisation d’un profil ouvert de l’apprenant. EIAH'2009. Le Mans, France, p. 85-92. RUEDA, U., LARRAÑAGA, M., ARRUARTE, A., ELORRIAGA, J. A. (2006). DynMap+: A Concept Mapping Approach to Visualize Group Student Models. Innovative Approaches for Learning and Knowledge Sharing, EC-TEL'06. Crete, Greece, p. 383-397. VASSILEVA, J., MCCALL, G., GREER, J. (2003). Multi-Agent Multi-User Modeling. User Modeling and User-Adapted Interaction, Vol. 13 n°1, p.179-210. VILLANOVA-OLIVER, M. (2002). Adaptabilité dans les systèmes d’information sur le web : Modélisation et mise en œuvre de l’accès progressif. Thèse de doctorat, INP Grenoble. WIEDERHOLD, G. (1992). Mediators in the architecture of future information systems. Computer, Vol. 25 n°3, p.38-49. ZAPATA-RIVERA, J. D., GREER, J. (2004). Interacting with Inspectable Bayesian Student Models. IJAIED, Vol. 14, p.1-37.
| |||||||||
Référence de l'article :Stéphanie Jean-Daubias, Carole Eyssautier-Bavay, Marie Lefevre, Modèles et outils pour rendre possible la réutilisation informatique de profils d’apprenants hétérogènes, Revue STICEF, Volume 16, 2009, ISSN : 1764-7223, mis en ligne le 15/03/2010, http://sticef.org |