de l´Information et
de la Communication pour
l´Éducation et la Formation
Article de recherche
|
Contact : infos@sticef.org |
Construction d'une base de connaissances et d’une banque de ressources pour le domaine du téléapprentissage
1. IntroductionDepuis quelques années, la prise de conscience de la nécessité de gérer les connaissances (knowledge management) amène un nombre croissant d’organisations à formaliser les connaissances et surtout à soutenir leur utilisation, notamment par une réingénierie des processus de travail et de formation et par l’utilisation des technologies de l’Internet [DavenportPrusak98], [Sveiby01]. Par ailleurs, un mouvement international a pris forme pour l’élaboration de standards permettant de construire et d’interopérer des répertoires de ressources ou d’objets d’apprentissage (Learning object repositories) [Wiley02]. Ce mouvement a donné naissance à plusieurs initiatives d’envergure auxquelles participent des organisations telles que le IMS Global Learning Consortium, IEEE-LTSC (LOM), Dublin Core et ADL (SCORM). Ces deux démarches convergent et s’intègrent dans une autre entreprise visant à construire le "Web sémantique" [BernersLee01], [Nillson01]. Cet article a pour but d’analyser ces convergences en prenant comme exemple la construction d’une base de connaissances et de ressources en téléapprentissage. La gestion des connaissances est un processus qui englobe la gestion informatisée des documents ou des données, mais qui la dépasse. Elle vise d’abord le partage des connaissances disponibles dans une organisation et l’accroissement des compétences des personnes qui y travaillent, plutôt qu’une simple mise en disponibilité d’informations ou de documents. De plus, la gestion des connaissances intègre le traitement de connaissances de plus haut niveau que les données et les informations factuelles ou conceptuelles. Elle s’intéresse aux principes, aux modèles, aux théories, aux processus ou aux méthodes, notamment aux connaissances tacites des experts, ainsi qu’aux opérations et aux principes de décision qui en découlent. Ce nouveau phénomène met beaucoup plus d’emphase que par le passé sur les connaissances et les compétences des personnes oeuvrant dans l’organisation car, contrairement aux informations pouvant être rendues accessibles dans des bases de données ou de documents, les connaissances de plus haut niveau nécessitent un processus d’acquisition et une maintenance qui passent par la formation continue des personnes. L’ingénierie pédagogique joue ici un rôle central. On peut la définir comme une méthode grâce à laquelle des concepteurs peuvent construire et maintenir un système d’apprentissage, en s’appuyant sur deux processus principaux :
La modélisation des connaissances d’un domaine est l’élément qui relie ces deux processus. Des modèles de connaissances sont produits par l’ingénierie des connaissances et servent d’intrant à l’acquisition des connaissances et à la formation. Elle permet aussi de préciser des cas d’utilisation décrivant les acteurs, les opérations qu’ils régissent et les ressources qu’ils utilisent ou produisent au cours du traitement lorsqu’ils mettent à contribution des connaissances d’un domaine, ce qui permet en retour, de valider et d’étendre constamment le modèle ou l’ontologie d’un domaine. La gestion des ressources (ou des objets d’apprentissage) peut être définie comme un processus multiacteurs dans lequel des personnes jouant le rôle d’éditeurs repèrent des ressources intéressantes et les décrivent par des fiches de métadonnées, dont l’ensemble constitue un référentiel de ressources (Learning objects repository). À l’aide de ce référentiel, des utilisateurs recherchent des ressources, y accèdent, les utilisent et donnent une rétroaction sur l’usage de la ressource à l’intention des autres acteurs, dans le but d’améliorer le référentiel. Les ressources peuvent être de taille et de nature très différentes. Certaines ont un caractère pédagogique et portent des informations servant explicitement à l’acquisition et à la construction de connaissances et des compétences. Elles se présentent sous forme de documents (ou matériels) de divers types: textes, présentations audiovisuelles, didacticiels, multimédias, sites Web. D’autres ressources permettent de traiter ces informations de diverses façons. Ce sont les outils informatisés, les moyens de communication et les services offerts par des personnes sur les réseaux. Enfin, le regroupement des deux types de ressources dans des événements d’apprentissage, des cours ou des programmes de formation fournit une autre catégorie de ressources. Cet article vise à définir les bases d’un développement intégré de deux projets en cours au Centre interuniversitaire de recherche sur le téléapprentissage (CIRTA). Le premier a pour but de créer un référentiel de ressources en téléapprentissage permettant aux intervenants et aux chercheurs dans ce domaine de référencer les ressources à l’aide de spécifications standards, dans le but de les intégrer par la suite dans des environnements de téléapprentissage, à des fins de recherche et d’enseignement. Le second a pour objectifs de créer une base de connaissances en téléapprentissage par le développement d’une ontologie du domaine et de regrouper l’expertise sur le téléapprentissage dans des ressources référencées en fonction de cette ontologie. Par ailleurs, une ontologie de tâche permet de définir différents cas ou scénarios d’utilisation de ces ressources, identifiées grâce à leur référencement en fonction de l’ontologie du domaine. Les trois sections suivantes visent respectivement à définir des cas d’utilisation de la base de connaissances en téléapprentissage et du référentiel des ressources qui lui est associé, à présenter une première ontologie du téléapprentissage, et à préciser de quelle façon cette ontologie pourra contribuer à gérer les ressources de téléapprentissage en fonction de divers cas d’utilisation. La section 5 présente un exemple de démarche soutenue par un environnement basé sur l’intégration des ressources en fonction des cas d’utilisation. Finalement, la section 6 généralise cette démarche dans le but de jeter les bases d’une métaméthode servant au développement intégré de bases de connaissances et de ressources dans divers domaines de connaissances. 2. Cas d’utilisation et ontologie de la tâchePlaçons-nous d’abord du point de vue des futurs usagers d’une base de connaissances en téléapprentissage. Certains usagers peuvent vouloir faire une recension d’écrits sur un sujet donné dans le domaine, d’autres construire une formation des maîtres sur le téléapprentissage, d’autres encore, conseiller des étudiants gradués dans leurs travaux de recherche sur le téléapprentissage, d’autres enfin, utiliser des méthodes et des outils de téléapprentissage pour construire un cours de littérature ou de physique, etc. Le tableau 1 énumère certains des cas d’utilisation1 identifiés lors d’une analyse préliminaire des objectifs et des usages possibles d’une base de connaissances en téléapprentissage. On y distingue trois grandes catégories d’utilisateurs : les concepteurs d’environnements de téléapprentissage, les formateurs ou professeurs oeuvrant dans un contexte de téléapprentissage et les chercheurs ou étudiants chercheurs dans le domaine du téléapprentissage. Les premiers recherchent surtout diverses formes d’assistance méthodologique, pédagogique ou technique, notamment des documents, des outils et des plateformes pour l’élaboration d’environnements de téléapprentissage. Les seconds désirent obtenir des informations sur les différents rôles qu’ils sont appelés à jouer dans un environnement de téléapprentissage, ainsi que des pratiques exemplaires et des conseils pour exercer ces rôles. Finalement, les chercheurs et les étudiants-chercheurs voudront principalement obtenir un accès à des résultats de recherche sur les différentes dimensions du téléapprentissage. Pour chacune des grandes catégories d’utilisateurs, le tableau 1 présente certains processus (cas d’utilisation) dans lesquels ces utilisateurs peuvent vouloir s’engager. Dans tous les cas d’utilisation, l’usager de la base de connaissance devra pouvoir repérer des ressources, les obtenir et les consulter et possiblement les commenter et les utiliser pour en produire de nouvelles. Pour ce faire, il utilisera divers outils de traitement de l’information et de communication ou des services de facilitateurs ou d’experts.
Tableau 1 : Un ensemble de cas d’utilisation en téléapprentissage (TA)
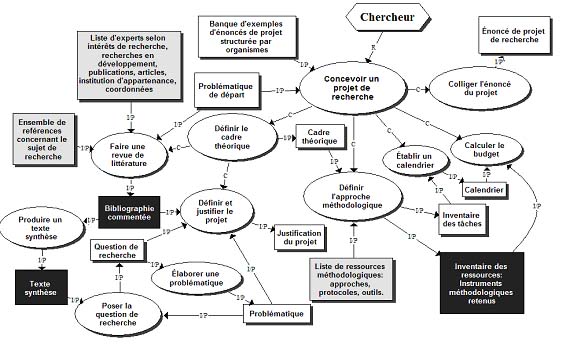
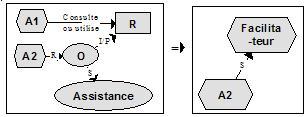
Figure 1 : Un exemple de modèle d’un cas d’utilisation : la conception d’un projet de recherche Les cas d’utilisation les plus fréquents ou jugés les plus importants pourront faire l’objet d’un modèle de processus mettant en évidence les acteurs, les principales opérations qu’ils régissent, ainsi que les intrants et les produits de ces opérations. La figure 1 présente un tel modèle graphique pour le cas d’utilisation concernant la préparation de projets sur le téléapprentissage par une équipe de recherche (tableau 1, cas 3.4). L’intérêt d’un modèle2 de processus est de faire apparaître, dans leur contexte d’utilisation, les ressources requises (identifiées par des rectangles gris dans la figure 1) pour les principales opérations (représentées par des ovales) ainsi que celles produites par ces opérations (rectangles noirs). Les ressources, intrants à une opération ou produites par une opération, peuvent être repérées et associées à l’opération par l’usager, où elles pourront être intégrées à la base de ressources par l’usager et réutilisées par d’autres usagers par la suite. Un tel modèle facilite également la définition et le choix des outils de traitement de l’information ou de communication requis pour soutenir les diverses opérations identifiées par le modèle, par exemple un outil de production d’une bibliographie commentée ou un outil de communication pour échanger avec des experts répertoriés dans la base de connaissances. Un modèle comme celui de la figure 1 est une instanciation d’une ontologie de tâche particulière [GuarinoGiaretta95], [ChandrasekaranAl98], décrite dans [PaquetteRosca03] sous le terme de "modèle de diffusion". Tel qu’indiqué par les symboles graphiques utilisés à la figure 1, cette ontologie de tâche est définie par :
Tous les cas d’utilisation de la base de connaissances en téléapprentissage seront représentés par des modèles semblables construits sur la base de cette ontologie de tâche. Le cas présenté dans la figure 1 est un peu particulier car un seul acteur (un chercheur) régit toutes les opérations, mais en général, un cas d’utilisation mettra en jeu plus d’un acteur. Par la suite, la description des opérations, les ressources de support aux opérations, et les documents, intrants ou produits par les opérations, pourront être intégrés dans des environnements de support à la tâche destinés à chaque catégorie d’acteurs. Par exemple, un environnement correspondant au processus illustré à la figure 1, destiné aux chercheurs en téléapprentissage, pourra regrouper les ressources (documents, outils, services) autour des opérations à effectuer telles que la conception de projets, l’utilisation et analyse des données expérimentales, la revue de littérature, l’aide au référencement des résultats de recherche, etc. 3. Ontologie du domaineL’examen des cas d’utilisation, puis leur formalisation à l’aide d’une ontologie de tâche sous la forme de modèles graphiques, mettent en évidence la nécessité d’une représentation structurée du domaine, acceptée et partagée largement par l’ensemble des utilisateurs de la base de connaissances et de la banque de ressources. En d’autres termes, il s’agit, dans l’exemple examiné ici, de définir une ontologie, un modèle des connaissances en téléapprentissage. En philosophie, on appelle "ontologie" une théorie concernant les types d’objets qui existent indépendamment de tout agent extérieur les connaissant. L’ontologie, en tant que discipline philosophique, étudie ces théories de l’existence. L’intelligence artificielle a adopté le terme "ontologie" en lui donnant le sens plus restreint de définition formelle d’un système de représentation des connaissances d’un domaine. La représentation des connaissances est le thème central de ce domaine des sciences cognitives qu’est l’intelligence artificielle, lequel se fixe un double but : 1) comprendre le fonctionnement de l’intelligence humaine par la reproduction de certains de ses processus par des programmes informatiques, et 2) prolonger ou soutenir l’intelligence humaine en construisant des agents intelligents capables de réaliser diverses tâches évoluées, ce qui nous intéresse ici. Selon Gruber [Gruber93], "an ontology is an explicit specification of a conceptualization". L’ontologie est un système de termes primitifs utilisés dans la construction de systèmes artificiels ou une "métabase de connaissance" [Mizoguchi00]. En ce sens, l’ontologie est un type particulier de modèle de connaissances [Paquette02] permettant de construire une ou plusieurs bases de connaissances du même type. La majorité des auteurs s’entendent sur le fait qu’une ontologie se compose :
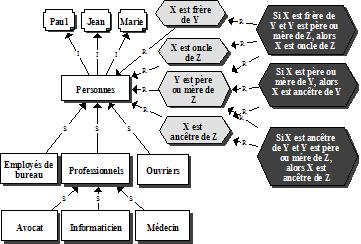
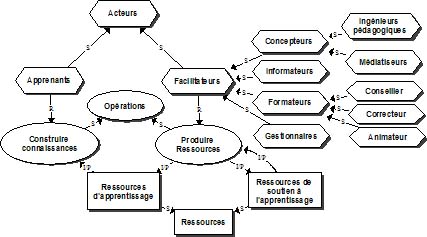
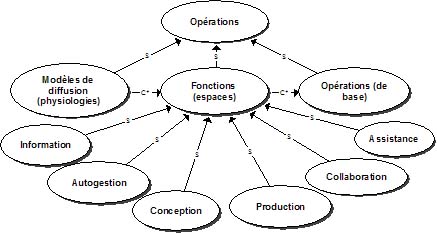
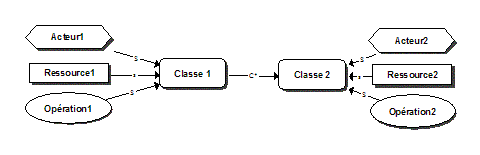
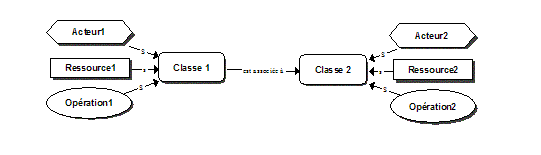
Illustrons ces idées à l’aide d’un exemple simple. On peut s’intéresser aux professions des personnes en décrivant une taxonomie de professions représentée par le modèle MOT de la figure 2. Figure 2 : Un exemple d’une ontologie simple Sur ce modèle, la classe des personnes, regroupant des individus tels que Paul, Jean ou Marie, est subdivisée en sous-classes telles que "Employés de bureau", "Professionnels" ou "Ouvriers" et celles-ci, en sous-classes plus spécialisées comme "Avocats", "Informaticiens" ou "Médecins". Cette ontologie contient également des relations de parenté entre des personnes telles que "est frère de", "est père ou mère de", "est oncle de" et "est ancêtre de". Ces propriétés sont représentées sur le modèle par des principes élémentaires (hexagones gris dans la figure), appelés aussi "propriétés". Si on assigne des individus précis à X et Y, ces principes deviendront des assertions : "Jean est frère de Marie" ou "Jean est oncle de Paul". On complète la définition de la base de connaissances en ajoutant trois règles d’inférence ou axiomes représentés dans le modèle par des principes (hexagones noirs sur la figure) établissant des liens entre les relations. Le premier axiome permet de définir la relation "est oncle de" en fonction des relations "est frère de" et "est père ou mère de". Les deux autres axiomes permettent de définir la relation "est ancêtre de" en fonction de la relation "est père ou mère de". Néanmoins, la base de connaissances pourrait être complétée par une règle affirmant que les mots "ancêtre" et "ancestor" ont la même signification. Les deux axiomes suivants définissent ces deux termes comme équivalents : "Si X ancêtre de Y, alors X ancestor de Y", "Si X ancestor de Y, alors X ancêtre de Y". Ces deux axiomes permettraient à un agent informatique de traiter des informations dans les deux langues. On peut aussi utiliser des axiomes pour surmonter des différences terminologiques dans deux sites traitant du même sujet, mais qui utilisent des termes différents ayant la même signification. Les ontologies peuvent améliorer le fonctionnement du Web de multiples façons, notamment pour accroître la précision des recherches d’information. Le fondateur du Web et actuel directeur du consortium W3, Tim Berners-Lee, propose avec ses collègues [BernersLee01] de doter l’Internet d’informations dont la signification est interprétable par un programme informatique, celui-ci pouvant faire des recherches d’information de façon plus intelligente que maintenant. Le Web sémantique n’est pas un autre réseau Internet mais une extension de celui-ci contenant de plus en plus de pages pointant sur des descriptions du sens des informations qui s’y trouvent, et donc interprétables par un agent informatique de recherche3. Compte tenu des millions, sinon des milliards, de pages actuellement accessibles dans l’Internet, le passage au Web sémantique est absolument essentiel. Il ne se fera pas du jour au lendemain, mais il est déjà commencé. Il se réalisera probablement domaine par domaine par les membres d’une communauté de pratique intéressés par un même domaine et qui procède à sa définition [BernersLee01]. C’est ce que nous voulons commencer à faire pour notre domaine de recherche, le téléapprentissage. Même dans un domaine spécialisé en émergence comme celui-là, il existe des centaines de chercheurs qui participent annuellement à des dizaines de colloques et qui ont déjà produit des milliers de documents, d’outils et de ressources sur le sujet. La figure 3 présente une première ontologie du domaine du téléapprentissage qui devra être approfondie par la recherche et la collaboration entre chercheurs sur le plan international. On y retrouve trois taxonomies : celle des acteurs subdivisés en apprenants et en facilitateurs de divers types, celle des opérations telles que "construire des connaissances" et "produire des ressources", et celle des objets d’apprentissage ou ressources, subdivisés en ressources d’apprentissage ou de soutien à l’apprentissage. Figure 3 : Modèle principal d’une ontologie du téléapprentissage La figure 4 développe quelque peu la taxonomie des opérations. Outre la relation de spécialisation (S) entre classes et sous-classes, les modèles de la figure 3 et de la figure 4, font apparaître les diverses relations présentées à la figure 5, telles que la relation de régulation (R) entre un acteur et une opération, les relations intrant (I/P) entre une ressource et une opération ou produit (I/P) entre une opération et une ressource. La relation de composition simple (C) ou de composition multiple (C*) entre un objet et ses composantes permet notamment de définir un groupe de personnes et les acteurs qui le composent, un groupe de ressources et ses composantes ou un groupe d’opérations et ses composantes. D’autres relations pourront également être définies entre les objets du modèle en précisant les types d’objets impliqués et en remplaçant ultérieurement le terme "est associé à" par un terme plus précis qui devra alors être défini4. Figure 4 : Sous-modèle de l’ontologie du téléapprentissage Pour compléter l’ontologie, il nous reste à définir des règles d’inférences ou axiomes définissant certaines propriétés des relations. Le tableau 2 en présente quelques exemples avec une représentation graphique correspondante5. Ces exemples mettent en évidence la réutilisation des relations dérivées telles que "consulte ou utilise" dans l’énoncé d’autres axiomes.
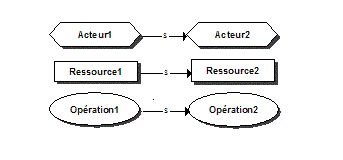
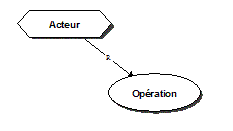
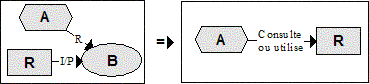
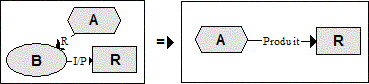
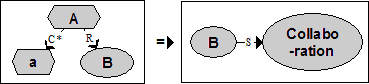
Figure 5 : Convention de représentation graphique des relations de l’ontologie
Tableau 2 : Quelques exemples d’axiomes du domaine du téléapprentissage 4. Les ressources et leur gestionNous allons maintenant examiner comment une ontologie comme celle qui vient d’être esquissée peut être utilisée pour nous aider à repérer et à traiter des ressources dans le cadre de cas d’utilisation concrets comme celui présenté à la figure 1. Pour ce faire, nous compléterons d’abord l’ontologie du téléapprentissage par une taxonomie des ressources, puis nous discuterons de l’intégration des taxonomies, des relations et des axiomes d’une ontologie dans des outils informatisés de gestion des ressources. Nous utilisons le terme "ressource" que nous trouvons plus large que celui d’"objet d’apprentissage" (learning objects). Beaucoup d’auteurs tels que Wiley [Wiley02] préfèrent limiter la notion d’objets d’apprentissage à des ressources sous forme de fichiers numériques. Dans la pratique toutefois, la plupart des projets de "learning objects repositories" prennent en compte également les outils, et parfois les moyens de communication ou les services offerts par des acteurs à d’autres acteurs. Dans les systèmes de téléapprentissage, on voudra également référencer des documents imprimés, des documents audiovisuels sur support analogique, et également des services de conseil, d’aide technique ou autres qui sont également des composantes indispensables au fonctionnement d’un environnement de téléapprentissage. De plus, nous voulons pouvoir traiter non seulement les ressources destinées aux apprenants, mais aussi celles dont les autres acteurs (formateurs, présentateurs, gestionnaires, concepteurs, etc.) auront besoin pour effectuer leurs tâches. On ne peut qualifier ces ressources d’"objets d’apprentissage" sauf dans le sens d’"objets pour soutenir l’apprentissage". Ces considérations nous ont conduit à la taxonomie6 des ressources présentée au tableau 3 sous la forme d’une arborescence multicritères. Ce dernier terme signifie qu’une classe de ressources peut être subdivisée selon plus d’une hiérarchie classe/sous-classes. Par exemple, les documents pourront être classifiés selon le type de média, le type de support, le type de structure d’information, donc selon plusieurs classes permettant de les décrire et de les repérer.
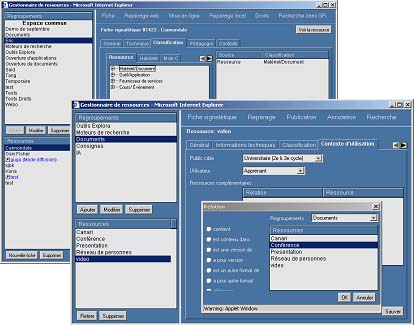
Tableau 3 : Une taxonomie de ressources Une taxonomie aide à référencer ou à repérer des ressources en spécifiant leurs propriétés au moyen de ce que l’on appelle des métadonnées. Une fiche de métadonnées est semblable aux fiches de références d’une bibliothèque ou d’une médiathèque; on y retrouve des champs tels l’auteur, le contenu, la localisation dans la bibliothèque, les droits d’accès, des références administratives et techniques, ainsi que des relations avec d’autres ressources. Dans le cas des ressources disponibles sur le Web, bien que l'Internet nous ait fourni des standards comme HTTP, FTP et HTML qui facilitent énormément la recherche d’information, il ne fournit actuellement aucune façon fiable de faire des recherches sur le Web, notamment selon des critères comme la date de création des informations, leur taille ou d’autres critères pertinents pour leur utilisation en éducation. Les spécifications élaborées par des organismes tels que IMS [IMS00] et IEEE-LTSC [IEEE01] visent à remédier à ces problèmes et constituent un élément important pour construire un Web sémantique et faciliter la réutilisation des ressources au-delà des plateformes. À titre d’exemple, dans un effort de simplification, le protocole CANCORE [Friesen01] inclut huit des neuf catégories principales de la norme IMS/IEEE-LOM. La catégorie "Général" décrit les fonctions indépendantes du contexte de la ressource : titre, langue, taille et description du contenu. La catégorie "Cycle de vie" décrit les circonstances du développement de l'objet : ses promoteurs, ses développeurs et autres participants, la date de sa création et le numéro de version. La catégorie "Métamétadonnées" décrit la fiche de métadonnées elle-même : auteurs et valideurs de la fiche, langue de la fiche, date de création ou de validation. Les catégories "Technique" et "Éducatif" décrivent le format technique de la ressource, soit la taille, l'emplacement et les conditions d’accès, ainsi que son contexte éducatif tel que le niveau d’âge, le niveau scolaire, le rôle et la langue des utilisateurs. La catégorie "Droits" permet de spécifier si des conditions monétaires ou autres sont rattachées à l’utilisation de la ressource. La catégorie "Relations" permet d’établir des liens entre les ressources, par exemple, telle ressource est une version d’une autre ressource ou contient telle autre ressource. Finalement, la catégorie "Classification" permet à une organisation d’ajouter une ou plusieurs taxonomies pour décrire par exemple le contenu de la ressource en fonction de classifications comme Dewey, Eric, Library of Congress, ou de classifications maison sur le type de ressource ou sur les habiletés requises ou visées. Dans le gestionnaire de ressources développées pour le système EXPLOR@ [Paquette01b] présenté à la figure 6, nous avons retenu les spécifications CANCORE, auxquelles nous nous proposons d’ajouter certaines taxonomies présentées plus haut dans la partie "Classification". La première fenêtre illustre l’intégration de la taxonomie des ressources de téléapprentissage; le choix d’une ou plusieurs catégories permettant de décrire les ressources de téléapprentissage selon qu’elles traitent de tel ou tel type de ressource. Soulignons que la taxonomie des ressources peut jouer deux rôles. Dans le premier, elle permet de caractériser une ressource sur le téléapprentissage selon qu’il s’agit d’un document, d’un outil, d’un service fourni par des personnes ressources ou d’un cours ou événement d’apprentissage. S’il s’agit d’un document par exemple, on pourra spécifier le type de média, de support, de structure d’information et de fonction à l’aide des termes de la taxonomie des ressources. C’est là l’un des critères de recherche possible dans le référentiel des ressources. Dans son deuxième rôle, plus intimement lié aux cas d’utilisation d’une base de connaissances sur le téléapprentissage, la taxonomie des ressources sert à définir un aspect du contenu des ressources de téléapprentissage : de quel type de connaissances les ressources recherchées traitent-elles? En coordination avec ce second rôle, on pourrait faire intervenir également la taxonomie des opérations et des acteurs, ce qui permettrait de spécifier plus précisément le contenu des ressources de téléapprentissage que nous recherchons. On pourrait par exemple lancer des recherches comme la suivante : "trouver tous les documents, les outils et les experts compétents qui traitent des jeux et des simulations (type de ressource) pour des apprenants du secondaire (type d’acteur), dans des activités de collaboration (type d’opération). Figure 6 : Caractérisation d’une ressource à l’aide de taxonomies dans le gestionnaire de ressources Explor@2 Par ailleurs, les relations7 et les axiomes de l’ontologie permettraient d’augmenter l’efficacité des agents de recherche. Par exemple, une recherche de documents portant sur les opérations d’autogestion permettra de repérer non seulement ceux qui spécifient explicitement ce type d’opération, mais aussi ceux qui traitent d’opérations particulières d’autogestion comme la planification par les étudiants de leurs travaux. La relation de spécialisation (S) définie dans l’ontologie permet à l’agent informatique de retracer ces documents. Par ailleurs, l’application d’une règle d’inférence comme "Si un acteur A se compose d’acteurs a et si A régit une opération B, alors B est une opération de collaboration" permettra de repérer non seulement les ressources qui traitent explicitement de la collaboration, mais aussi celles traitant d’opérations régies par un acteur composé (un groupe). 5. Environnement d’utilisation des connaissances et des ressourcesLe système EXPLOR@-II [Paquette01b] permet de créer des environnements flexibles et ouverts regroupant des ressources à partir des cas d’utilisation et de leurs modèles de tâche. Utilisons comme exemple le cas d’un chercheur en téléapprentissage impliqué dans trois des cas d’utilisation présentés au tableau 1 dont celui de la conception d’un projet de recherche présenté à la figure 1. Ce modèle permet de construire l’arborescence suivante :
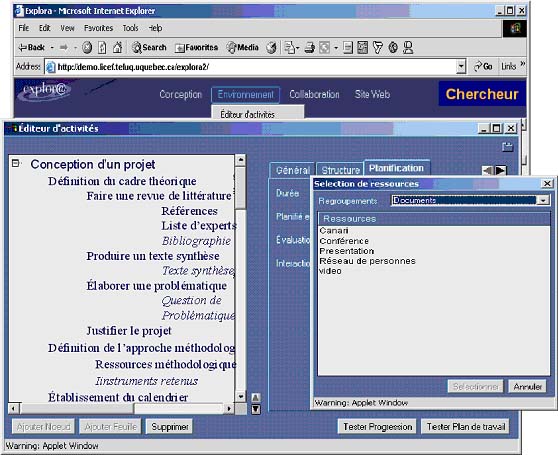
Cette arborescence est une structure de tâche dans laquelle les cas d’utilisation peuvent être ajoutés les uns à la suite des autres. Le début de l’arborescence portant sur la conception de projets de recherche est obtenu à partir du modèle de la figure 1 sur la base des liens de composition entre les opérations. Le dernier niveau (les feuilles) contient le nom des ressources, intrants ou produites (en italique), dans chaque opération parent (du niveau précédent). EXPLOR@-II met à la disposition des usagers divers outils permettant de construire de telles arborescences et d’associer aux nœuds de l’arborescence des descriptions et des conseils, ainsi que des ressources repérées ou publiées à l’aide du gestionnaire de ressources. La figure 7 présente certains de ces outils. La première fenêtre est le tableau de bord de l’acteur, grâce auquel un chercheur obtient un accès à divers éditeurs dont l’éditeur des activités, ouvert dans la deuxième fenêtre. C’est cet outil qui permet d’éditer l’arborescence et de décrire les différentes opérations et les ressources d’un cas d’utilisation où intervient l’acteur. La troisième fenêtre est un appel au gestionnaire de ressources qui permet d’associer au nœud sélectionné dans l’arborescence, une ressource repérée et référencée par le gestionnaire de ressource. Le repérage de la ressource peut se faire à l’aide de moteurs de recherche sur le Web, par navigation (browsing) sur le poste de travail et le réseau local où se trouve l’utilisateur ou en utilisant le module de recherche propre au gestionnaire de ressource. Ce dernier utilise les métadonnées référençant les ressources à l’aide de l’ontologie du téléapprentissage. Voici une démarche typique d’un utilisateur de cet environnement :
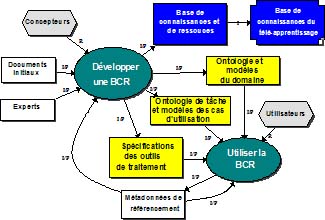
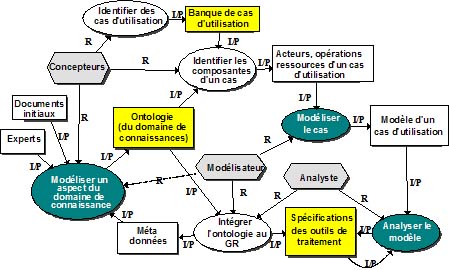
Figure 7 : L’environnement Web d’un utilisateur de la base de connaissances et de ressources 6. Construction d’une base de connaissances et de ressources (BCR)Nous allons maintenant généraliser cette démarche de façon à ce qu’elle puisse s’appliquer à d’autres domaines que le téléapprentissage. La figure 8 présente une démarche générale, situant la démarche particulière que nous avons suivie dans les sections précédentes comme une instanciation de ce métaprocessus. Le développement d’une BCR est réalisé par une équipe de concepteurs et d’experts dans le domaine d’application, en interaction avec un groupe d’utilisateurs. L’équipe de concepteurs construit une banque de cas d’utilisation en consultant des experts et de futurs utilisateurs du domaine. Elle développe une ontologie de la tâche et une ontologie du domaine et participe à la spécification des outils de gestion des ressources et de traitement des informations. Figure 8 : Le métaprocessus de construction d’une base de connaissances et de ressources (BCR) Les utilisateurs emploient ces outils, notamment le gestionnaire de ressources pour consulter, utiliser et annoter des ressources. Ils produisent également des métadonnées de référencement de nouvelles ressources qui sont intégrées au référentiel. À leur tour, ces nouvelles métadonnées de référencement et les dialogues d’annotation au sujet des métadonnées existantes alimentent l’équipe de concepteurs, leur permettant d’étendre l’ontologie, d’ajouter ou de préciser des cas d’utilisation et d’établir les spécifications de nouveaux outils de traitement. Le modèle de la figure 9 précise ce processus en identifiant deux nouveaux acteurs qui collaborent avec l’équipe de concepteurs. Un modélisateur construit un modèle de tâche des cas les plus intéressants de la banque de cas. Ces modèles seront ensuite examinés par un analyste informatique pour établir les spécifications des outils de recherche et de traitement de l’information. En collaboration avec le modélisateur, l’informaticien définira des interfaces de présentation des listes de ressources et des modes d’intégration de l’ontologie dans des agents informatiques de recherche. Figure 9 : Le métaprocessus de construction Construire une ontologie revient à construire une théorie d’un domaine de connaissances. L’ontologie étant une forme particulière de modèle des connaissances, on peut appliquer des techniques générales de construction de modèles [Paquette02] qui débutent par l’identification du but du modèle ou de l’ontologie à partir des cas d’utilisation. Sur cette base, on peut particulariser les cinq processus de base8 de la modélisation comme suit.
7. ConclusionLe processus itératif que nous avons décrit permet de spécifier les ressources nécessaires aux acteurs dans leurs rôles de traitement des connaissances. Inversement, l’utilisation de ces ressources dans le traitement du domaine permet de faire évoluer le modèle du domaine et les modèles des fonctions d’utilisation. Ces modèles permettent à leur tour d’identifier de nouvelles ressources, amorçant ainsi un nouveau cycle. Cette métaméthode de recherche et de développement, de représentation et de transfert des connaissances, a été appliquée et validée à plusieurs reprises au cours des huit dernières années, notamment en ingénierie pédagogique (la méthode MISA), pour la modélisation d’une école informatisée clés en main [Basque99] et pour la définition d’un gestionnaire de ressources [Paquette03]. Toutefois, l’intégration d’une ontologie d’un domaine dans un gestionnaire de ressources reste une question largement inexplorée. Elle nous apparaît centrale pour la construction d’environnements d’apprentissage, de recherche ou de travail collaboratif ayant un sens pour leurs usagers, et plus généralement pour l’implantation d’une culture de gestion des connaissances dans les organisations. Les aspects sociologiques du métaprocessus de construction/utilisation d’une base de connaissances et de ressources devront également faire l’objet de recherches intensives pour lever les barrières à l’implantation des environnements de téléapprentissage et le support aux communautés de pratiques [Wenger98], moyens essentiels favorisant la gestion des connaissances dans les organisations. RemerciementsLes auteurs tiennent à remercier Valorisation-Recherche Québec (VRQ) pour son soutien financier. RéférencesBibliographieBasque, J., Rocheleau, J., Paquette, G., Paquin, C. (1998). "An Object-Oriented Model of a Computer-Enriched High School". Dans T. Ottmann et I. Tomek (eds), Proceedings of ED-MEDIA/ED-TELECOM 98. Charlottesville, VA : Association for the Advancement of Computing in Education. <31 juillet 2003 : http://benhur.teluq.uquebec.ca/~jbasque/object_model.pdf> Berners-Lee, T., Hendler, J., Lassila, O. (2001). "The Semantic Web". Scientific American, Mai. Boosch, G., Jacobson, J., Rumbaugh, I. (1999). The Unified Modeling Language User Guide. Don Mills, Ont.: Addison-Wesley. Chandrasekaran B., Josephson, J. R., Benjamins, R. (1998). "Ontology of tasks and methods". Workshop on Applications of Ontologies and Problem-Solving Methods. 13ème Conférence Européenne d’Intelligence Artificielle ECAI'98, 23-28 août, Brighton, Grande-Bretagne. <31 juillet 2003 : http://delicias.dia.fi.upm.es/WORKSHOP/ECAI98/papers/chandra.PDF> Davenport, T. H., Prusak, L. (1998). Working Knowledge: How Organizations Manage What They Know. Boston: Harvard Business School Press. Friesen, N. (2001). Metadata for Learning Object Repositories: The CanCore Solution. Article non publié. Voir aussi <31 juillet 2003 : http://www.cancore.ca> Gruber T. (1993). "A Translation Approach to Portable Ontology Specifications". Knowledge Acquisition, 5 (2), 199-220. Guarino N., Giaretta, P. (1995). "Ontologies and Knowledge Bases: Towards a Terminological Clarification". Dans N. Mars (Éd.), Towards Very Large Knowledge Bases: Knowledge Building and Knowledge Sharing (pp.25-32). Amsterdam: IOS Press. IEEE-LTSC (2001). Standard for Information Technology - Education and Training Systems - LOs and Metadata. <31 juillet 2003 : http://ltsc.ieee.org/wg12/index.html>. IMS Global Learning Consortium (2000). IMS Learning Resource Meta-data Best Practices and Implementation Guide. <31 juillet 2003 : http://www.imsproject.org/metadata/mdbest01.html> Jin, L., Chen, W., Hayashi, Y., Ikeda, M., Mizoguchi, R. (1999). "An Ontoloty-Aware Authoring Tool". Dans S. Lajoie et M. Vivet (éds.), Open learning environment, Proceedings of AI in Education, AIED '99, Le Mans, France (pp. 85-92)., Amsterdam : IOS Press. Mizoguchi, R., Kozaki K., Sano, T., Kitamura, Y. (2000). "Construction and Deployment of a Plant Ontology". Proceedings of the 12th International Conference EKAW2000, Juan-les-Pins, France, (Lecture Notes in Artificial Intelligence 1937) (pp.113-128). Berlin: Springer-Verlag. Nillson, M., Matthias, P. , Ambjörn, N. (2001). Semantic Web Metadata for e-Learning - Some Architectural Guidelines. <31 juillet 2003 : http://www2002.org/CDROM/alternate/744/index.html > Paquette, G. (2001a). "TeleLearning Systems Engineering – Towards a new ISD model" , Journal of Structural Learning, 14(4), 319-354. Paquette, G., (2001b). Designing Virtual Learning Centers. Dans H. Adelsberger, H., B. Collis et J. Pawlowski (Eds) Handbook on Information Technologies for Education & Training (pp. 249-272). Berlin: Springer-Verlag. Paquette, G. (2002). Modélisation des connaissances et des compétences : Pour concevoir et apprendre. Ste-Foy (Québec) : Presses de l’Université du Québec. Paquette, G., De la Teja, I., Lundgren-Cayrol, K., Léonard M. et Ruelland, D. (2003). "La modélisation cognitive, un outil de conception des processus et des méthodes d’un campus virtuel"., Revue canadienne d’éducation à distance, 17(3), 4-28. Paquette, G., Rosca, I. (2003). "Modeling the Delivery Physiology of Distributed Learning Systems"., Technology, Instruction, Cognition and Learning, 1(2), 183-209 Paquette, G., Tchounikine, P. (2002). "Contribution à l’ingénierie des système conseillers : Une approche méthodologique fondée sur l’analyse du modèle de la tâche". Science et Techniques Educatives, 9(3-4), 409-435. Staab, S., Studer, R., Schnurr, H.P., Sure, Y. (2001). "Knowledge Processes and Ontologies". IEEE Intelligent systems, 16(1), 26-34 Sveiby, K.E., (2001). What is Knowledge Management? <31 juillet 2003 : http://www.sveiby.com/articles/KnowledgeManagement.html>. Wenger, E. (1998). Communities of Practice. Learning, Meaning and Identity. (Learning in Doing: Social, Cognitive, and Computational Perspectives). Cambridge, Mass.: Cambridge University Press. Wiley, D.A. (2002). "Connecting learning objects to Instructional design theory: a definition, a methaphor, and a taxonomy". Dans D.A. Wiley (éd.), The Instructional Use of Learning Objects. Bloomington, Indiana: Agency for Instructional Technology/Association for Educational Communications of Technology. À propos des auteurs
Adresse : 4750, avenue Henri-Julien, Montréal (Québec), Canada H2T 3E4 Courriel : licef@licef.teluq.uquebec.ca Toile : www.cirta.org Courriel : www.licef.teluq.uquebec.ca [1] La notion de cas d’utilisation utilisée ici, proposée initialement par Ivar Jacobson, est intégrée dans le UML, l’Unified Modeling Language, méthode de modélisation utilisée en génie logiciel [Boosch99]. [2] La méthode de représentation des connaissances MOT (modélisation par objets typés) utilisée dans cet article est décrite dans [Paquette02]. [3] Le langage XML permet de créer une description structurée du contenu d’une page Web, laquelle peut ensuite être interprétée par des scripts ou des programmes informatiques. La signification de ce contenu peut être spécifiée par un protocole de description de ressources appelé RDF (Ressource Description Framework). Celui-ci représente les connaissances sous la forme de triplets, lesquels peuvent être rédigés en langage XML. Un triplet met en relation un sujet, une relation et un complément, ce qui permet de faire des assertions élémentaires à propos de personnes, de pages Web ou de tout autre type d’objet. Par exemple, dans un ensemble de page Web à propos des relations de parenté entre des personnes, le RDF permettra de représenter des assertions impliquant ces personnes et des relations telles que "est frère de" ou "est père ou mère de". Ainsi, à partir des assertions "Jean est frère de Nathalie" et "Nathalie est mère de Nicole", et de la règle de définition "Si X est frère de Y et Y est mère de Z, alors X est oncle de Z", un agent informatique de recherche pourra déduire que "Jean est oncle de Nicole" sans que cela ne soit écrit explicitement comme information sur une page Web. On peut alors parler d’agents intelligents, puisque ceux-ci peuvent déduire des informations qui ne sont pas explicitement énoncées. [4] Les relations S, R, I/P C et C* utilisées ici ont une sémantique précise définie dans le cadre du système de représentation MOT. Voir à cet effet [Paquette02] [5] Voir aussi [PaquetteTchounikine02] pour une discussion d’autres règles d’inférences liées aux relations du système de représentation MOT. [6] Cette taxonomie regroupe plusieurs typologies intégrées dans la méthode d’ingénierie des systèmes d’apprentissage (MISA 4.0) [Paquette01a]. Elle est simplifiée pour les besoins de cet article. [7] La seconde fenêtre de la figure 6 illustre ce fait en montrant qu’il est possible d’intégrer des relations à un gestionnaire de ressources. Cependant les relations sont définies entre les ressources, et non entre les connaissances traitées dans la ressource. La figure illustre tout de même une façon d’intégrer les taxonomies et les relations d’une ontologie pour des recherches dans un Web sémantique. [8] On retrouve une démarche analogue en cinq phases dans [Staab01]. [9] Par exemple, Jin et al. [Jin99] proposent de créer un système auteur de matériel éducatif fondé sur deux ontologies, l’une décrivant la tâche d’apprentissage par des concepts représentant les rôles, et l’autre décrivant les concepts représentant le domaine d’application. C’est également l’approche utilisée par EXPLOR@-II, laquelle est basée sur la méthode d’ingénierie pédagogique MISA [Paquette99]. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Référence de l'article :Gilbert PAQUETTE, Jacqueline BOURDEAU, France HENRI, Josianne
BASQUE, Michel LEONARD, Marcelo MAINA, Construction d'une base de
connaissances et d’une banque de ressources pour le domaine
du téléapprentissage, Revue STICEF, Volume
10, 2003, mis en ligne le 15-11-2003, http://sticef.org,
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||