de l´Information et
de la Communication pour
l´Éducation et la Formation
Volume 25, 2018
Article de recherche
Numéro Spécial
Sélection de la conférence
EIAH 2017

Étude du comportement des apprenants dans les travaux pratiques et de sa corrélation avec la performance académique
![]() RÉSUMÉ : Cette
étude analyse le comportement des apprenants au sein de laboratoires
distants afin d'identifier de nouveaux facteurs de prédiction du
succès de l'apprentissage. À partir d'une fouille de motifs
séquentiels d'actions, nous définissons des stratégies
d'apprentissage, indicateurs de plus haut niveau d'abstraction. Certaines sont
corrélées à la performance académique des
apprenants, comme la construction d'une action étape par étape,
plus fréquemment appliquée par les étudiants de plus haut
niveau de performance. Tandis que notre proposition peut s'appliquer à
d'autres contextes, nos résultats nous ont permis d'implanter de nouveaux
outils de suivi et de guidage dans notre environnement.
RÉSUMÉ : Cette
étude analyse le comportement des apprenants au sein de laboratoires
distants afin d'identifier de nouveaux facteurs de prédiction du
succès de l'apprentissage. À partir d'une fouille de motifs
séquentiels d'actions, nous définissons des stratégies
d'apprentissage, indicateurs de plus haut niveau d'abstraction. Certaines sont
corrélées à la performance académique des
apprenants, comme la construction d'une action étape par étape,
plus fréquemment appliquée par les étudiants de plus haut
niveau de performance. Tandis que notre proposition peut s'appliquer à
d'autres contextes, nos résultats nous ont permis d'implanter de nouveaux
outils de suivi et de guidage dans notre environnement.
![]() MOTS CLÉS : Learning
analytics, étude comportementale, laboratoires distants,
stratégies d’apprentissage, apprentissage de
l’informatique.
MOTS CLÉS : Learning
analytics, étude comportementale, laboratoires distants,
stratégies d’apprentissage, apprentissage de
l’informatique.
![]() ABSTRACT : This
study analyzes students’ behavior in a remote laboratory environment to
identify new factors of prediction of learning success. Based on a sequential
pattern mining of actions, we define learning strategies as indicators of higher
level of abstraction. Results show that some of them are correlated to
learners’ academic performance, such as the construction of a complex
action step by step, more often applied by learners of a higher level of
performance. While our proposals are domain-independent and can apply to other
learning contexts, the results of this study then led us to instrument new
visualization and guiding tools in our remote lab environment.
ABSTRACT : This
study analyzes students’ behavior in a remote laboratory environment to
identify new factors of prediction of learning success. Based on a sequential
pattern mining of actions, we define learning strategies as indicators of higher
level of abstraction. Results show that some of them are correlated to
learners’ academic performance, such as the construction of a complex
action step by step, more often applied by learners of a higher level of
performance. While our proposals are domain-independent and can apply to other
learning contexts, the results of this study then led us to instrument new
visualization and guiding tools in our remote lab environment.
![]() KEYWORDS : Learning
analytics, behavioral study, remote laboratories, learning strategies, computer
science education.
KEYWORDS : Learning
analytics, behavioral study, remote laboratories, learning strategies, computer
science education.
1. Introduction
La recherche sur la prédiction du succès de l’apprentissage est au cœur de nombreuses études depuis plusieurs dizaines d’années (Blikstein, 2011), (Bunderson et Christensen, 1995), (Vihavainen, 2013), (Workman, 2004). La prédiction de la performance s’appuie traditionnellement sur la collecte de données à partir de pré-tests, de questionnaires, des résultats académiques antérieurs, voire d’informations telles que les styles d’apprentissage, l’efficacité (Wilson et Shrock, 2001) ou encore les attentes de l’apprenant envers le cours (Rountree et al., 2004). Cependant, le développement des TICE, l’émergence de la fouille de données d’apprentissage, et l’analyse de ces dernières offrent de nouvelles possibilités pour explorer le comportement des apprenants en situation d’apprentissage et étudier son influence sur leur performance.
Les laboratoires virtuels et distants (Virtual and Remote Laboratories, VRL) sont des environnements d’apprentissage dédiés à l’apprentissage exploratoire, appliqué dans des activités pratiques médiatisées par l’Informatique. Dans les EIAH (Environnements Informatiques pour l’Apprentissage Humain) pour les VRL, les apprenants développent des compétences liées à la démarche scientifique à travers leurs interactions avec les dispositifs distants physiques ou simulés, mais également des compétences de travail en équipe par les interactions qu’ils ont entre eux ou avec les enseignants. Par le suivi de ces interactions, ces EIAH permettent d’explorer les comportements des apprenants à un niveau de détail élevé, et peuvent donc offrir une meilleure compréhension du processus d’apprentissage qu’ils mettent en œuvre. Si l’étude de leurs actions à travers différentes mesures d’activité est une première approche, l’analyse de motifs séquentiels peut fournir une autre compréhension de leurs comportements (Aleven et al., 2006). La fouille de motifs séquentiels pour identifier les processus d’apprentissage des apprenants est donc à considérer (Agrawal et Srikant, 1995).
Pour étudier les liens potentiels entre les comportements des apprenants et leur performance, nous avons conduit une expérimentation en contexte d’apprentissage réel, sur 107 étudiants inscrits dans un cours d’administration des systèmes et réseaux du DUT (Diplôme Universitaire Technologique) Informatique de l’Université de Toulouse III. Nous explorons dans cet article les interactions entre les apprenants et les dispositifs distants qu’ils manipulent (i.e. des machines virtuelles) pour analyser les corrélations potentielles entre la performance de ces apprenants et des indicateurs quantitatifs d’une part, et des motifs séquentiels d’action d’autre part. Notre objectif est d’identifier, pour une session de TP, des motifs comportementaux qui reflètent une meilleure réalisation des objectifs d’apprentissage, afin de prédire la performance académique des étudiants et de guider ces derniers dans la complétion de leurs tâches.
La section suivante introduit notre contexte d’enseignement et Lab4CE, notre environnement de VRL pour l’apprentissage de l’Informatique, en détaillant son modèle de collecte de données sur lequel nous nous appuyons pour cette étude. Une troisième section présente le protocole expérimental ainsi que le jeu de données exploité dans notre analyse, avant de définir la mesure de la performance dans notre contexte. Après une première analyse effectuée sur des indicateurs numériques tels que le nombre d’actions réalisées par apprenant ou le temps écoulé entre deux actions, la cinquième section propose une approche différente : en réalisant une fouille de motifs, nous détectons plusieurs séquences d’actions représentatives du niveau de performance des apprenants. Ces séquences permettent alors de forger des indicateurs comportementaux de plus haut niveau d’abstraction, assimilés à des stratégies d’apprentissage et corrélés avec la réussite des apprenants. Dans une discussion, nous présentons les évolutions apportées à Lab4CE suite aux résultats de notre étude et positionnons notre approche par rapport aux travaux existants dans ce domaine.
2. Lab4CE, un environnement pour l’apprentissage pratique de l’Informatique
2.1. Contexte d’enseignement
Une partie du programme du DUT Informatique est dédiée à l’apprentissage de l’administration des systèmes et réseaux (ASR). Dans ces enseignements où la pratique est mise en avant, les étudiants doivent acquérir un ensemble de connaissances théoriques liées aux systèmes de gestion de fichiers, processus et gestion des contrôles d’accès, ainsi que différents savoir-faire inhérents à la maîtrise des commandes qu’offre un système d’exploitation. À l’IUT (Institut Universitaire Technologique), les travaux pratiques représentent une part importante des enseignements au sein desquels les étudiants peuvent confronter leur compréhension des concepts à la réalité d’une infrastructure informatique, et s’exercer à la configuration et l’administration de ses différents composants.
Les laboratoires physiques mis à disposition à l’Université souffrent de problèmes connus (Corter et al., 2004), (Ma et Nickerson, 2006) : un nombre insuffisant de machines, avec des périodes d’accès restreintes. Par exemple, l’IUT n’est pas en mesure de fournir un poste par étudiant à chaque TP. De plus, l’apprentissage de l’ASR soulève d’autres problèmes. Un grand nombre de manipulations exige les droits d’accès complets sur la machine, donnés habituellement à l’utilisateur « administrateur » (sur les systèmes Microsoft© Windows©) ou « root » (sur les systèmes Unix/Linux), par exemple pour installer un logiciel ou configurer une carte réseau ; ce rôle ne peut trivialement être donné aux apprenants sur les machines physiques de l’institut. De plus, l’apprentissage pratique des réseaux n’a d’intérêt que si les étudiants sont amenés à travailler avec un réseau de ressources, c’est-à-dire un ensemble d’ordinateurs et d’équipements d’interconnexion. Or doter chaque apprenant de plusieurs machines est inenvisageable d’un point de vue logistique et économique. Face à ces problèmes, les VRL représentent une solution intéressante tout en bénéficiant des augmentations pédagogiques offertes par les EIAH. Nous avons ainsi conçu Lab4CE, un VRL dédié à l’apprentissage de l’Informatique.
2.2. Vue générale de Lab4CE
Lab4CE, acronyme de « Laboratory for Computer Education », est une plateforme web s’appuyant sur un gestionnaire de cloud pour déployer, à la demande, des laboratoires informatiques virtuels et munie d’un ensemble de fonctionnalités support à l’apprentissage (Broisin et al., 2017). Cet environnement a été conçu notamment pour s’affranchir des limites spatiales et temporelles, ainsi que des restrictions d’accès aux ressources informatiques mentionnées plus haut. La plateforme permet de fournir à chaque apprenant un ensemble d’équipements virtuels accessibles en tout lieu, à tout moment, sans limite d’utilisation : les étudiants sont administrateurs de leurs équipements.
Dans Lab4CE, les instructeurs peuvent concevoir un TP en définissant une infrastructure composée de machines et d’équipements d’interconnexion. Lorsqu’un apprenant se connecte pour une activité particulière et accède pour la première fois à son laboratoire (cf. figure 1), le système crée et configure automatiquement l’ensemble des ressources propres à l’étudiant. Celui-ci peut alors manipuler les machines (i.e. les démarrer, les mettre en veille ou les arrêter, voir (1) sur la figure 1) et interagir avec celles-ci via leurs terminaux embarqués dans l’interface web (2), similaires à un terminal traditionnel. L’environnement propose des fonctionnalités dédiées à l’apprentissage. Plusieurs salons de discussion instantanée (3) permettent aux apprenants de communiquer de façon synchrone. Un support au travail collaboratif leur permet de s’inviter à partir du menu des utilisateurs connectés (4), puis de travailler ensemble sur la même machine virtuelle et voir ce que font les autres. Des outils d’awareness (5) permettent de comparer les actions que les étudiants réalisent à celles de leurs pairs. Un outil de gestion de l’entraide (6) leur permet également de demander de l’aide et d’y répondre, en offrant à l’aidant un accès en lecture aux terminaux de l’aidé et à son salon de discussion privé (Venant et al., 2017). Enfin, des applications d’analyse et de replay de sessions de travail sont également disponibles dans la plateforme. Pour l’expérimentation, toutes les fonctionnalités étaient accessibles, à l’exception de la fonctionnalité d’entraide.
Pour assurer ces différentes fonctionnalités, Lab4CE s’appuie sur un framework de collecte et d’analyse de données qui permet, à partir des interactions de l’apprenant avec le système, de forger différentes traces d’apprentissage et de les enrichir à la volée par le calcul d’indicateurs définis par l’enseignant ou le concepteur pédagogique.

Figure 1 • Interface d'expérimentation de Lab4CE
2.3. Framework et workflow d’analyse de données
La plupart des interactions de l’utilisateur avec Lab4CE sont collectées : les connexions au système, les messages instantanés, les demandes d’aide, les actions sur les laboratoires et les ressources, et la navigation entre les différentes interfaces de la plateforme. Concernant les interactions entre les utilisateurs et les terminaux des machines, chaque entrée dans le terminal est tracée, qu’elle provienne de l’utilisateur lorsqu’il écrit sur son clavier ou de la machine lorsque celle-ci répond.
Le framework illustré par la figure 2 a pour objectif la génération et le stockage d’enregistrements xAPI, ainsi que leur enrichissement par l’inférence d’indicateurs (Venant et al., 2016). Il s’inspire d’infrastructures existantes telles que celles proposées dans le projet Migen (Gutierrez-Santos et al., 2010) ou dans l’approche flexible et extensible de Hecking (Hecking et al., 2014). Cependant, à la différence de ces approches, notre architecture réside essentiellement côté client (i.e. dans le navigateur web de l’utilisateur), afin de bénéficier du potentiel de calcul distribué sur les postes clients connectés à la plateforme.

Figure 2 • Framework de traces
Notre proposition inclut trois couches de composants faiblement couplés côté client, ainsi que deux dépôts côté serveur. Les capteurs surveillent les flux de données sur des composants spécifiques de Lab4CE (voir (1) sur la figure 2), génèrent des éléments xAPI et les envoient au forgeur d’enregistrements sous forme d’événements (2). Le forgeur agrège les différents éléments en enregistrements xAPI, qui sont alors routés soit au moteur d’enrichissement (3a), soit directement au dépôt de traces (3b). Après une phase initiale où le moteur d’enrichissement souscrit au forgeur (B) pour recevoir les enregistrements qu’il peut enrichir d’après les règles décrites dans le dépôt de règles (A), il infère et ajoute à chaque enregistrement un ou plusieurs indicateurs, puis les renvoie au forgeur (4) avant leur stockage dans le LRS (5).
Les interactions entre les apprenants et leurs machines, sujet de cet article, reposent essentiellement sur les instructions Shell exécutées par ceux-ci via le terminal. Elles sont constituées d’une commande et, le cas échéant, d’options et d’arguments, que nous nommons indifféremment dans cet article par le terme « argument » : par exemple, ls –a -l est l’exécution constituée de la commande ls et des arguments -a et –l. À l’issue de son exécution, la machine peut retourner une réponse textuelle : par exemple, pour l’instruction ls –a –l, la réponse correspond à la liste détaillée de tous les fichiers et répertoires du répertoire courant.
Ainsi, lorsqu’un étudiant interagit avec un terminal d’une machine, le framework capture chaque caractère qui apparaît au sein du terminal (i.e. les caractères saisis par l’apprenant, et ceux retournés par la machine). Le moteur est capable de reconstituer les instructions exécutées, en distinguant la commande de ses arguments et de sa réponse. Grâce au moteur d’inférence, un ensemble de règles permettent de qualifier la justesse technique d’une commande à partir des informations précédentes, c’est-à-dire de calculer une valeur booléenne indiquant si l’instruction a été exécutée sans erreur par la machine (Venant et al., 2016). Pour valider le calcul de notre indicateur, nous avons manuellement évalué la justesse technique d’un échantillon de 300 commandes produites par les étudiants. Sur la base de cet échantillon, 298 commandes furent évaluées de façon identique par le moteur, soit dans 99,3% des cas. Un enregistrement xAPI d’une commande comprend donc : (i) l’horodatage, (ii) l’identité de l’apprenant, (iii) l’identifiant du laboratoire, (iv) celui de la machine, (v) le nom de la commande, (vi) ses arguments, (vii) la réponse de la machine suite à l’exécution de la commande, et (viii) la justesse technique de la commande.
3. Étude du comportement en situation d’apprentissage pratique
L’expérimentation a été conduite au département Informatique de l’IUT A, Université Toulouse III Paul Sabatier. Pendant la totalité de l’expérimentation, les apprenants ont utilisé Lab4CE pour réaliser les tâches pratiques qui leur étaient demandées.
3.1. Protocole expérimental et scénario d’apprentissage
Nous avons mené l’expérimentation pendant un cours d’introduction aux commandes et à la programmation Shell, avec 107 étudiants de première année, dont la répartition en genre reflétait celle de l’IUT. Ces étudiants étaient issus pour la majorité d’entre eux du lycée, où l’enseignement de l’Informatique était encore largement minoritaire. D’autre part, comme l’expérimentation a été réalisée au début du cours, les apprenants sont donc considérés dans cette étude comme débutants en Informatique
L’infrastructure sous Lab4CE était composée d’une machine virtuelle par étudiant, accessible pendant les 3 semaines ; cette machine était suffisante pour accomplir les tâches d’apprentissage. Chaque semaine, une session pratique en présentiel de 90 minutes était dispensée. Les trois semaines de cours visaient 3 objectifs pédagogiques principaux : la compréhension de commandes Shell, la maîtrise du système de gestion de fichiers de Linux par l’exploitation de ces commandes, et quelques concepts fondamentaux de la programmation Shell. Pour chaque session, les apprenants devaient réaliser une liste de tâches propres à la découverte de nouvelles commandes. Ils devaient tout d’abord comprendre par eux-mêmes ce que font ces commandes, comment les manipuler (i.e. quels arguments doivent/peuvent être utilisés), puis les utiliser pour réussir les tâches demandées. Pour la dernière session, les apprenants devaient réutiliser l’ensemble des commandes apprises pour réaliser des scripts Shell simples, constitués de différentes instructions Shell manipulées au sein de structures conditionnelles et itératives. Pour réaliser ce dernier objectif, les apprenants devaient exploiter des compétences acquises auparavant, pendant un cours d’introduction à l’algorithmique.
3.2. Données expérimentales
Une fois les valeurs extrêmes retirées, le jeu de données comprend N = 85 sujets qui ont soumis un total de 9183 commandes. La moyenne des commandes par apprenant est de μ = 108,00 avec un écart-type σ = 66,62 ; la valeur élevée de l’écart-type peut s’expliquer, d’une part, par la nature exploratoire de l’apprentissage qui engendre de fortes variations de l’engagement des apprenants dans ce type d’activité et, d’autre part, par l’utilisation de la plate-forme par certains apprenants en dehors des sessions pratiques en présentiel. Le nombre minimum de commandes soumises par un apprenant est de 22, tandis que le maximum est de 288.
3.3. Mesure de la performance académique
La variable dépendante définie pour cette étude est le score obtenu par les apprenants à l’examen académique passé à l’issue des expérimentations, noté assessment score (AS), correspondant à une valeur réelle comprise entre 0 et 20. En outre, la distribution normale de l’AS pour l’expérimentation laisse apparaitre trois catégories qualitatives : bas (noté B, 0 ≤ B ≤ 6,7 ; effectif N = 22), moyen (6,7 < M ≤ 10,5 ; N = 27) et haut (H > 10.5 ; N = 36).
Par la suite, les différentes variables indépendantes sont évaluées aussi bien sur l’AS que sur les catégories d’AS (AScat). La section suivante définit des indicateurs numériques comme variables indépendantes et investigue leur corrélation avec les deux variables présentées ci-dessus (AS et AScat).
4. Analyse des indicateurs numériques
Nous étudions dans un premier temps, pour chaque apprenant, quatre indicateurs numériques :
- (1) le nombre de commandes soumises #soumissions ;
- (2) le pourcentage de commandes techniquement justes (i.e. exécutées sans erreur) %succès ;
- (3) le temps moyen écoulé entre deux commandes d’une même session de travail Δtemps ;
- (4) le nombre de commandes relatives à une recherche d’aide #aides.
Les trois premiers peuvent être trouvés dans d’autres travaux (Vihavainen, 2013), (Watson et al., 2013), ils permettent de quantifier la production des apprenants. Le dernier indicateur identifie les accès à l’aide, c’est-à-dire au manuel décrivant l’utilisation des commandes à maîtriser. Bien qu’il puisse être difficile de le calculer dans d’autres contextes (i.e. lorsque les ressources d’aide résident en dehors de l’EIAH), l’indicateur #aides est calculé dans cette expérimentation à partir de motifs connus tels que la commande man, qui fournit le manuel d’une commande, ou encore les arguments --help et -h qui permettent d’en obtenir un résumé. Le tableau 1 expose le coefficient de corrélation de Pearson entre les quatre indicateurs définis ci-dessus et l’AS1.
Tableau 1 • Corrélation entre indicateurs numériques et AS
Indicateur |
r |
Valeur-p |
#soumissions |
0,193 |
0,076 |
%succès |
0,248 |
0,022 |
Δtemps |
-0,127 |
0,247 |
#aides |
0,226 |
0,037 |
Les indicateurs #soumissions et Δtemps ne semblent pas corrélés avec l’AS, la valeur-p pour les deux indicateurs étant supérieure à 0,05. De plus, même si %succès et #aides présentent une corrélation faible significative avec l’AS, ils ne reflètent que grossièrement le comportement des étudiants pendant l’apprentissage pratique : %succès est un indicateur de production qui ne prend pas en compte la progression des apprenants dans leur apprentissage (i.e. la complexité des commandes exécutées), tandis que #aides ne reflète pas la raison pour laquelle les étudiants accèdent aux aides (i.e. après un échec, avant de tester une commande, etc.).
Ces indicateurs quantitatifs permettent de mettre en avant le fait que l’engagement des apprenants, défini en termes de nombre d’actions exécutées sur les ressources manipulées, n’est pas suffisant pour établir une corrélation significative avec leur performance académique. Ainsi, pour aller plus loin dans l’analyse du comportement des apprenants, nous explorons dans la section suivante comment ils ont réalisé leur TP en termes de séquences de commandes.
5. Analyse des motifs séquentiels d’actions
Nous avons appliqué une analyse de fouille de motifs séquentiels sur notre jeu de données, afin d’identifier des motifs répétitifs et significatifs d’actions menées par les apprenants pendant des TP et pour analyser si ces séquences sont liées aux deux variables dépendantes AS et AScat.
5.1. Nature des actions
Tout d’abord, nous proposons de définir une approche de fouille de motifs qui ne soit pas restreinte à notre contexte d’apprentissage. Afin de s’abstraire du contexte d’apprentissage du Shell, notre approche s’appuie sur l’analyse non pas des instructions elles-mêmes, mais de leur nature et du résultat de leur exécution. Nous définissons ainsi une action soumise par un apprenant sur une ressource par son type, ses paramètres et sa nature. Le type et les paramètres dépendent du contexte : par exemple, « mettre sous une tension de 12V un circuit RLC » est une action en électronique sur une ressource « circuit RLC » de type « mettre sous tension » et de paramètre « 12V ». Dans notre contexte, le type est le nom de la commande et les paramètres ses arguments. La nature, enfin, donne une information sémantique sur l’action, à travers sa relation avec celle qui a été exécutée précédemment.
Nous avons défini huit natures d’action exclusives : Sub_S, Sub_F, ReSub_S, ReSub_F, VarSub_S, VarSub_F, Help et NewHelp. Les natures Sub_* s’appliquent à une action dont le type est différent de la précédente, et qui est évaluée comme techniquement juste (Sub_S) ou fausse (Sub_F). Les natures ReSub_* désignent une action identique à la précédente (i.e. même type et paramètres), alors que les natures VarSub_* représentent une soumission de même type que la précédente mais dont les paramètres varient. Enfin, Help qualifie une action d’accès à une aide relative au type de l’action précédente, tandis que NewHelp indique l’accès à une aide sans lien avec l’action précédente. Par exemple, si la commande de référence est ls –al, la commande suivante rm sera de nature Sub_F (commande différente et techniquement fausse car rm nécessite au moins un argument), ls –al de nature ReSub_S, ls –alRu sera associée à VarSub_S tandis que man ls sera qualifiée par Help, et man rm par NewHelp.
Le haut niveau d’abstraction de ces natures d’action permet la fouille de données issues de VRL hétérogènes, et donc une réutilisation dans différents contextes de notre approche fondée sur l’analyse séquentielle d’actions. En effet, quel que soit le domaine d’apprentissage du VRL, l’EIAH associé propose de manière systématique des fonctionnalités permettant aux apprenants de valider la soumission d’actions sur les dispositifs virtuels ou physiques, et ainsi de progresser vers l’atteinte des objectifs d’apprentissage. La difficulté réside ici dans la capacité à pouvoir tracer les actions à un niveau de détail suffisamment élevé pour retrouver la valeur des paramètres qui sont associés aux actions ; l’acquisition de ces traces est facilitée dans les EIAH qui ont été spécifiquement conçus pour le VRL, mais elle peut s’avérer beaucoup plus délicate dans les EIAH s’appuyant sur des environnements virtuels complexes (Richter et al., 2011), des standards tels que SCORM, qui limitent considérablement les informations collectées (Sancristobal et al., 2010), ou des protocoles réseau tels que VNC offrant l’accès à des bureaux à distance (Leproux et al., 2013), (Lowe et al., 2009). D’autre part, concernant les natures relatives à l’accès à une aide, les VRL disposent souvent de leurs propres ressources d’assistance auxquelles l’accès peut être facilement détecté (Orduna et al., 2014). Le travail à réaliser, pour réutiliser notre approche d’analyse dans un contexte d’apprentissage particulier, consiste donc essentiellement à distinguer les actions ayant un impact sur les dispositifs manipulés de celles correspondant à une recherche d’assistance pour interagir avec ces dispositifs.
5.2. Motifs séquentiels d’actions
Les motifs significatifs ont été identifiés à partir de séquences d’actions de longueur 2 et 3, aucune séquence de longueur supérieure n’apparaissant chez suffisamment d’étudiants pour être exploitée. Les tests statistiques appliqués pour chaque séquence furent une analyse de la variance (i.e. one-way ANOVA) avec les catégories de performance AScat établies dans la section 3.3 et un test de corrélation de Pearson avec AS.
Les motifs présentés dans le tableau 2 sont ceux pour lesquels la valeur-p est inférieure à 0.05 dans au moins un des deux tests. Aussi, la colonne « tendance d’usage » reflète une relation d’ordre sur le nombre d’occurrences d’un motif entre les catégories d’étudiants, avec sa significativité donnée dans la colonne « valeur-p ANOVA ». Par exemple, les étudiants de haut niveau de performance (catégorie H), tout comme ceux de niveau moyen (M), ont appliqué le motif #2 plus souvent que les étudiants de faible niveau (B). En revanche, il n’existe pas de relation d’ordre significative entre les catégories de performance H et M pour ce motif.
Nous avons obtenu 13 motifs significatifs. La plupart de ces motifs présente une tendance d’usage significative entre les groupes de performance, ainsi qu’une corrélation significative faible (i.e. 0.1 < |r| < 0.3) ou moyenne (i.e. 0.3 < |r| < 0.5) avec l’AS. À titre d’exemple, la distribution du motif #1 est illustrée par la figure 3, qui fait apparaître une tendance d’usage significative chez le groupe de haut niveau de performance.
Tableau 2 • Analyse des motifs séquentiels d'actions
# |
Motif |
Tendanced’usage |
Valeur-pANOVA |
Coef.corr. |
Valeur-pcorr. |
1 |
Sub_S, VarSub_S |
H, M > B |
< 0.001 |
0,335 |
0,002 |
2 |
Help, ReSub_S |
H, M > B |
0,003 |
0,293 |
0,006 |
3 |
VarSub_S, NewHelp |
H, M > B |
0,007 |
0,210 |
0,053 |
4 |
VarSub_S, Sub_S |
H, M > B |
0,021 |
0,264 |
0,014 |
5 |
ReSub_S, NewHelp |
H, M > B |
0,026 |
0,361 |
< 0.001 |
6 |
VarSub_S, VarSub_S |
H, M > B |
0,031 |
0,203 |
0,062 |
7 |
Sub_S, VarSub_S, VarSub_S |
H, M > B |
0,002 |
0,286 |
0,008 |
8 |
VarSub_S, VarSub_S, Sub_S |
H, M > B |
0,003 |
0,294 |
0,006 |
9 |
Sub_S, VarSub_S, NewHelp |
H, M > B |
0,007 |
0,250 |
0,020 |
10 |
NewHelp, Sub_S, VarSub_S |
H, M > B |
0,009 |
0,243 |
0,025 |
11 |
Sub_S, ReSub_S, NewHelp |
H, M > B |
0,020 |
0,335 |
0,002 |
12 |
Sub_F, VarSub_F, VarSub_S |
B > H, M |
0,021 |
-0.217 |
0,046 |
13 |
Sub_S, NewHelp, ReSub_S |
H, M > B |
0,047 |
0,244 |
0,024 |

Figure 3 • Intervalles de confiance par catégorie de performance pour le motif Sub_S, VarSub_S
Il apparaît que la plupart de ces motifs sont utilisés plus fréquemment par des étudiants de haut ou moyen niveaux de performance que par ceux de faible niveau, et qu’ils sont positivement corrélés avec la performance académique (AS). Seul un motif d’action, le motif #12, est utilisé plus souvent par des étudiants du groupe B que par les autres ; dans ce motif, les étudiants soumettent successivement avec échec une action en modifiant ses paramètres au fur et à mesure, jusqu’à ce que l’action réussisse. De plus, aucun motif ne permet de distinguer clairement les étudiants de haut niveau de ceux de niveau moyen de performance.
D’autre part, nous remarquons que les motifs présentent certaines sémantiques communes illustrant le comportement des apprenants. Par exemple, les motifs des lignes 1, 6, 7, 8 et 9 reflètent l’enchaînement d’une action exécutée avec succès (i.e. Sub_S, ReSub_S ou VarSub_S) avec une action de paramètres différents, mais de même type, et exécutée avec succès (i.e. VarSub_S). Nous émettons ici l’hypothèse que ces motifs expriment la construction progressive d’une action complexe.
Les séquences d’actions s’apparentent ainsi à des approches mises en œuvre par les apprenants pour réaliser une tâche ou pour résoudre un problème. Certaines de ces approches se réfèrent à une méthodologie commune que nous désignons par stratégie. Dans la section suivante, nous définissons ces stratégies à partir des motifs du tableau 2 et analysons leur relation avec la performance académique.
5.3. Stratégies d’apprentissage
Les 13 motifs du tableau 2 font émerger un ensemble de 7 stratégies : confirmation, progression, succès-et-réflexion, réflexion-et-succès, échec-et-réflexion, tâtonnement et abandon. Confirmation exprime la soumission réussie de mêmes actions (i.e. commande et arguments inchangés), tandis que progression traduit une séquence d’actions réussies de même type, mais dont les paramètres varient au fur et à mesure. Succès-et-réflexion exprime le fait de réussir une soumission, puis d’accéder à l’aide d’un nouveau type d’action. À l’inverse, réflexion-et-succès reflète le fait de consulter l’aide d’un type d’action puis d’exécuter avec succès une action de ce type. Échec-et-réflexion illustre l’accès à l’aide du type d’une action après l’échec de son exécution. Tâtonnement expose le fait d’essayer au moins deux variantes d’une même action, sans résultat positif. Enfin, abandon correspond à l’exécution d’une action après l’échec de l’exécution d’une action de type différent.
Le tableau 3 fournit les expressions régulières que nous avons employées pour détecter les stratégies définies ci-dessus au sein des séquences d’actions réalisées par les apprenants. Par exemple, l’expression régulière associée à la stratégie progression correspond à des motifs de natures d’actions successives, exécutées avec succès, dont le type est le même mais dont les paramètres varient, et dont des accès à l’aide pour ce type d’action peuvent apparaître entre les différentes soumissions.
Tableau 3 • Expressions régulières des stratégies d'apprentissage
Stratégie |
Expression régulière |
Confirmation |
(?:Sub|ReSub|VarSub)_S,(?:Sub_S,)*(?:Sub_S) |
Progression |
(?:Sub|ReSub|VarSub)_S,(? :Help,)?VarSub_S |
Succès-et-réflexion |
(?:Sub|ReSub|VarSub)_S,(?:Help|NewHelp) |
Réflexion-et-succès |
(?:Help|NewHelp),(?:Sub|ReSub|VarSub)_S |
Échec-et-réflexion |
(?:Sub|ReSub|VarSub)_F,(?:Help|NewHelp) |
Tâtonnement |
(?:Sub|ReSub|VarSub)_F,(?:(?:ReSub|VarSub)_F,)*(?:ReSub|VarSub)_F |
Abandon |
(?:Sub|ReSub|VarSub)_F,(?:Help,)*(?:NewHelp,Sub_) |
5.4. Résultats
Nous avons analysé la relation entre chacune des stratégies et la performance académique en appliquant les mêmes tests que pour les motifs séquentiels étudiés à la section 5.2 (i.e. ANOVA pour AScat, et corrélation de Pearson pour AS). Le tableau 4 illustre les résultats de l’analyse des stratégies d’apprentissage. Les valeurs significatives apparaissent en gras, alors que les stratégies pour lesquelles au moins un résultat significatif a été calculé apparaissent en italique.
Tableau 4 • Analyse des stratégies d'apprentissage
Stratégie |
Tendance d’usage |
Valeur-pANOVA |
Coef.corr. |
Valeur-pcorr. |
Confirmation |
Ø |
0,745 |
0,108 |
0,321 |
Progression |
H, M > B |
0,001 |
0,294 |
0,006 |
Succès-et-réflexion |
H, M > B |
0,010 |
0,282 |
0,008 |
Réflexion-et-succès |
H, M > B |
0,015 |
0,242 |
0,026 |
Échec-et-réflexion |
Ø |
0,020 |
0,273 |
0,011 |
Tâtonnement |
Ø |
0,341 |
-0,050 |
0,670 |
Abandon |
Ø |
0,457 |
-0,004 |
0,968 |
Progression, succès-et-réflexion, réflexion-et-succès et échec-et-réflexion sont les stratégies qui présentent des résultats significatifs. Les trois premières nous permettent de regrouper les étudiants par catégorie de performance et semblent être un trait de comportement relatif aux apprenants de haut et moyen niveau de performance.
Aussi, nous détectons plus de stratégies positivement corrélées à l’AS : les résultats ne révèlent pas de comportements particuliers chez les étudiants de faible de niveau de performance. La stratégie tâtonnement ne présente pas de résultat significatif dans cette expérimentation. Cela peut être expliqué par les paramètres expérimentaux mentionnés précédemment (cf. section 3.1) : les apprenants étaient débutants en Informatique, et les activités pratiques réalisées suivaient une approche exploratoire, invitant ces apprenants à découvrir par eux-mêmes les commandes Shell. Dans cette forme d’apprentissage, faire de multiples essais pour découvrir et comprendre comment la machine réagit est un comportement attendu (de Jong et al., 2013), quel que soit le niveau de performance de l’étudiant.
Un autre résultat intéressant est celui de la stratégie abandon, qui ne semble pas liée à l’AS. Cette stratégie, employée par tous les apprenants, quel que soit leur niveau de performance, n’exprime pas le fait qu’ils échouent à réaliser une tâche particulière. Interrompre la réalisation d’une action peut s’expliquer par différentes hypothèses comme la curiosité ou la découverte d’actions non corrélées avec l’objectif pédagogique. Il ne semble donc pas pertinent de s’appuyer sur cette stratégie pour la prédiction de performance ou pour la prise de décision.
Cette étude sur les stratégies d’apprentissage révèle principalement des comportements d’apprenants de haut et moyen niveaux de performance qui sont positivement corrélés à l’AS. Avec la stratégie de progression, les étudiants de haut niveau de performance semblent décomposer leur problème en étapes de complexité croissante. Les trois autres stratégies utilisées plus fréquemment par les étudiants de haut et moyen niveaux sont liés à la réflexion à travers l’utilisation de l’aide ; ce résultat est cohérent avec ceux trouvés dans la section 4, où l’indicateur #help (i.e. le nombre d’accès à l’aide) est faiblement et positivement corrélé avec la performance académique.
6. Discussion
6.1. Nouvelles fonctionnalités issues des résultats
Tandis que les résultats de cette étude présentent un intérêt pour approfondir la compréhension des actions des apprenants pendant les sessions de travaux pratiques, la détection de ces comportements à la volée offre de nouvelles opportunités pour le support informatique à l’éducation. L’amélioration continue des EIAH, à partir des résultats expérimentaux dont ils sont le support, est un processus important de leur ingénierie (Tchounikine, 2009). Appliqué aux learning analytics, ce cycle d’amélioration permet de découvrir, à partir de l’analyse des traces du système, de nouveaux patrons de conception qui, une fois implantés au sein du système, permettront à leur tour de générer des données exploitables pour la recherche et l’amélioration de l’EIAH (Inventado et Scupelli, 2015).
À partir de nos résultats et en suivant cette méthodologie, nous avons intégré à la plateforme Lab4CE deux nouvelles fonctionnalités qui s’appuient sur deux patrons de conception différents : (i) le suivi du comportement de l’apprenant et (ii) un système de guidage d’aide intelligent. Nous les présentons ici à travers l’exposition de leurs objectifs, d’un scénario d’apprentissage pour illustrer leur utilisation, et de leurs conception et implémentation.
6.1.1. Suivi du comportement de l’apprenant
Objectifs. Pendant les sessions d’apprentissage, l’enseignant souhaite suivre l’engagement ou la progression des apprenants, et appréhender leur comportement face à l’activité, c’est-à-dire leur engagement comportemental (Fredricks et al., 2004), (Molinari et al., 2016). Cet outil vise ainsi à accompagner l’enseignant dans cette activité de suivi par la restitution des stratégies d’apprentissage mises en œuvre par les apprenants lors de la réalisation de tâches pratiques. D’autre part, dans ces situations d’apprentissage pratique, les apprenants doivent faire preuve de compétences d’autorégulation (Loyens et al., 2008), et les environnements qui favorisent leur développement sont bénéfiques à l’apprentissage (Mason, 2004). Restituer à l’apprenant son comportement pendant le TP vise donc également à améliorer sa capacité d’autorégulation.
Scénario. Pendant une session de travaux pratiques, l’outil de suivi du comportement offre à l’enseignant l’opportunité de consulter à tout moment et en temps réel l’évolution des différentes stratégies mises en œuvre par chacun des apprenants. Il est alors en mesure de prendre des décisions de remédiation individuelles (p. ex., conseiller la consultation d’une ressource d’aide, ou apporter directement son aide à un apprenant mettant en œuvre la stratégie de tâtonnement) et/ou collectives (p. ex., proposer la réalisation d’une tâche moins complexe lorsqu’un nombre significatif d’apprenants se trouvent dans cette stratégie de tâtonnement). Du point de vue des apprenants, cet outil leur permet de visualiser l’évolution des stratégies qu’ils appliquent au fur et à mesure de leur apprentissage. Ils peuvent alors développer leurs compétences d’autorégulation en adaptant leur comportement lorsqu’ils se trouvent dans des stratégies qui ne mènent pas à une « bonne » performance académique. Cet outil offre également aux apprenants la possibilité de situer et comparer leur comportement au regard du comportement global de la classe, et ainsi de s’engager davantage dans les processus de réflexion et d’autorégulation.
Conception et développement. Illustrée sur la figure 4, l’interface de l’outil de suivi des stratégies permet de filtrer l’affichage selon (i) les stratégies, (ii) les utilisateurs, ou (iii) les sessions de travail. Dans le cas où toute l’expérience ou la session courante est sélectionnée, la visualisation se met à jour au fur et à mesure de l’apparition de stratégies chez l’(les) apprenant(s) sélectionné(s). Pour chaque apprenant, la visualisation fait apparaître ses stratégies. Sur la figure 4, seules les stratégies Succès-puis-réflexion (en vert) et réflexion-puis-succès (en violet) ont été sélectionnées. Les zones noires sont les intervalles de temps ou aucune de ces deux stratégies n’a été détectée.

Figure 4 • Suivi du comportement des apprenants en temps réel
6.1.2. Système de guidage d’aide intelligent
Objectifs. Les systèmes de tutorat Intelligent (Intelligent Tutoring System, ITS) ont pour objectifs « d’engager les apprenants dans des activités de raisonnement soutenu et d’interagir avec eux en s’appuyant sur une compréhension profonde de leur comportement » (Corbett et al., 1997). Nous souhaitons ici soutenir la réflexion par la conception d’un système de guidage d’aide intelligent fondé sur les stratégies d’apprentissage. En particulier, ce système a pour vocation de guider les apprenants qui appliquent des stratégies ne menant pas, d’après les résultats de la section 5, à des performances académiques satisfaisantes.
Scénario. À partir des stratégies identifiées pendant l’activité pratique, notre système d’aide peut fournir à l’apprenant un feedback adapté à son comportement pour l’engager dans un processus de réflexion, en lui proposant la consultation de ressources d’aide ou en l’invitant à demander de l’aide auprès d’un pair. En effet, notre étude a montré que les apprenants consultant les ressources d’aide ont tendance à obtenir des performances académiques plus élevées que ceux ignorant ces aides. Lorsqu’un apprenant se trouve dans une situation d’échec potentiel, c’est-à-dire lorsqu’il applique une stratégie n’étant pas identifiée comme menant à des performances satisfaisantes, le système de guidage lui suggère de modifier sa stratégie d’apprentissage en accédant à des aides numériques fournies par le système, ou en interagissant avec un utilisateur ayant déjà accompli avec succès la tâche demandée.
Conception et développement. Notre système, illustré sur la figure 5, fournit des recommandations, sous la forme de messages qui apparaissent au premier plan, superposés au terminal de l’apprenant, lorsque celui-ci rencontre une difficulté pour réaliser la tâche demandée. Par exemple, lorsque la détection de la stratégie d’essai/erreur se prolonge dans le temps, le système recommande l’utilisation du manuel de la commande, sans pour autant faire l’action à la place de l’apprenant. Dans le cas où l’apprenant aurait déjà effectué cette opération, sans toutefois surmonter la difficulté rencontrée, l’outil de guidage recommande alors un pair sélectionné à partir de trois informations : (i) les stratégies appliquées, (ii) les mesures de performance, et (iii) la charge d’aide des utilisateurs, pour éviter de recommander un pair qui serait déjà en train d’aider un autre apprenant.
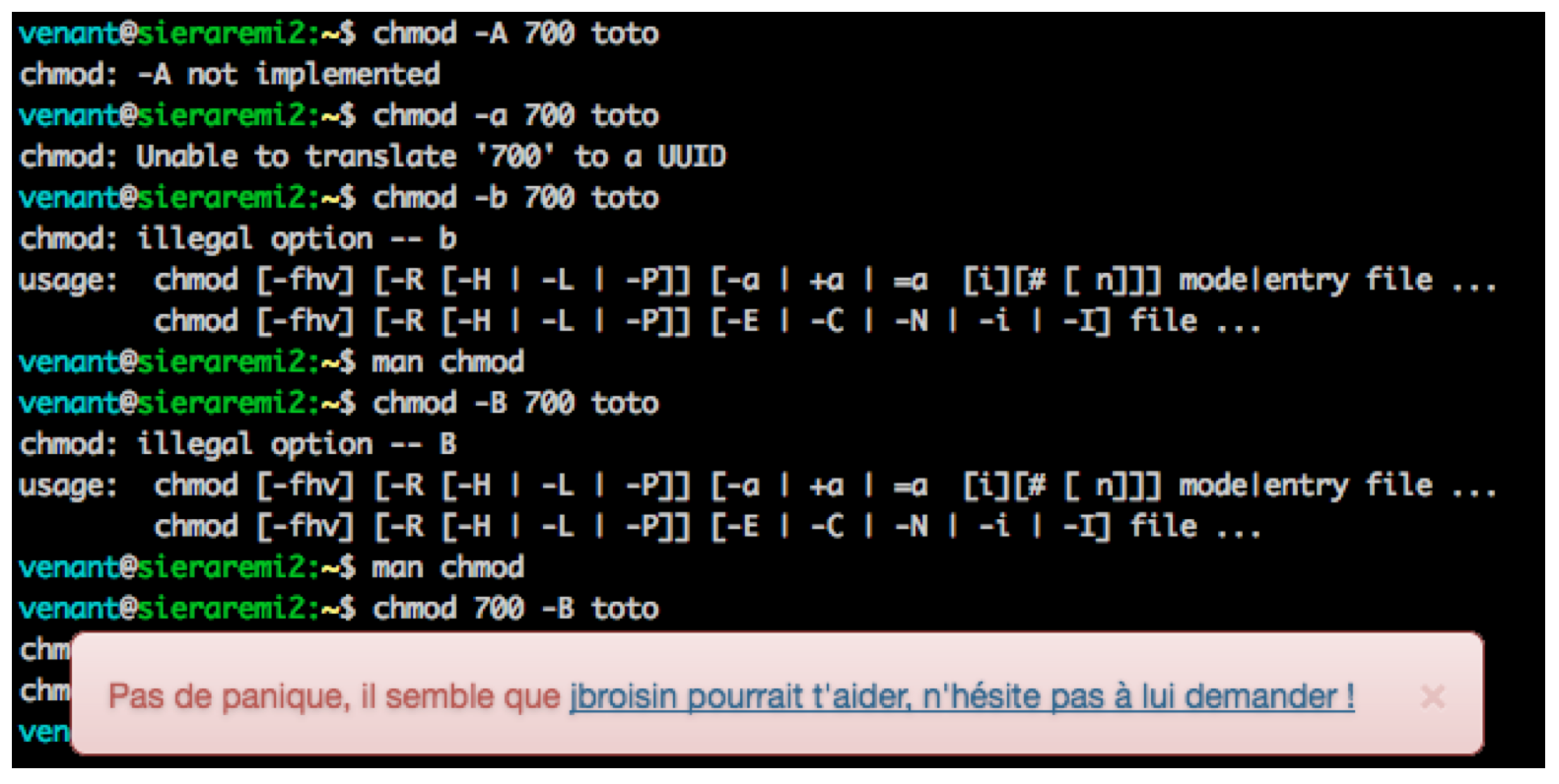
Figure 5 • Système de
guidage d’aide orienté stratégies d'apprentissage
Cet outil permet ainsi de guider les apprenants selon les stratégies qu’ils mettent en œuvre, et promeut les interactions sociales entre apprenants.
6.2. Travaux connexes
Dans l’enseignement de l’Informatique, plusieurs études ont été menées pour détecter quelles caractéristiques du profil des apprenants peuvent prédire leur succès ou leur échec dans une activité d’apprentissage donnée. Ces caractéristiques comprennent des informations obtenues avant l’activité telles que des indicateurs de personnalité, les résultats et expériences académiques passés (Hostetler, 1983), (Wilson et Shrock, 2001), ou encore les attentes des apprenants (Rountree et al., 2004). La considération de tels indicateurs est utile, par exemple, pour identifier les apprenants qui pourraient nécessiter plus d’attention et pour lesquels un encadrement particulier serait bénéfique. Mais cette approche limite le profil de l’apprenant à des données qui n’évoluent pas dans le temps : l’activité d’apprentissage est perçue comme un facteur immuable de la réussite de l’apprenant. Au contraire, notre approche est dynamique puisqu’elle s’appuie sur la fouille des données transcrivant le comportement des apprenants pendant l’activité elle-même, offrant ainsi de nouvelles perspectives pour découvrir de nouveaux facteurs d’influence, mais aussi pour appliquer différentes remédiations à partir du comportement des apprenants.
D’autres recherches ont adopté une approche similaire à la nôtre. Par exemple, Blikstein (Blikstein, 2011) et Watson (Watson et al., 2013) s’appuient sur l’évolution des codes sources des étudiants pour analyser l’impact d’indicateurs tels que la taille du code, le nombre de compilations ou le temps écoulé entre deux compilations sur la réussite des candidats au test post-expérimentaux. De la même manière, Vihavainen (Vihavainen, 2013) présente une étude quantitative dans un cours d’introduction à la programmation. Différentes versions des codes sources sont analysées au fur et à mesure des TP pour en extraire des facteurs potentiels de prédiction du succès tels que l’indentation du code, le masquage de variables ou les résultats des compilations. Dans ces travaux, les indicateurs sont fortement couplés à l’activité de programmation.
Dans les systèmes LaboRem (Luthon et Larroque, 2015) ou Ironmaking (Babich et Mavrommatis, 2009) dédiés à l’apprentissage de la physique, les apprenants doivent saisir les valeurs de divers paramètres sur différents appareils avant de lancer une simulation dont les résultats permettent d’analyser différents phénomènes physiques. Les notions d’action et de variation de paramètres introduites dans notre étude s’appliquent également dans ce contexte spécifique de la physique, offrant ainsi la possibilité d’analyser le comportement des apprenants en réutilisant les natures d’actions et les stratégies d’apprentissage que nous avons définies. Plus généralement, notre approche d’analyse peut être appliquée dès lors que l’EIAH associé au VRL intègre des capacités de collecte des traces traduisant les interactions entre les apprenants et les dispositifs qu’ils manipulent, d’une part, et les accès à des ressources d’aide, d’autre part (voir section 5.2). Les stratégies d’apprentissage introduites dans cette étude pourraient ainsi permettre de suivre le comportement des apprenants de façon homogène dans l’apprentissage de différentes disciplines, en particulier celles liées aux STEM (Science, Technology, Engineering, and Mathematics), qui intègrent une part importante de sessions pratiques dans leurs curriculums. Si l’analyse par les stratégies d’apprentissage dans d’autres matières s’avérait concluante, elle ouvrirait la voie à une consolidation et une généralisation des résultats que nous avons obtenus dans notre contexte spécifique.
Avec l’augmentation constante des traces d’apprentissage qu’un système est capable de collecter, et ce à un niveau de détails de plus en plus élevé, l’application de méthodes de fouille de données gagne en importance. En particulier, la fouille de motifs séquentiels que nous avons appliquée, utilisée pour déterminer les motifs les plus fréquents dans un ensemble de séquences d’actions (Agrawal et Srikant, 1995), devient une approche courante pour mieux comprendre le comportement des apprenants, particulièrement dans le domaine des MOOC (Massive Open On-line Courses). Proches de nos travaux, Wen et Rosé (Wen et Rosé, 2014) s’appuient sur un modèle de détection de N-gram appliqué à deux MOOC de Coursera pour extraire des affinités d’activités entre étudiants (p. ex., « parcourir le cours », « tâches et forum »), afin de les regrouper, et finalement d’étudier les potentielles différences d’activités entre les étudiants de faible niveau de performance et ceux de haut niveau. Toujours à partir d’un jeu de données de MOOC proposés par Coursera, A. Anderson, Huttenlocher, Kleinberg et Leskovec (Anderson et al., 2014) étudient les motifs d’actions à un plus haut niveau d’abstraction pour faire la distinction entre faible et haut niveau de réussite du MOOC. Les auteurs proposent une taxonomie exclusive de comportements généraux sur un MOOC (i.e. lecteur ou collecteur, solutionneur, touche-à-tout et spectateur), fondée sur l’observation du nombre de devoirs et de lectures accomplis par les utilisateurs. Les auteurs explorent ensuite la distribution des apprenants selon cette taxonomie à travers différentes dimensions telles que l’engagement, les durées d’interaction ou les notes obtenues. Dans cette recherche, la fouille de motifs séquentiels permet aux auteurs de conclure, par exemple, que la population des étudiants de haut niveau de performance est composée principalement de deux sous-groupes : les solutionneurs, qui réalisent les devoirs sans réaliser de lecture (ou très peu), et les touche-à-tout, qui lisent les supports, regardent les vidéos, finissent les quizz, et font ensuite les devoirs notés.
En suivant une méthodologie similaire, Kinnebrew, Loretz et Biswas (Kinnebrew et al. 2013) suggèrent un algorithme fondé sur une combinaison de techniques de fouille de motifs pour différencier deux groupes d’étudiants à travers la fréquence de leurs motifs d’actions. Les auteurs visent également l’identification et la comparaison entre étudiants de haut niveau et étudiants de faible niveau de réussite pendant des phases d’apprentissage productives et contre-productives. Leur méthodologie comprend (i) un algorithme fondé sur Pex-SPAM (Ho et al., 2005) pour identifier un ensemble de motifs, et (ii) l’utilisation d’algorithmes de représentation linéaire par parties pour identifier les phases productives et contre-productives. Les auteurs identifient ainsi certains motifs qui sont plus utilisés par un groupe d’apprenants que par l’autre, selon la phase d’apprentissage. Bien qu’une représentation abstraite d’actions soit proposée, celle-ci reste dédiée aux MOOC et ne peut être appliquée à un VRL. Cependant, cette approche par abstraction est comparable à la nôtre, puisque, si nous utilisons des expressions régulières pour détecter les stratégies d’apprentissage, eux ajoutent des suffixes spécifiques à leur alphabet pour exprimer la multiplicité des occurrences et la pertinence/non-pertinence des actions, afin d’identifier les relations entre deux actions consécutives. Toutefois, leur étude de la relation entre motifs et performance n’est applicable que pour une performance mesurée par une métrique scalaire et régulièrement évaluée par l’environnement.
7. Conclusion
L’étude présentée dans cet article, fondée sur l’analyse de données collectées dans un contexte d’apprentissage réel, visait à appréhender les liens entre le comportement des apprenants en situation de travail pratique et leur performance académique. Nous avons adopté une approche exploratoire par la fouille de motifs séquentiels pour identifier des stratégies d’apprentissage corrélées à la performance. Celles dont la corrélation est la plus importante sont (i) la progression, lorsqu’un apprenant effectue étape par étape plusieurs actions de même nature mais de plus en plus complexes, et (ii) [resp. (iii)] la réflexion de l’apprenant par la consultation d’une aide avant [resp. après] l’exécution d’une action. Ces stratégies semblent être représentatives des étudiants de haut et moyen niveaux de performance. Toutefois, cette étude ne concerne que les interactions entre les apprenants et les ressources qu’ils manipulent pour réaliser l’activité pratique ; des travaux sont en cours pour étendre notre modèle d’analyse aux autres données collectées par Lab4CE, afin d’investiguer plus en profondeur le comportement des apprenants.
Si nous avons étudié ici les liens de corrélation entre comportement et performance des apprenants, nous devons approfondir notre analyse afin d’étudier leurs liens de causalité, mais également afin de proposer un modèle prédictif dans le but de prévenir les échecs des étudiants. Aussi, les stratégies d’apprentissage traduisant le comportement des étudiants ont été définies de manière ad hoc ; leur formalisation à partir des recherches issues du domaine des Sciences de l’Éducation permettrait de les doter d’une définition pérenne et de fournir une base plus solide pour l’étude comportementale des apprenants dans diverses situations pédagogiques. Le système de guidage d’aide présenté dans cet article a pour but de motiver chez l’apprenant l’application de stratégies d’apprentissage particulières. Cet outil pourrait donc être utilisé dans un cadre expérimental pour observer si la mise en œuvre d’une stratégie induit une variation de la performance, dans l’objectif d’étudier le lien de causalité entre ces deux variables. Toutefois, nous devons d’abord analyser l’impact de cet outil sur le comportement des étudiants, tout comme nous devons valider l’outil de visualisation des stratégies dédié aux enseignants comme aux apprenants.
Enfin, Lab4CE intègre également des fonctionnalités destinées au travail coopératif et collaboratif. La mise en œuvre d’activités collectives permettrait d’étudier de nouvelles questions de recherche sur les comportements des apprenants en situation de travaux pratiques, dans un contexte socioconstructiviste. Étudier l’influence des stratégies sur les interactions entre apprenants, ou l’évolution individuelle et collective de ces stratégies au fur et à mesure de l’apprentissage, sont autant de perspectives de recherche que nous souhaitons aborder à l’avenir.
 À
propos des auteurs
À
propos des auteurs
Rémi Venant est Attaché Temporaire d'enseignement et de Recherche à l'Université Toulouse 3 Paul Sabatier. Ses travaux de recherche portent l’analyse des apprentissages (learning analytics), la fouille de données et la création de modèles prédictifs pour l'éducation, et sur la conception et l'évaluation d'environnements informatiques pour l'apprentissage pratique.
Adresse : Université Toulouse III Paul Sabatier, 118 Route de Narbonne, F-31062 TOULOUSE CEDEX 9
Courriel : remi.venant@irit.fr
Toile : https://www.irit.fr/~Remi.Venant
Kshitij Sharma est actuellement chercheur post-doctoral à la Norwegian University of Science and Technology (NTNU), après avoir été chercheur post-doctoral à l'Ecole Polytechnique Fédérale de Lausanne (EPFL) et à l'Université de Lausanne (Unil). Ses travaux de recherche portent sur l'analyse du comportement humain dans l'apprentissage, et notamment par l'exploitation de l'oculométrie (eye-tracking).
Adresse : NTNU, NO-7491 Trondheim, Norway
Courriel : kshitij.sharma@ntnu.no
Toile : https://www.ntnu.edu/employees/kshitij.sharma
Philippe Vidal est Professeur d’Informatique à l’Université Paul Sabatier Toulouse 3. Il a été chef du département Informatique de l’IUT A de Toulouse pendant six ans avant de co-diriger l’Ecole Doctorale Mathématiques, Informatique et Télécommunications de Toulouse de 2013 à 2014.
Adresse : Université Toulouse III Paul Sabatier, 118 Route de Narbonne, F-31062 TOULOUSE CEDEX 9
Courriel : philippe.vidal@irit.fr
Toile : https://www.irit.fr/~Philippe.Vidal
Ancien instituteur primaire, Pierre Dillenbourg obtient un master en Sciences de l’Éducation (Université de Mons, Belgique). Il commence à Mons ses recherches sur les technologies de formation en 1984 et obtient ensuite une thèse en informatique de l’Université de Lancaster (UK) dans le domaine des applications éducatives de l’intelligence artificielle. Il a été Maître d’Enseignement et de Recherche à l’Université de Genève. Il rejoint l'EPFL en 2012. Il fut le directeur académique du Centre pour l'Education à l'Ere Digitale (CEDE) qui met en œuvre la stratégie MOOC de l'EPFL. Il est actuellement professeur ordinaire en technologies de formation aux sein de la faculté ‘Informatique et Communications’ et dirige le laboratoire d'ergonomie éducative (CHILI). Son livre Orchestration Graphs propose un langage semi-formel pour le design didactique. Il a récemment créé le 'Swiss EdTech Collider', un incubateur qui rassemble 60 start-ups dans le domaine des technologies éducatives.
Adresse : EPFL IC IINFCOM CHILI, RLC D1 740 (Rolex Learning Center), Station 20, CH-1015 Lausanne
Courriel : pierre.dillenbourg@epfl.ch
Toile : https://people.epfl.ch/pierre.dillenbourg
Julien Broisin est Maître de Conférences en Informatique à l’Université Paul Sabatier Toulouse 3. Il est le coordinateur du domaine d’application « e-éducation » de l’Institut de Recherche en Informatique de Toulouse (IRIT). Ses travaux de recherche portent sur l’analyse des apprentissages (i.e. learning analytics) pour l’adaptation et la personnalisation des processus d’apprentissage, l’apprentissage exploratoire à travers la conception et l’évaluation de laboratoires distants (en particulier dans le contexte de l’apprentissage de l’Informatique), et l’apprentissage actif à travers la conception de systèmes d’évaluation formative.
Adresse : Université Toulouse III Paul Sabatier, 118 Route de Narbonne, F-31062 TOULOUSE CEDEX 9
Courriel : julien.broisin@irit.fr
Toile : https://www.irit.fr/~Julien.Broisin
REFERENCES
Agrawal, R. et Srikant, R. (1995). Mining sequential patterns. Dans Proceedings of the Eleventh International Conference on Data Engineering (ICDE'95) (p. 3–14). Disponible en ligne : https://pdfs.semanticscholar.org/d6a0/e0b04a020ac6422b98b8e63027a6178060fd.pdf
Aleven, V., Mclaren, B., Roll, I. et Koedinger, K. (2006). Toward meta-cognitive tutoring: A model of help seeking with a Cognitive Tutor. International Journal of Artificial Intelligence in Education, 16(2), 101–128.
Anderson, A., Huttenlocher, D., Kleinberg, J. et Leskovec, J. (2014). Engaging with massive online courses. Dans Proceedings of the 23rd international World Wide Web Conference (p. 687–698). https://doi.org/10.1145/2566486.2568042
Babich, A. et Mavrommatis, K. T. (2009). Teaching of complex technological processes using simulations. International Journal of Engineering Education, 25(2), 209–220.
Blikstein, P. (2011). Using learning analytics to assess students' behavior in open-ended programming tasks. Dans Proceedings of the 1st international conference on Learning Analytics and Knowledge (LAK 2011) (p. 110–116). https://doi.org/10.1145/2090116.2090132
Broisin, J., Venant, R. et Vidal, P. (2017). Lab4CE: A remote laboratory for computer education. International Journal of Artificial Intelligence in Education, 27, (154–180). https://doi.org/10.1007/s40593-015-0079-3
Bunderson, E. D. et Christensen, M. E. (1995). An analysis of retention problems for female students in university computer science programs. Journal of Research on Computing in Education, 28(1), 1–18. https://doi.org/10.1080/08886504.1995.10782148
Corbett, A. T., Koedinger, K. R. et Anderson, J. R. (1997). Intelligent tutoring systems. Dans Handbook of Human-Computer Interaction (chap. 5, p. 849–874).
Corter, J. E., Nickerson, J. V., Esche, S. K. et Chassapis, C. (2004). Remote versus hands-on labs: A comparative study. Dans Proceedings of the 34th Annual Frontiers in Education (p. 17–21). IEEE. https://doi.org/10.1109/FIE.2004.1408586
de Jong, T., Linn, M. C. et Zacharia, Z. C. (2013). Physical and Virtual Laboratories in Science and Engineering Education. Science, 340(6130), 305–308. https://doi.org/10.1126/science.1230579
Fredricks, J. A., Blumenfeld, P. C. et Paris, A. H. (2004). School engagement: Potential of the concept, state of the evidence. Review of Educational Research, 74(1), 59–109.
Gutierrez-Santos, S., Mavrikis, M. et Magoulas, G. D. (2010). Layered development and evaluation for intelligent support in exploratory environments: the case of microworlds. Dans V. Aleven, J. Kay et J. Mostow (dir.), Intelligent Tutoring Systems (ITS 2010) (p. 105–114). Berlin, Allemagne : Springer. https://doi.org/10.1007/978-3-642-13388-6_15
Hecking, T., Manske, S., Bollen, L., Govaerts, S., Vozniuk, A. et Hoppe, H. U. (2014). A Flexible and Extendable Learning Analytics Infrastructure. Dans Proceedings of the International Conference on Web-Based Learning (p. 123–132). Springer International. https://doi.org/10.1007/978-3-319-09635-3_13
Ho, J., Lukov, L. et Chawla, S. (2005). Sequential pattern mining with constraints on large protein databases. Dans Proceedings of the 12th International Conference Management of Data (COMAD) (p. 89–100).
Hostetler, T. R. (1983). Predicting student success in an introductory programming course. ACM SIGCSE Bulletin, 15(3), 40–43. https://doi.org/10.1145/382188.382571
Inventado, P. S. et Scupelli, P. (2015). Data-driven design pattern production: a case study on the ASSISTments online learning system. Dans Proceedings of the 20th European Conference on Pattern Languages of Programs (p. 14:1–14:13). New York, NY : ACM.
Kinnebrew, J. S., Loretz, K. M. et Biswas, G. (2013). A contextualized, differential sequence mining method to derive students' learning behavior patterns. Journal of Educational Data Mining, 5(1), 190–219.
Leproux, P., Barataud, D., Bailly, S. et Nieto, R. (2013). Présentation et analyse des nouveaux usages pour la conduite de travaux pratiques à distance. Interfaces Numériques, 2(3), 453–467.
Lowe, D. B., Berry, C., Murray, S. et Lindsay, E. (2009). Adapting a remote laboratory architecture to support collaboration and supervision. International Journal of Online Engineering, 5, 51–56. https://doi.org/10.3991/ijoe.v5s1.932
Loyens, S. M., Magda, J. et Rikers, R. M. (2008). Self-directed learning in problem-based learning and its relationships with self-regulated learning. Educational Psychology Review, 20(4), 411–427.
Luthon, F. et Larroque, B. (2015). LaboREM—A remote laboratory for game-like training in electronics. IEEE Transactions on Learning Technologies, 8(3), 311–321. https://doi.org/10.1109/TLT.2014.2386337
Ma, J. et Nickerson, J. V. (2006). Hands-on, simulated, and remote laboratories: A comparative literature review. ACM Computing Surveys (CSUR), 38(3). Disponible en ligne : https://web.stevens.edu/jnickerson/ACMComputingSurveys2006MaNickerson.pdf
Mason, L. H. (2004). Explicit self-regulated strategy development versus reciprocal questioning: Effects on expository reading comprehension among struggling readers. Journal of Educational Psychology, 96(2).
Molinari, G., Poellhuber, B., Heutte, J., Lavoué, É., Sutter Widmer, D. et Caron, P.-A. (2016). L’engagement et la persistance dans les dispositifs de formation en ligne : regards croisés. Distances et médiations des savoirs, 13. Disponible en ligne : https://journals.openedition.org/dms/1332
Orduna, P., Almeida, A., Lopez-de-Ipina, D. et Garcia-Zubia, J. (2014). Learning Analytics on federated remote laboratories: Tips and techniques. Dans Proceedings of the Global Engineering Education Conference (EDUCON) (p. 299–305). IEEE. https://doi.org/10.1109/EDUCON.2014.6826107
Richter, T., Boehringer, D. et Jeschke, S. (2011). LiLa: A european project on networked experiments. Dans S. Jeschke, I. Isenhardt et K. Henning (dir.), Automation, Communication and Cybernetics in Science and Engineering (p. 307–317). Berlin, Allemagne : Springer. https://doi.org/10.1007/978-3-642-16208-4_27
Rountree, N., Rountree, J., Robins, A. et Hannah, R. (2004). Interacting factors that predict success and failure in a CS1 course. ACM SIGCSE Bulletin, 36(4), 101–104.
Sancristobal, E., Castro, M., Harward, J., Baley, P., DeLong, K. et Hardison, J. (2010). Integration view of Web Labs and Learning Management Systems. Dans Proceedings of the Global Engineering Education Conference (EDUCON) (p. 1409–1417). IEEE. https://doi.org/10.1109/EDUCON.2010.5492363
Tchounikine, P. (2009). Précis de recherche en Ingénierie des EIAH. Disponible en ligne : https://hal.archives-ouvertes.fr/hal-00413694
Venant, R., Vidal, P. et Broisin, J. (2016). Evaluation of learner performance during practical activities: An experimentation in computer education. Dans Proceedings of the 16th International Conference on Advanced Learning Technologies (ICALT) (p. 237–241). IEEE. https://doi.org/10.1109/ICALT.2016.60
Venant, R., Vidal, P. et Broisin, J. (2017). A help management system to support peer instruction in remote laboratories. Dans Proceedings of the 17th International Conference on Advanced Learning Technologies (ICALT) (p. 430–432). IEEE. https://doi.org/10.1109/ICALT.2017.123
Vihavainen, A. (2013). Predicting Students' Performance in an introductory programming course using data from students' own programming process. Dans Proceedings of the 13th International Conference on Advanced Learning Technologies (ICALT) (p. 498–499). IEEE. https://doi.org/10.1109/ICALT.2013.161
Watson, C., Li, F. W. B. et Godwin, J. L. (2013). Predicting performance in an introductory programming course by logging and analyzing student programming behavior. Dans Proceedings of the 13th International Conference on Advanced Learning Technologies (ICALT) (p. 319–323). IEEE.
Wen, M. et Rosé, C. P. (2014). Identifying Latent Study Habits by Mining Learner Behavior Patterns in Massive Open Online Courses. Dans Proceedings of the 23rd ACM International Conference on Information and Knowledge Management (p. 1983–1986). New York, NY : ACM. https://doi.org/10.1145/2661829.2662033
Wilson, B. C. et Shrock, S. (2001). Contributing to success in an introductory computer science course - a study of twelve factors. ACM SIGCSE Bulletin, 33(1), 184–188. https://doi.org/10.1145/366413.364581
Workman, M. (2004). Performance and perceived effectiveness in computer-based and computer-aided education: Do cognitive styles make a difference? Computers in Human Behavior, 20(4), 517–534. https://doi.org/10.1016/j.chb.2003.10.003
1 r : coefficient de corrélation, valeur réelle entre -1 et 1 (0 signifie une absence de corrélation entre les deux variables, -1 / 1 une corrélation négative/positive forte). La valeur-p exprime la probabilité, sous l’hypothèse nulle, d’obtenir un résultat au moins aussi « extrême » que celui observé. Nous considérons ici qu’une valeur-p inférieure à 0.05 implique un résultat statistique significatif (i.e. la présomption contre l’hypothèse nulle est suffisante pour que celle-ci soit rejetée).
Rémi VENANT, Kshitij SHARMA, Philippe VIDAL, Pierre DILLENBOURG, Julien BROISIN, Étude du comportement des apprenants dans les travaux pratiques et de sa corrélation avec la performance académique, Revue STICEF, Volume 25, numéro 1, 2018, DOI:10.23709/sticef.25.1.6, ISSN : 1764-7223, mis en ligne le 08/02/2019, http://sticef.org
© Revue Sciences et Technologies de l´Information et de la Communication pour l´Éducation et la Formation