de l´Information et
de la Communication pour
l´Éducation et la Formation
version à télécharger (pdf)
Volume 16, 2009
Rubrique
|
Contact : infos@sticef.org |
L’accès libre aux revues, articles et données de recherche : retour sur la première conférence de l’OASPA
1. Organisation, esprit et institutionsLa première conférence européenne sur l’accès libre aux revues scientifiques (COASPA, 2009), organisée par l’OASPA (Open Access Scholarly Publishing Association, cf. section 1.1) a eu lieu à Lund (Suède) du 14 au 16 septembre 2009. Elle a réuni environ 130 personnes (chercheurs, représentants du monde de l’édition et des bibliothèques) de 28 pays. L’ATIEF (pour sa revue STICEF) était la seule organisation française représentée à cette conférence. Le comité d’organisation (de Lund) est aussi l’équipe qui gère le DOAJ (Directory of Open Access Journals, cf. section 1.2). Cette conférence a permis aux participants de faire le point sur les questions de l’accès libre aux publications scientifiques. Quel modèle économique satisferait les différents acteurs ? Quelles normes permettraient de s’assurer de la qualité des publications en accès libre ? Quels services doit-on organiser pour faciliter l’accès d’une part et assurer la qualité d’autre part ? Quels sont les outils plébiscités par la communauté pour soutenir le processus de publication d’une revue en ligne et en libre accès ? Quelles sont les initiatives existantes et viables ? Comment peut-on repérer les bonnes pratiques dans le domaine de l’édition de revues scientifiques en accès libre ? Les deux mondes en présence (celui des éditeurs privés et le monde académique) n’ont a priori pas le même rapport à l’édition scientifique : les uns tentent d’en dégager le profit maximum tandis que les autres recherchent la diffusion la plus large possible. Toutefois, pour des raisons de compétitivité économique ou de reconnaissance scientifique, tous ont intérêt à fournir la meilleure qualité possible. L’esprit de l’OASPA et donc de cette conférence était de réunir ces deux mondes pour chercher ensemble des modèles économique et de diffusion qui puissent satisfaire les deux parties et qui, de surcroît, offriraient aux pays en voie de développement l’accès gratuit aux publications scientifiques. 1.1. OASPA : Association de l'édition scientifique en libre accèsL’association OASPA (Open Access Scholarly Publishers Association), créée il y a un an, ne fonctionne pour l’instant que sur le bénévolat de ses élus mais compte déjà 52 membres, dont 24 membres associés, et représente collectivement environs 600 revues. Elle a pour principal objectif de rassembler les acteurs de la publication afin de : - Partager les bonnes pratiques, améliorer l’accès à l’information scientifique, aider les communautés scientifiques à publier leurs propres journaux en accès libre ; - Promouvoir le libre accès tout en collaborant avec les éditeurs privés. Notons que SPARC publication et Springer sont des sponsors de l’OASPA ; - Peser sur les standards techniques du libre accès, améliorer la transparence des critères de mesure de la qualité et de la notoriété des revues ou des articles. Les lecteurs intéressés trouveront sur le site de cette association (OASPA, 2010) : la composition de son conseil d’administration, la liste de ses membres, ainsi que des ressources fondamentales sur la publication en libre accès (sites, livres, déclarations de Berlin et de Budapest, etc.) 1.2. DOAJ : Répertoire des revues en accès libreLe DOAJ (Directory of Open Access Journals) indexe 4667 revues scientifiques dont 1825 qui permettent une recherche au niveau de leurs articles (DOAJ, 2010). Au 4 février 2010, ce répertoire permettait un accès libre à 349 869 articles de revues.
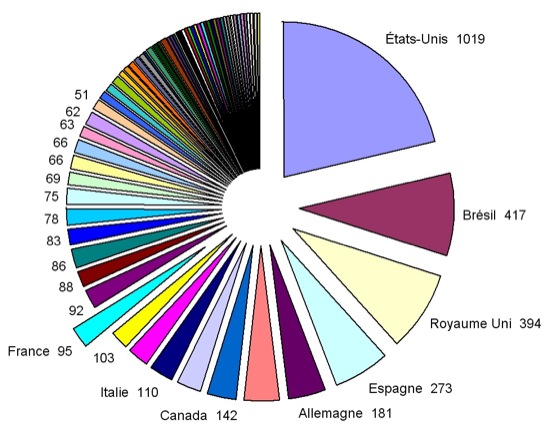
Répartition des 4667 revues sur les 107 pays d'origine Les gestionnaires du DOAJ, basés à Lund, souhaitent maintenir une diversité linguistique à travers la liste de ses revues. Certaines d’entre-elles publient des articles en différentes langues. Sur les 95 revues répertoriées en France dans le DOAJ, 83 publient des articles en français, 64 en anglais, 14 en espagnol, 4 en allemand, 4 en italien, 4 en portugais et même une en turc, russe, catalan ou occitan. Parmi les critères permettant à une revue d’être référencée par le DOAJ, on retiendra : l’accès gratuit en ligne des textes complets (sans période d’embargo), un processus permettant d’assurer la qualité des articles publiés (ex : relecture par des pairs) ainsi que la capacité des éditeurs à fournir toutes les métadonnées requises. Notons que STICEF figure parmi les 1825 revues offrant toutes les métadonnées utiles à la recherche au niveau de ses articles, et ce depuis 2003 (retrouvez-la à l’URL suivante : http://www.doaj.org/doaj?func=findJournals&hybrid=&query=STICEF). 2. Initiatives d’intérêt pour la communauté2.1. Public Knowledge ProjectLe “Public Knowledge Project” (PKP, 2010), est un projet nord américain fondé en 1998, et dirigé par John Willinsky (Faculté d’éducation de l’université de Colombie Britannique). Il a pour objectif général d’améliorer la qualité de la recherche académique et publique. Il est financé par divers sponsors en plus des quatre partenaires fondateurs : - La faculté d’éducation de l’université de Colombie Britannique (Canada) ; - La bibliothèque de l’université Simon Fraser (Canada) ; - Le centre canadien d’études en publication à l’université Simon Fraser ; - La faculté d’éducation de l’université de Stanford (Etats-Unis). Ce projet est connu en particulier pour avoir développé les logiciels libres Open Journal System (cf. section 2.1.1), Open Conference System (permettant l’organisation d’une conférence : site web, soumission, relecture...) et Open Archives Harvester (un moissonneur de métadonnées compatible avec les archives ouvertes). 2.1.1. Open Journal System : le système de référenceOpen Journal System (OJS, 2010) est la référence des outils utilisés par les différents éditeurs indépendants de revues scientifiques. C’est un logiciel libre issu du projet PKP (Public Knowledge Project). Ce système gère tout le processus de suivi depuis la soumission, les relectures, les relances aux relecteurs, etc., jusqu’à la publication (en libre accès). Certaines institutions (par exemple, Igitur/Utrecht) ont même abandonné leur propre outil (développé sur mesure durant plusieurs années) pour adopter OJS ! Il est utilisé par plus de 2700 revues publiées en différentes langues. (Edgar et Willinsky, 2010) fournissent une étude détaillée portant sur un questionnaire en ligne rempli en mars 2009 par 998 rédacteurs en chefs utilisant OJS (sur les 2748 invités). Si 93% de ces revues donnent accès à leurs numéros postérieurs à 1990, l’une d’entre-elles remonte jusqu’à 1872 pour le numéro accessible le plus ancien ! 2.2. CrossRef, liens et persistance (Bilder, 2009)CrossRef est l’opérateur (technique) de liaisons entre les articles scientifiques publiés en ligne en version électronique. Il travaille pour le compte des éditeurs de revues regroupées depuis janvier 2000 au sein de l’association PILA (Publishers International Linking Association). CrossRef est né en juin 2000 comme le premier service collaboratif de liaison des références DOI (Digital Object Identifier). Le premier objectif était de permettre aux lecteurs d’un article en ligne chez un éditeur, citant un article en ligne chez un autre éditeur, d’accéder en un clic à l’article cité. En ce sens, CrossRef agit un peu comme un multiplexeur entre les articles (en ligne) et au-delà des frontières entre les éditeurs (CrossReff, 2010). Bien qu’il ne gère pas l’archivage des documents eux-mêmes, il assure la consistance des métadonnées associées et la persistance du lien entre le DOI et sa localisation physique. Aujourd’hui, Geoff Bilder (responsable et inventeur de service chez CrossRef) montre l’importance d’identifier de façon persistante et non ambiguë : non seulement les articles scientifiques, mais aussi les données de recherche, les auteurs, les différents contributeurs (techniciens, développeurs, relecteurs, éditeurs, co-auteurs, etc.) des dépôts (numériques) de nature scientifique. Dans son exposé très pédagogique et imagé, G. Bilder pointe l’importance sociale (plus que technique) de cette désambiguïsation (Bilder, 2009). Il s’intéresse aussi aux types de relations entre les différents contributeurs, entre les dépôts et ces contributeurs (paternité ou responsabilité scientifique, etc.). D’autres services de CrossRef travaillent sur la détection de plagiat dans le processus de soumission ou sur la citation automatique dans le processus d’écriture. 2.3. Nano publications (Velterop, 2009)Considérant le déluge d’articles scientifiques dans certains domaines (en médecine : il paraîtrait plus d’un article par minute !) Jan Velterop montre qu’il n’est plus possible de connaître toute la littérature d’un domaine et parfois même d’un seul sujet (le cancer par exemple). De nouvelles formes de publications, plus concentrées, permettant d’accéder à l’essence de la connaissance émergente deviennent nécessaires si l’on souhaite embrasser un domaine de connaissance. C’est ainsi qu’il suggère de passer du terme/mot au concept/sens, puis des concepts aux contributions (théorèmes, résultats, affirmations, découvertes, etc.). Une contribution serait représentée par un triplet de concepts, annoté par des attributs permettant de préciser les relations entre les 3 concepts, mais aussi la provenance, les auteurs, la date de publication, la crédibilité, etc. Le tout pourrait être représenté dans un langage à balises tel que RDF (Resource Description Framework) pour constituer un petit réseau (ontologie) que l’auteur appelle nano publication. C’est seulement l’essence de l’article représentée sous cette forme que l’on devrait mettre en accès libre pour tous les articles et non pas nécessairement le texte complet des articles : ce qui pourrait convenir aux éditeurs privés autant qu’aux éditeurs publics. Ainsi disponibles, ces nano publications pourraient être traitées de façon automatisée pour interconnecter ces minis ontologies et aider les chercheurs (avec ces outils) à mieux embrasser leur champ de recherche et réaliser certaines connexions que le flot actuel les empêche de faire. Toutefois, ces travaux ne semblent pas définir sérieusement la distance entre deux concepts ni les critères de choix entre produire un nouveau concept ou modifier les attributs d’un concept existant. 2.4. SCOAP3 : le consortium des physiciens (Mele, 2009)On trouve dans les missions du CERN (Organisation Européenne pour la Recherche Nucléaire ; CERN, 2010) la coordination des états dans la recherche scientifique sur le nucléaire « ... et les résultats de ses travaux expérimentaux et théoriques sont publiés ou de toute autre façon rendus généralement accessibles. » La tradition des scientifiques dans le domaine de la physique de haute énergie, depuis les années 1960, était de partager les publications « sous presse » ou "preprints". En effet, la lenteur du processus de publication dans les revues scientifiques était incompatible avec le rythme accéléré des découvertes du domaine. C’est d’ailleurs ce besoin qui a motivé Tim Berners-Lee en 1989, aidé de Robert Cailliau en 1990 pour définir le World Wide Web. On ne peut donc pas s’étonner que cette même organisation vienne aujourd’hui nous faire des propositions sur un modèle de publication en accès libre ! Une étude de 2007, menée auprès de 2000 chercheurs en physique nucléaire, a montré qu’ils effectuent 0,1% de leurs recherches d’articles sur les bases de données commerciales des éditeurs privés, 50% dans la plateforme de la communauté (Spires), 40% dans les archives ouvertes et 8% passent par Google pour arriver dans les 2 précédentes. Dans (Gentil-Beccot et al., 2009), les auteurs (dont Salvatore Mele) montrent que 97% des articles de cette communauté étaient disponibles gratuitement sous forme de preprints. Ils montrent aussi que les articles disponibles en preprints sont cités 5 fois plus que les autres, mais surtout que le pic de citation des preprints a lieu avant l’échéance de la parution en revue. La proposition faite lors de cette conférence par Salvatore Mele portait plus sur le modèle économique envisagé par SCOAP3 (Sponsoring Consortium for Open Access Publishing in Particle Physics). Le service essentiel apporté par les revues étant la relecture par les pairs (dont le coût moyen est évalué à 2000€ par article), le consortium paierait les 10 millions d’euros annuels aux différentes revues. Le financement serait apporté par chaque pays au prorata du service de relecture demandé (nombre de soumissions). En contrepartie, le consortium reverserait les publications (plein texte) aux archives ouvertes sans que cela coûte plus à la communauté scientifique (du domaine). Le consortium a déjà réuni 65% du budget requis en impliquant 22 pays. Nous pouvons leur souhaiter bonne chance dans l’obtention de la masse critique qui leur permettra de rendre 100% des publications de leur domaine libres et accessibles par tous. Notons qu’au 18 février 2010, ils ont atteint 68,2% du budget et le Portugal est le 23e pays à entrer dans ce consortium (SCOAP3, 2010). 3. Table ronde : « Open Data » : données libresDes trois panélistes, deux étaient américains (David Salomon et John Willinsky) et un anglais (Iain Hrynaszkiewicz). Le point de départ de la discussion est d’abord l’annonce par D. Salomon de la publication récente d’un numéro spécial de la revue Nature (Nature, 2009) qui souligne que la communauté scientifique est a priori favorable au partage des données de recherche, mais que les serveurs de données restent vides. Iain Hrynaszkiewicz nous montre ensuite les nombreux avantages et possibilités qu’offre le partage des données de recherche : test d’hypothèses secondaires ; accumulation et agrégation des résultats homogènes à travers différentes analyses ; vérification indépendante des résultats ; calibrage d’outils ou de futures études sur la base de données similaires antérieures ; apports des données dans l’enseignement ; aide à l’identification et à la réduction des erreurs et des fraudes scientifiques ; augmentation des citations et de la dissémination des résultats ; gain de productivité en évitant la duplication d’expérience pour la duplication d’analyses ; agrégation d’analyses complémentaires sur les mêmes données ; apport aux pays en voie de développement (n’ayant pas les moyens de conduire les expérimentations). Malgré ces promesses, et comme le constate Bryn Nelson dans (Nelson, 2009), il reste de nombreux freins au partage des données de recherche, ayant deux origines principales : la résistance des chercheurs (coût/effort de préparation des données, usage commercial, perte des droits intellectuels, risques de mauvaise interprétation, ...) et les règles de protection des sujets humains (confidentialité, risque de stigmatisation) sans sous-estimer les possibilités de croisement de différentes bases de données qui permettraient d’identifier une personne qui ne peut l’être dans aucune des bases prises seule (Sweeney, 2002). John Willinsky, à la fin de cette table ronde, suggère 3 pistes : 1) développer et renforcer les codes de bonne conduite des chercheurs (dépositaires et usagers), des financeurs et des revues ; 2) mettre au point des standards et des logiciels pour aider les chercheurs à préparer leurs données au partage ; 3) développer des procédures spécifiques pour assurer la protection des sujets humains quand les données sont partagées. Il cite rapidement le projet "DataVerse Network" (King, 2007) qui permet d’héberger les données. Iain Hrynaszkiewicz considére que les logiciels et les infrastructures pour le partage des données peuvent exister indépendamment des éditeurs. Compte tenu des moyens technologiques actuels, John Willinsky suggère que les chercheurs s’interdisent les formules comme « l’espace de publication étant limité, nous ne pouvons malheureusement l’illustrer sur un exemple... » et utilisent désormais des dépôt de données comme "Spaces of exhibition". L’évaluation par des pairs doit s’étendre à d’autres formes de publication que les articles de recherche pour inciter les chercheurs à utiliser ces nouveaux espaces de partage et de communication. La question de l’anonymat des personnes ayant participé à une expérimentation est illustrée sur des recherches en médecine, où les règles de bonne conduite stipulent qu’aucune information directe sur l’identité (nom, initiales, adresses, informations de contact : téléphone fax, courriel, identifiant unique, immatriculation de véhicules, identifiants médicaux, données biométriques, image faciale, enregistrement audio, noms des proches, dates personnelles) ne peut figurer dans un dépôt public. Tandis que le nombre d’informations indirectes (médecin, hôpital, sexe, maladie ou traitement rare, information sensible, lieu de naissance, données sociométriques (emploi, salaire, niveau d’études), composition de la famille, mesures anthropométriques, grossesses, ethnie, petits dénominateurs (population<100), effectifs<3, âge ou année de naissance, transcriptions mot pour mot) serait limité à trois. Mais sur ce thème, J. Willinsky propose plus de souplesse car dans certaines études en sciences sociales, les attributs de la personnalité sont indispensables, il arrive même que les participants (tuteurs, enseignants) souhaitent être explicitement référencés comme acteurs d’une expérimentation. Plus généralement, il suggère que soit mesuré le quotient bénéfice/risque avant d’autoriser ou d’interdire la publication des ensembles de données. L’intervention (dans le public) la plus intéressante fût celle de Martin Rasmussen qui nous a relaté les pratiques du journal "Earth System Science Data". Cette revue ne peut accepter un article de recherche que si un papier court (signé de tous les contributeurs du dépôt de données) associé aux données déposées a été préalablement accepté. Ce processus offre deux avantages : les données sont disponibles dès la parution de l’article de recherche, et tous les contributeurs de l’ensemble de données obtiennent une reconnaissance par le fait qu’ils sont auteurs du papier court. Ce papier court a pour objet d’expliquer l’organisation des données dans le dépôt, d’éclairer la communauté sur les conditions de recueil et le contexte de l’expérience, et de fournir toute information permettant une meilleure utilisation des données et surtout une meilleure interprétation des analyses (secondaires) qui pourraient en découler. 4. ConclusionsDans son allocution introductive, Paul Peters (Peters, 2009) avait montré que la publication en accès libre a fait de grandes avancées depuis 2005. Ainsi, le nombre de revues accessibles gratuitement en ligne a considérablement augmenté. Elles ont donné accès à 90000 articles en 2008 contre 50000 en 2005. Il ajoute que 5 revues (dont 4 issues de PloS1) en accès libre sont classées au premier rang des revues scientifiques les plus prestigieuses. Les présentations et discussions de cette conférence ont permis de saisir les enjeux des grandes mutations qui agitent actuellement le monde de l’édition scientifique. Bien au-delà des clivages entre organismes publics et sociétés privées, on voit comment et combien l’accès libre aux publications bouleverse les modes d’évaluation mais aussi les modèles économiques pour les différents acteurs. À l’accès en ligne des articles, peuvent s’ajouter de nombreux services (CrossRef, Nano publications, Dépôts de données de recherche, etc.) capables de modifier les modes de représentation et d’usage de nos publications. Si les technologies du web n’ont pas encore été pleinement exploitées dans le monde de l’édition scientifique, c’est sans doute parce que les acteurs n’avaient pas encore su/voulu partager leurs ressources pour démultiplier les effets de citations et de référencement par exemple. Mais les initiatives (OAI, DOAJ, OASPA, SCOAP3...), qui rassemblent la communauté scientifique pour un accès libre aux publications, ont aujourd’hui un impact tel que l’équilibre des forces dans le monde de l’édition est lui-même bouleversé. Alors que les revues d’autrefois (indétrônables), faisaient payer aux lecteurs le prix de leur prestige, les modèles émergeants permettraient une certaine redistribution des cartes (argent et pouvoir) en privilégiant la transparence des informations concernant les processus de relecture. Le contre-pouvoir instauré par ces projets et amplifié par le succès qu’ils remportent auprès de la communauté scientifique (premier acteur de la production des savoirs savants) oblige, d’une certaine façon, tous les acteurs à se réunir pour collaborer à l’élaboration des nouvelles règles. L’OASPA, qui prétend rassembler l’ensemble de ces acteurs pour peser sur les nouvelles règles, compte bien donner au libre accès ses lettres de noblesse. Enfin, si les modèles de diffusion des savoirs savants sont aujourd’hui profondément remis en question, c’est aussi parce que l’article n’est plus la seule forme de contribution scientifique reconnue : les données de recherche, exposées dans des cahiers de laboratoire ou consignées dans des corpus d’expérimentation, liés aux résultats décrits dans les publications, deviennent partageables, accessibles et donc réinterrogeables par d’autres pour questionner les résultats plus en profondeur. 5. RemerciementsJe tiens à remercier l’ATIEF et le projet ANR Mulce (http://mulce.org) pour m’avoir permis d’assister à cette conférence. BIBLIOGRAPHIEBILDER G.W. (2009). Video presentation of CrossRef by its boss: Geoff W. Bilder. In the 1st Conference on Open Access Scholarly Publishing. Lund, Sweden, 14-16 September 2009. http://river-valley.tv/tag/geoff-bilder/ (consulté le 4 mars 2010). CERN (2010). Organisation Européenne pour la Recherche Nucléaire. http://public.web.cern.ch/public/Welcome-fr.html (consulté le 4 mars 2010). COASPA (2009). 1st Conference on Open Access Scholarly Publishing. Lund, Suède, 14-16 sept. 2009. http://www.oaspa.org/coasp1/ (consulté le 4 févier 2010). CrossReff (2010). http://crossref.org (consulté le 4 mars 2010). DOAJ (2010). Directory of Open Access Journals. http://www.doaj.org/ (consulté le 4 févier 2010). OASPA (2010). Open Access Scholarly Publishing Association. http://www.oaspa.org/ (consulté le 4 févier 2010). OJS (2010). Open Journal System. Stanford University. http://pkp.sfu.ca/?q=ojs (consulté le 2 mars 2010). Edgar, B. D., Willinsky J. (2010). A Survey of the Scholarly Journals Using Open Journal Systems. In journal Scholarly and Research Communication, in press. http://pkp.sfu.ca/files/OJS Journal Survey.pdf (consulté le 2 mars 2010). GENTIL-BECCOT, A., MELE, S., BROOKS, T. (2009). Citing and Reading Behaviours in High-Energy Physics. How a Community Stopped Worrying about Journals and Learned to Love Repositories. Preprint http://arxiv.org/abs/0906.5418v2 (Consulté le 4 mars 2010) à paraître dans Scientometrics. KING, G. (2007). An Introduction to the Dataverse Network as an Infrastructure for Data Sharing. In: Socialogical Methods & Research, vol. 36(2), pp. 173-199. DOI : 10.1177 / 0049124107306660. http://gking.harvard.edu/files/dvn.pdf (last visited 9/03/2010). MELE, S. (2009). SCOAP3 : Sponsoring Consortium for Open Access Publishing in Particle Physics. In the first Conference on Open Access Scholarly Publishing. Lund, Sweden, 14-16 Sept. 2009. http://river-valley.tv/media/conferences/oaspa2009/0301-Salvatore_Mele/ (Consulté le 4 mars 2010). Nature (2009). Data sharing. Special issue of Nature News. Nature, Vol.461, no.7261, sept. 2009. http://www.nature.com/news/specials/datasharing/index.html (Last view 02/03/2010). NELSON, B. (2009). Empty Archives. In special issue of Nature News. Nature, Vol.461, no.7261, pp 160-163, sept. 2009 : doi:10.1038/461160a. PKP (2010). Public Knowledge Project. John Willinsky. http://pkp.sfu.ca/about (consulté le 2 mars 2010). SCOAP3 (2010). Sponsoring Consortium for Open Access Publishing in Particle Physics. http://www.scoap3.org (consulté le 4 mars 2010). SWEENEY, L. (2002). k-anonymity: a model for protecting privacy, International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, v.10 n.5, p.557-570, October 2002 doi:10.1142/S0218488502001648. VELTEROP, J. (2009). Nano Publications. Video of the presentation in the first Conference on Open Access Scholarly Publishing. Lund, Sweden, 14-16 September 2009. (Consulté le 4 mars 2010). http://river-valley.tv/media/conferences/oaspa2009/0201-Jan_Velterop/ 1 Public Library of Science
| ||||
Référence de l'article :Christophe REFFAY (UMR STEF, INRP - ENS Cachan, Universud), , Revue STICEF, Volume 16, 2009, ISSN : 1764-7223, Rubrique, mis en ligne le 15/03/2010, http://sticef.org |